
Теорія ігор досліджує дії гравців та ймовірності, вводячи змішані стратегії для більш складного аналізу. Рівновага Неша має вирішальне значення для оптимальних стратегій в іграх, що включають випадковість.

Удосконалена нейромережева архітектура CPTR поєднує кодер ViT з декодером Transformer для створення підписів до зображень, покращуючи попередні моделі. Модель CPTR використовує ViT для кодування зображень і Transformer для декодування підписів, що підвищує продуктивність підписів до зображень.
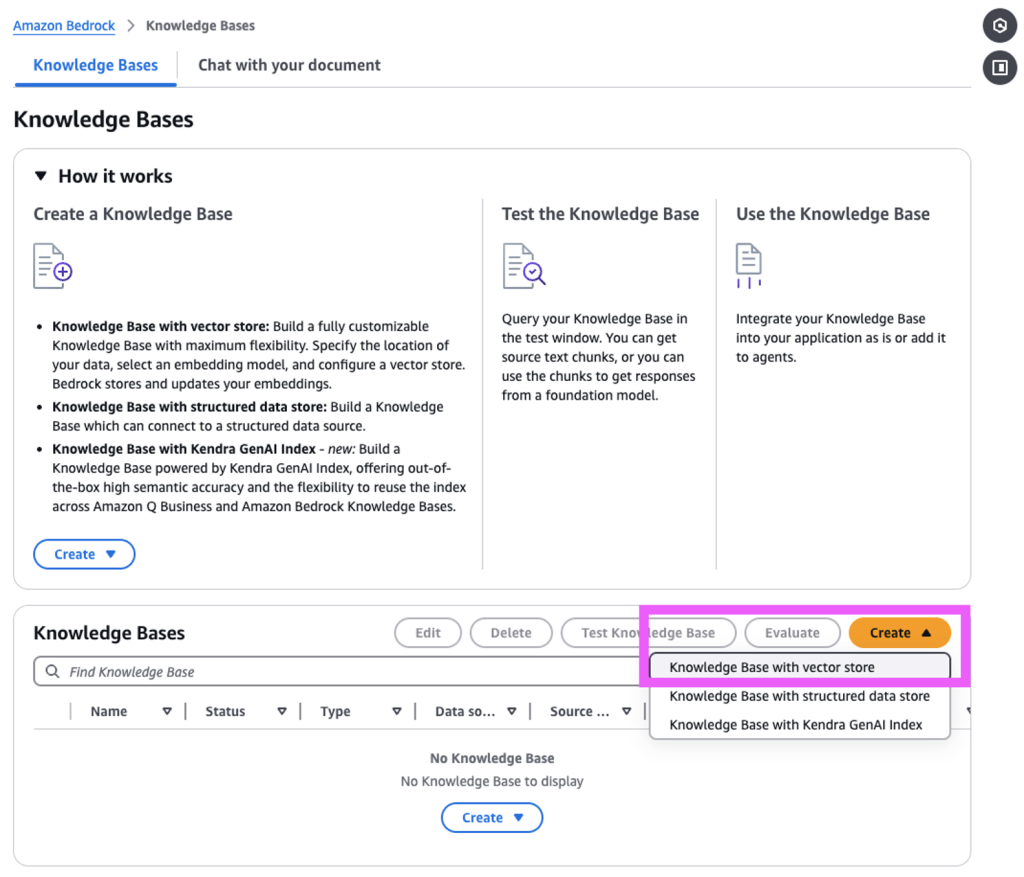
Amazon Web Services (AWS) запускає GraphRAG в Amazon Bedrock Knowledge Bases, покращуючи додатки генеративного ШІ за допомогою графічних даних для більш повних відповідей. GraphRAG автоматично створює графіки, щоб підвищити точність і релевантність діалогів ШІ, забезпечуючи більш корисну і надійну взаємодію.

Дослідники Массачусетського технологічного інституту та NVIDIA розробили новий фреймворк, який дозволяє користувачам коригувати поведінку роботів у режимі реального часу без перенавчання. Цей інтуїтивно зрозумілий метод перевершує альтернативні на 21%, потенційно дозволяючи неспеціалістам керувати роботами, навченими на заводі, у виконанні домашніх завдань.

