
Лідери італійського бізнесу, такі як Джорджіо Армані та Патріціо Бертеллі, стали жертвами афери зі штучним інтелектом, який використовував голос міністра оборони для вимагання викупу за викрадених журналістів. Прокуратура Мілана розслідує юридичні скарги відомих діячів, зокрема колишнього власника міланського «Інтера» Массімо Моратті, щодо клонованих голосових дзвінків.

Міністр технологій Великобританії попереджає, що західні країни повинні очолити гонку ШІ, і натякає на зростаючий вплив Китаю через DeepSeek. Американські інвестори збентежені, оскільки домінування Кремнієвої долини в галузі ШІ було поставлено під сумнів на глобальному саміті в Парижі.

Художники вимагають від аукціону Christie's скасувати продаж творів мистецтва, створених штучним інтелектом, називаючи це «масовою крадіжкою» робіт, навчених на людському мистецтві. На першому великому аукціоні, присвяченому штучному інтелекту, представлені роботи Рефіка Анадола та Гарольда Коена.

Зростання ролі штучного інтелекту в юридичній сфері викликає занепокоєння, оскільки суди побоюються його використання при написанні юридичних документів і цитуванні судових справ. Використання адвокатом ChatGPT для написання резюме справи призвело до неіснуючих посилань, що підкреслює потенційні ризики використання ШІ в юридичній роботі.

Джей Бернард, поет, лауреат багатьох нагород, використовує штучний інтелект у проекті The Last X Years, щоб виявити маніпуляції з якісними даними в розмовах про Brexit, роблячи невидимі процеси видимими. Використовуючи TensorFlow від Google, проект пов'язує заголовки новин та інтерв'ю, проливаючи світло на маніпуляції з демократією в цифрову епоху.

Штучний інтелект загрожує творчості в письменницькій індустрії, Гільдія авторів планує створити знак довіри до книг, написаних людиною. Автор тестує ШІ на ефективність написання роману в сиквелі трилера «Задзеркалля».
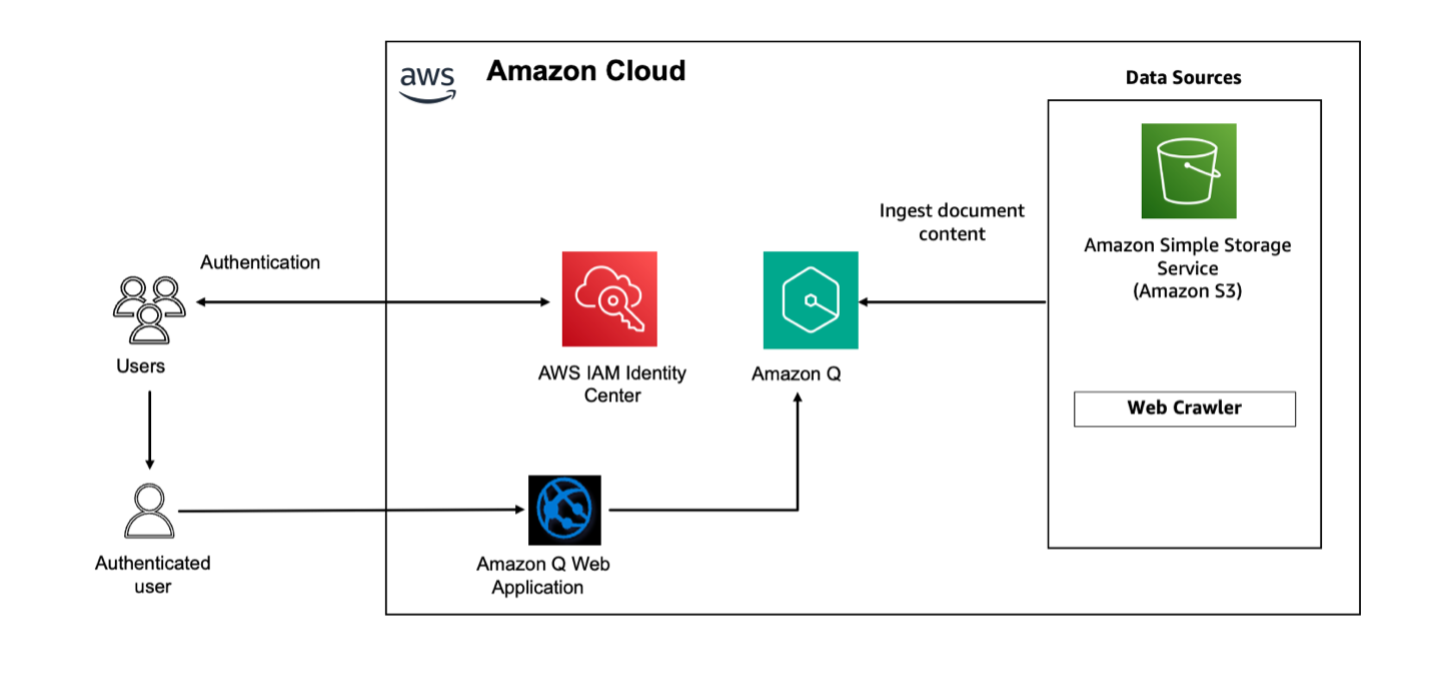
AWS пропонує стартові набори, розгорнуті рішення, які вирішують поширені бізнес-проблеми, оптимізуючи витрати та заощаджуючи час. Amazon Q Business - це асистент на основі штучного інтелекту, який дає змогу працівникам бути більш креативними, ефективними та продуктивними.

