
ШІ повертає до життя Чарльза Дарвіна, обговорюючи еволюцію зі студентами, і перетворює Лутон на автомобіль, захоплюючи як викладачів, так і студентів. Міністр освіти Бріджит Філліпсон виступає за впровадження штучного інтелекту в школах, а початкова школа Віллоудаун вже використовує можливості цифрової революції.

Держдеп США використовує штучний інтелект для анулювання віз іноземним студентам, яких вважають прихильниками ХАМАС. Указ Трампа спрямований проти пропалестинських протестувальників на тлі триваючого конфлікту з Ізраїлем.

Група з Грузії ошукала тисячі людей за допомогою підроблених відео з Мартіном Льюїсом, Зої Болл та Беном Фоґлом, які просувають фальшиві криптовалютні схеми. 6 000 людей були ошукані в інвестиційному шахрайстві на $35 млн; з жертвами досі зв'язуються.

Математичні вундеркінди Кремнієвої долини та дослідники ШІ на чолі з Зізом утворюють нібито жорстокий культ. Зіз, комп'ютерний програміст, купив вітрильник, перш ніж стати центральним фігурантом численних вбивств.

CMA не буде розслідувати партнерство Microsoft зі стартапом ChatGPT через відсутність контролю, незважаючи на інвестиції в $13 млрд. Матеріальний вплив Microsoft на OpenAI недостатній для того, щоб викликати офіційне розслідування з боку британського антимонопольного відомства.

Творець вірусного відео «Трамп Газа» відреагував на те, що Трамп опублікував його на Truth Social, зобразивши Газу як рай у дубайському стилі з політичною сатирою. Відео показує Трампа з Нетаньяху та Ілоном Маском у пляжному курортному містечку.

Американський суддя відхилив прохання Маска призупинити перехід OpenAI на комерційну модель, прискоривши розгляд спору до осіннього судового засідання. Суддя заявив, що Маск не відповідає високим вимогам для попередньої судової заборони.

Рішення RAG не відповідають очікуванням користувачів, бо стикаються з нюансованими питаннями. Агентна дистиляція знань + пірамідальний підхід до пошуку спрощує процес RAG, зосереджуючись на збереженні значущої інформації.
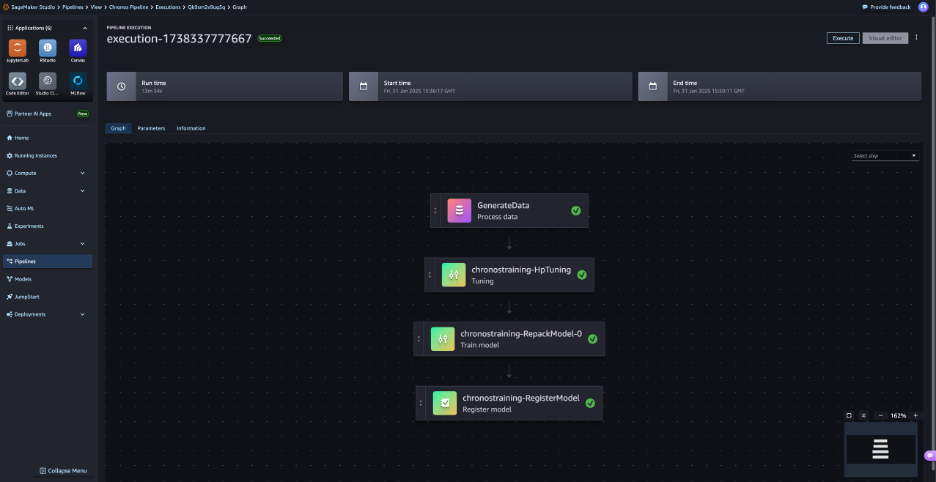
Chronos, революційна модель часових рядів, використовує великі мовні архітектури моделей, щоб досягти успіху в прогнозуванні з нуля, перевершуючи моделі, орієнтовані на конкретні завдання. Розглядаючи дані часових рядів як мову, Chronos спрощує процеси розробки та пропонує точні прогнози з мінімальним обсягом даних.