Verisk є піонером генеративного штучного інтелекту в страхуванні завдяки Mozart, скорочуючи час прийняття змін з декількох днів до декількох хвилин за допомогою Amazon Bedrock. Компаньйон на основі ШІ порівнює юридичні документи, надаючи суттєві відмінності у зручному для сприйняття форматі.
Аманда Гудолл закликає наступного лідера NHS Англії розширити можливості найкращих лікарів для покращення результатів охорони здоров'я. Клініки Майо та Клівленда досягли успіху під керівництвом лікарів, підкреслюючи переваги лідерства лікарів.

Налаштування конвеєра навчання виявлення об'єктів за допомогою репозиторіїв Ultralytics, YOLOx, DAMO-YOLO, RT-DETR та D-FINE для реалізації моделі реального часу SoTA. Зосередьтеся на обробці наборів даних, доповненнях і перетвореннях для отримання оптимальних результатів.

Модний ентузіаст використовує штучний інтелект, щоб перетворити хаотичну шафу на кураторське вбрання за допомогою багатокрокових налаштувань GPT, створивши Pico Glitter. Модний радник на основі GPT допомагає керувати гардеробом, надаючи узгоджені пропозиції щодо вбрання на основі правил особистого стилю користувача та конкретних речей, якими він володіє.

BBC News планує використовувати штучний інтелект для персоналізованого контенту, щоб адаптуватися до мінливих звичок споживання новин, орієнтуючись на аудиторію віком до 25 років на таких платформах, як TikTok. Головний виконавчий директор Дебора Тернесс прагне прискорити зростання охоплення аудиторії, створивши новий відділ, зосереджений на інноваціях та штучному інтелекті.
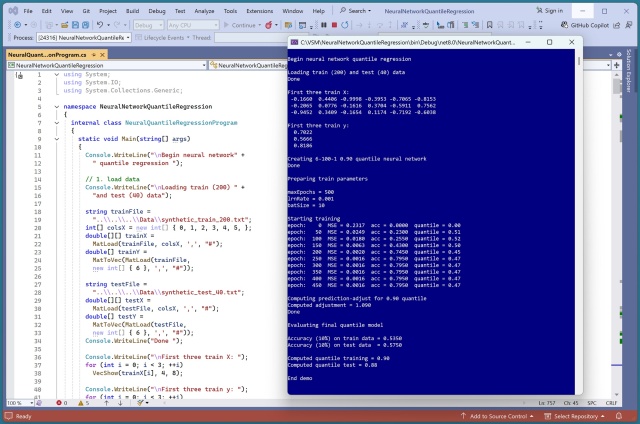
Реалізація нейромережевої квантильної регресії в PyTorch була складним завданням. Вивчення C# для цієї ж задачі виявилося ще складнішим через проблеми з калібруванням.

Генеративний ШІ революціонізує роздрібну торгівлю, покращуючи обслуговування клієнтів, оптимізуючи управління продуктами та стимулюючи персоналізований маркетинг завдяки адаптивній взаємодії та автоматизації. Ритейлери використовують цю технологію, щоб задовольнити потреби клієнтів, підвищити ефективність і залишатися конкурентоспроможними на цифровому ринку.

Тепер учасники GeForce NOW можуть полювати на монстрів у Monster Hunter Wilds і зануритися в приголомшливі пригоди Split Fiction. Насолоджуйтесь високопродуктивними іграми в хмарі з технологіями NVIDIA.

Дослідники NVIDIA нагороджені за новаторський внесок у кіноіндустрію. Ziva VFX, Disney's ML Denoiser та Intel Open Image Denoise революціонізують візуальні ефекти.

Технологічні компанії покладаються на машинне навчання для критично важливих додатків, але невиявлений дрейф моделі може призвести до фінансових втрат. Ефективний моніторинг моделей має вирішальне значення для раннього виявлення проблем і забезпечення стабільності та надійності моделей у виробництві.

Науковий фотограф Феліс Френкель обговорює вплив генеративного штучного інтелекту на наукову комунікацію у своїй нещодавній статті для журналу Nature. Вона підкреслює важливість етичної візуальної репрезентації та необхідність підготовки дослідників у сфері візуальної комунікації для забезпечення точності та прозорості.