Модель R1 від DeepSeek отримала високу оцінку за продуктивність і вартість, спричинивши потенційні зміни в ландшафті LLM. Розуміння еталонних показників LLM є ключем до подолання хайпу та створення конкретних еталонних показників для конкретних сценаріїв використання.

Дослідники з Массачусетського технологічного інституту виявили недоліки в традиційних методах перевірки просторових прогнозів, що призводять до неточних прогнозів. Вони розробили нову методику, яка перевершила загальноприйняті методи прогнозування погоди та якості повітря, пропонуючи більш надійні оцінки для різних застосувань.
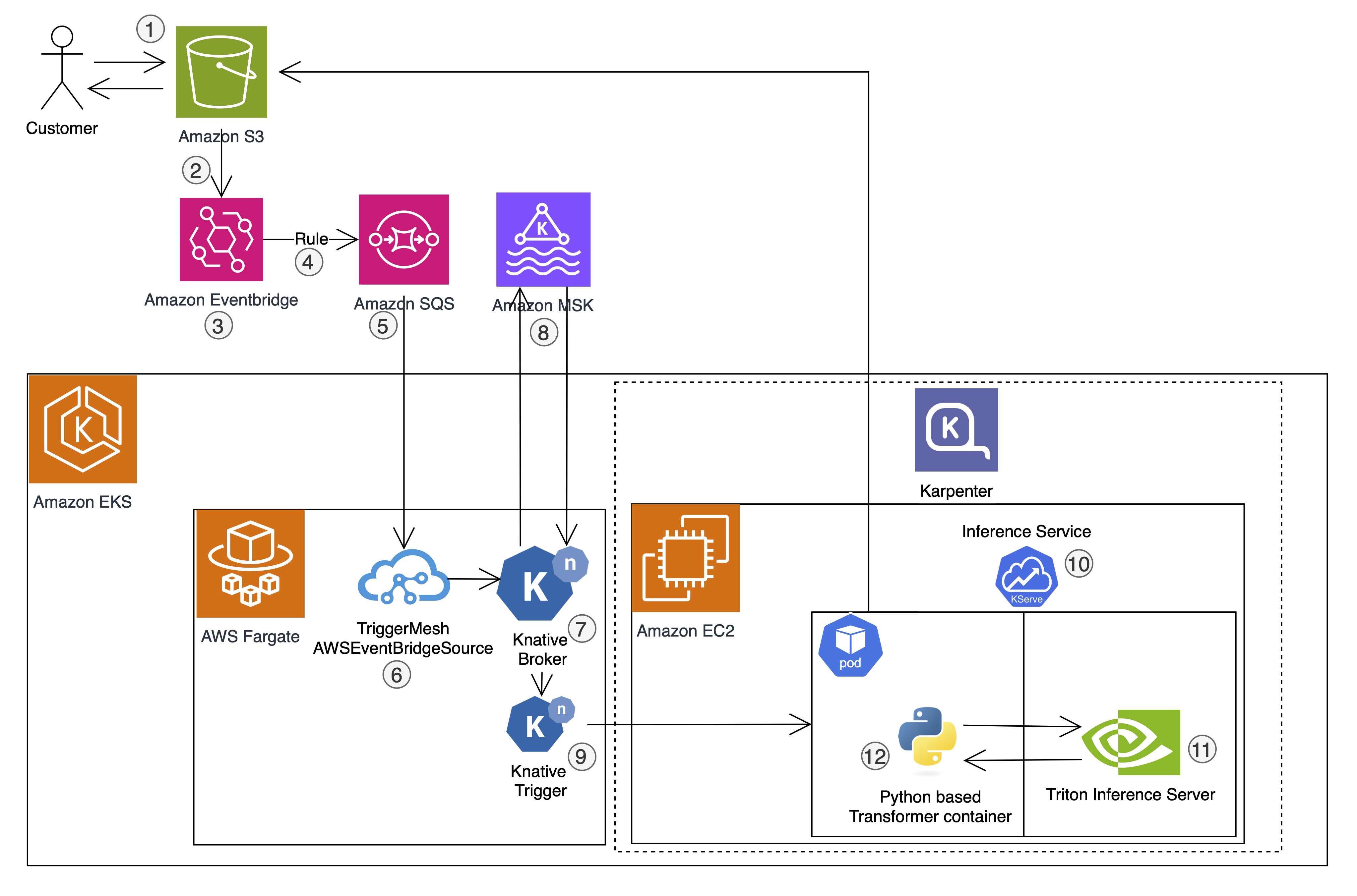
CONXAI Technology GmbH є піонером у створенні платформи штучного інтелекту для індустрії AEC, пропонуючи розширені можливості анонімізації та розпізнавання об'єктів. Розміщене на AWS, рішення ШІ пропонує варіанти MaaS та SaaS для безперешкодної інтеграції та дотримання вимог GDPR на будівельних майданчиках.

A/B-тести порівнюють лікування А і лікування Б для кампаній, щоб визначити, яке з них приносить більший дохід на покупця. Маркетологи аналізують частоту покупок і середню суму замовлення, щоб ефективно оптимізувати кампанії.

Нещодавній відкритий лист піднімає моральні питання щодо свідомості ШІ. Важко визначити, чи є ШІ справді свідомим, чи лише імітує його. Дискусія вимагає обережного, агностичного підходу.

Білки, створені за допомогою штучного інтелекту, нейтралізують смертельну зміїну отруту швидше, дешевше та ефективніше, ніж традиційні протиотрути. Цей прорив дає надію на доступне лікування, яке врятує мільйони життів і засобів до існування в сільських громадах по всьому світу.