Більше половини британських керівників не мають офіційного плану впровадження штучного інтелекту, що призводить до розриву в продуктивності між користувачами і не користувачами ШІ. Опитування Microsoft вказує на компанії, які «застрягли в нейтралітеті» щодо стратегії ШІ.
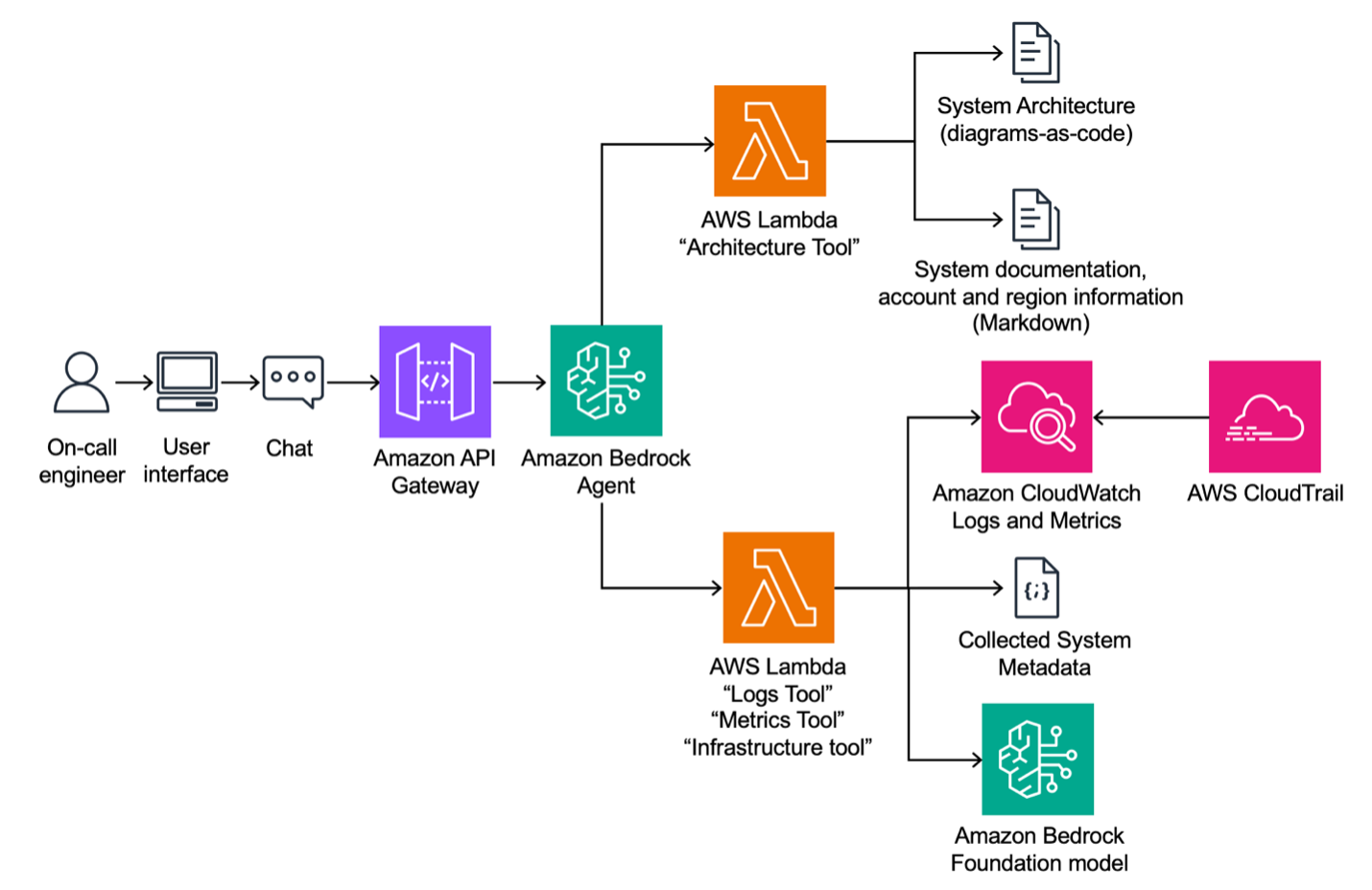
BMW Group, світовий лідер у виробництві автомобілів преміум-класу, використовує генеративний ШІ на AWS для покращення цифрових послуг для свого підключеного автопарку з 23 мільйонів автомобілів. Використовуючи Amazon Bedrock Agents, BMW досягає 85% точності у визначенні першопричин перебоїв в обслуговуванні, що значно скорочує час діагностики.
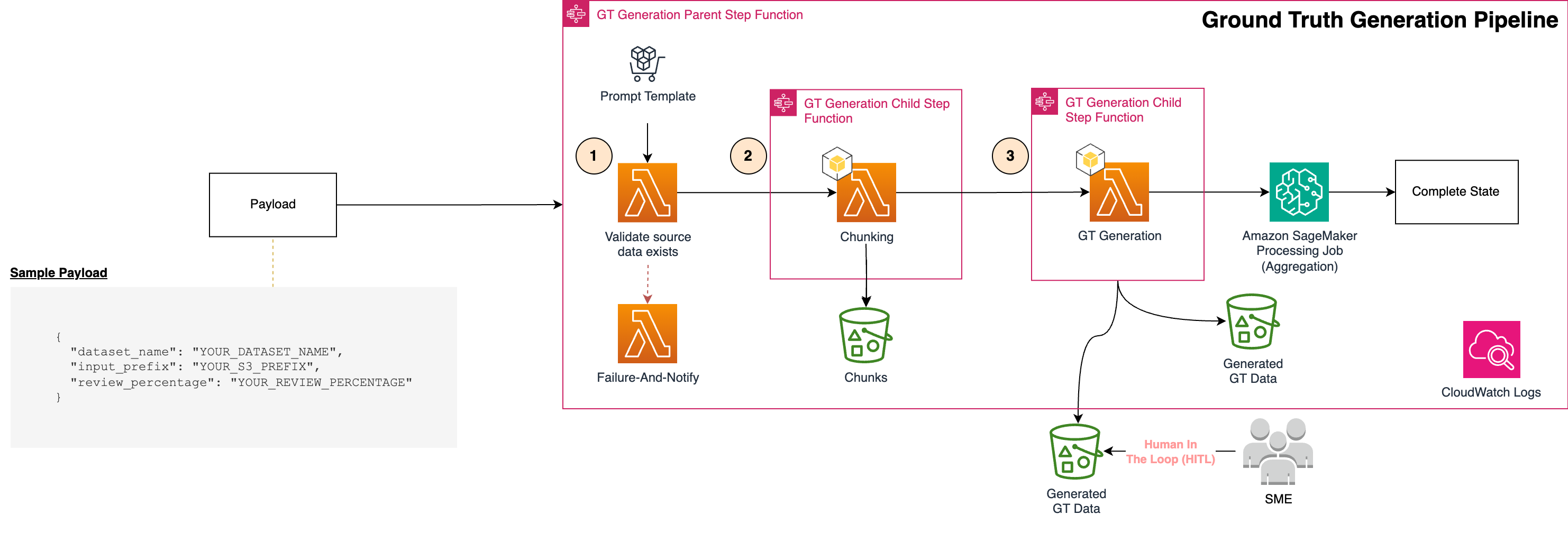
Генеративні програми зі штучним інтелектом підвищують продуктивність. Надійні асистенти ШІ потребують надійної бази даних та системи оцінювання.

Вчителі математики пристосувалися до калькуляторів у 1970-х роках; сучасні побоювання щодо штучного інтелекту повторюють історію. Викладачі гуманітарних дисциплін повинні адаптуватися до інструментів штучного інтелекту.

Скасування Трампом захисту штучного інтелекту Байдена ставить американських працівників під загрозу скорочення робочих місць, попереджають експерти, оскільки керівники компаній планують реформування робочої сили.

Amazon Bedrock Knowledge Bases пропонує економічно ефективний спосіб покращити результати роботи великих мовних моделей (LLM), підключивши їх до внутрішніх джерел даних. Розробники отримують більший контроль над результатами LLM завдяки фільтруванню метаданих для підвищення точності пошуку та персоналізованих відповідей.