Каймінг Хе з Массачусетського технологічного інституту бачить, як ШІ руйнує стіни між науковими дисциплінами, створюючи спільну мову для прогресу та співпраці. Від AlphaFold до ChatGPT, інструменти ШІ сприяють прогресу в різних галузях, таких як прогнозування структури білків та обробка природної мови.
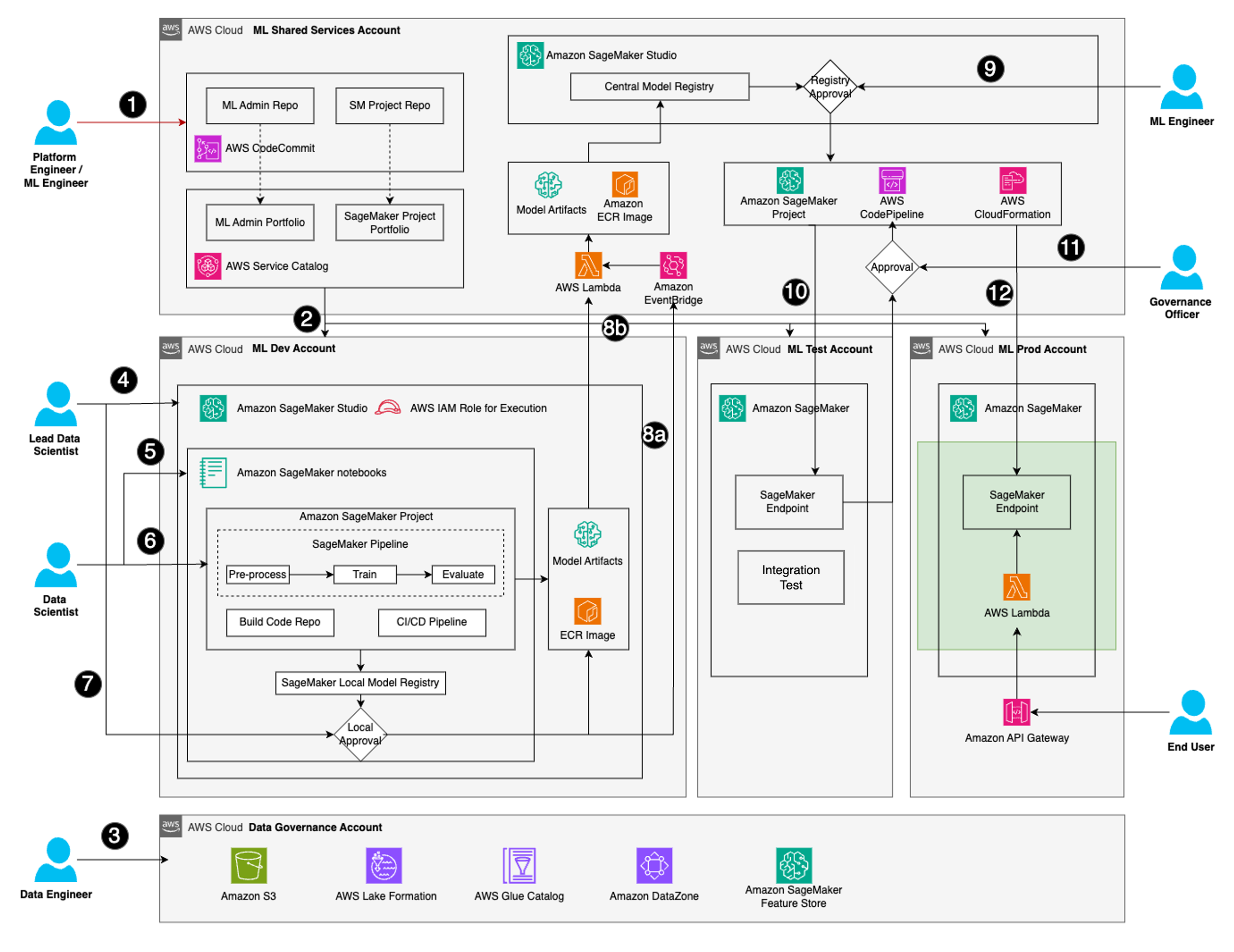
Команди, що займаються наукою про дані, стикаються з проблемами при переході від моделей до виробництва, але багатоакаунтна платформа ML вирішує ці проблеми. Такі ролі, як провідний аналітик даних, аналітики даних, інженери ML та керівники, працюють разом, щоб оптимізувати життєвий цикл ML, забезпечуючи безпеку та ефективність.