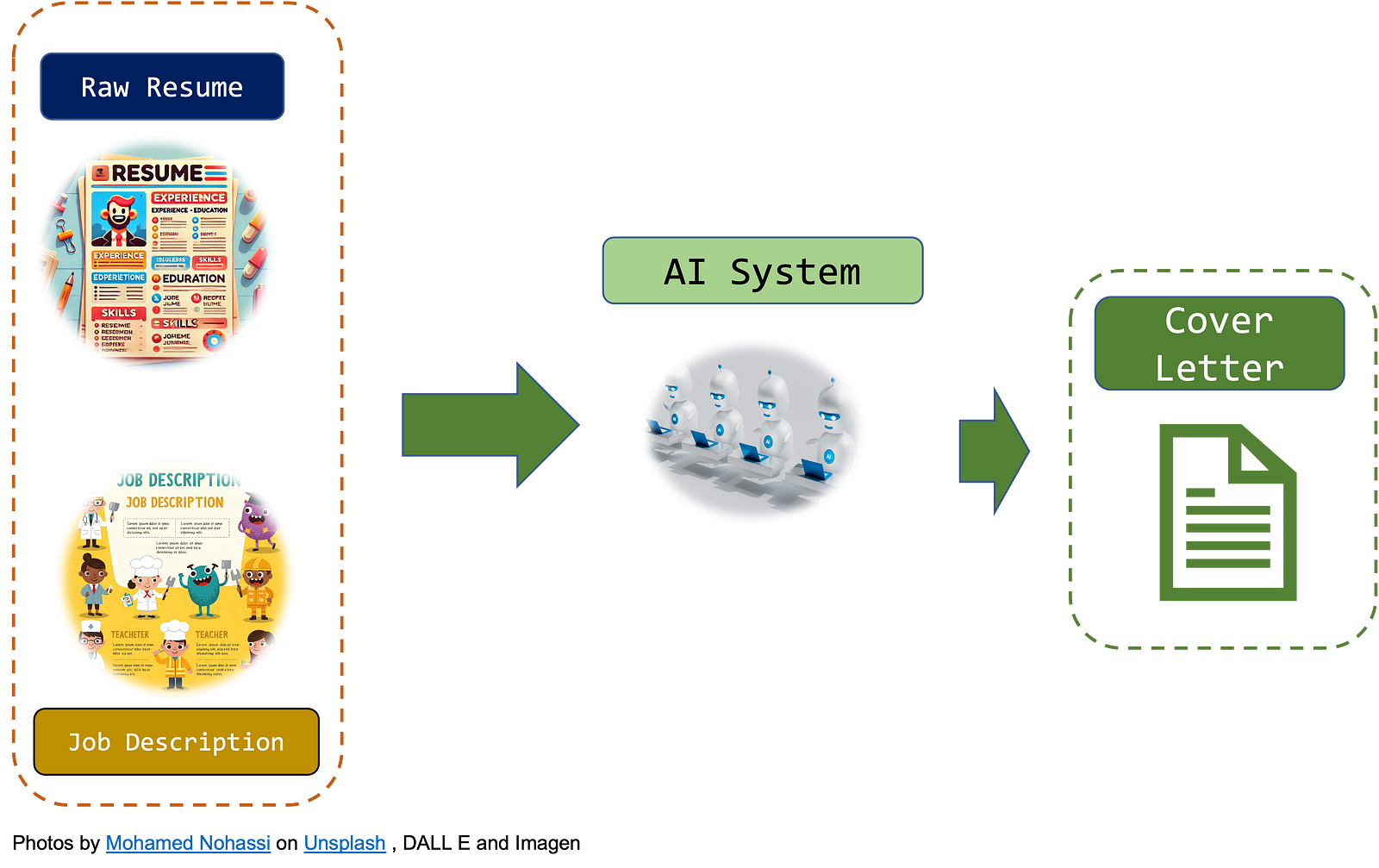
Створіть власний додаток для створення АІ-генератора супровідних листів за допомогою Python з кодом із загальнодоступної папки Github. Інструменти штучного інтелекту, такі як ChatGPT, можуть допомогти адаптувати резюме для конкретних компаній, змінюючи правила гри на ринку праці.

Чат-бот DeepSeek, розроблений у Китаї, кидає виклик технологічній перевазі США, пропонуючи дешевший та енергоефективніший інструмент штучного інтелекту. Незважаючи на обмеження, його стрімке зростання підкреслює, що економічні наслідки переважають над технічними досягненнями.
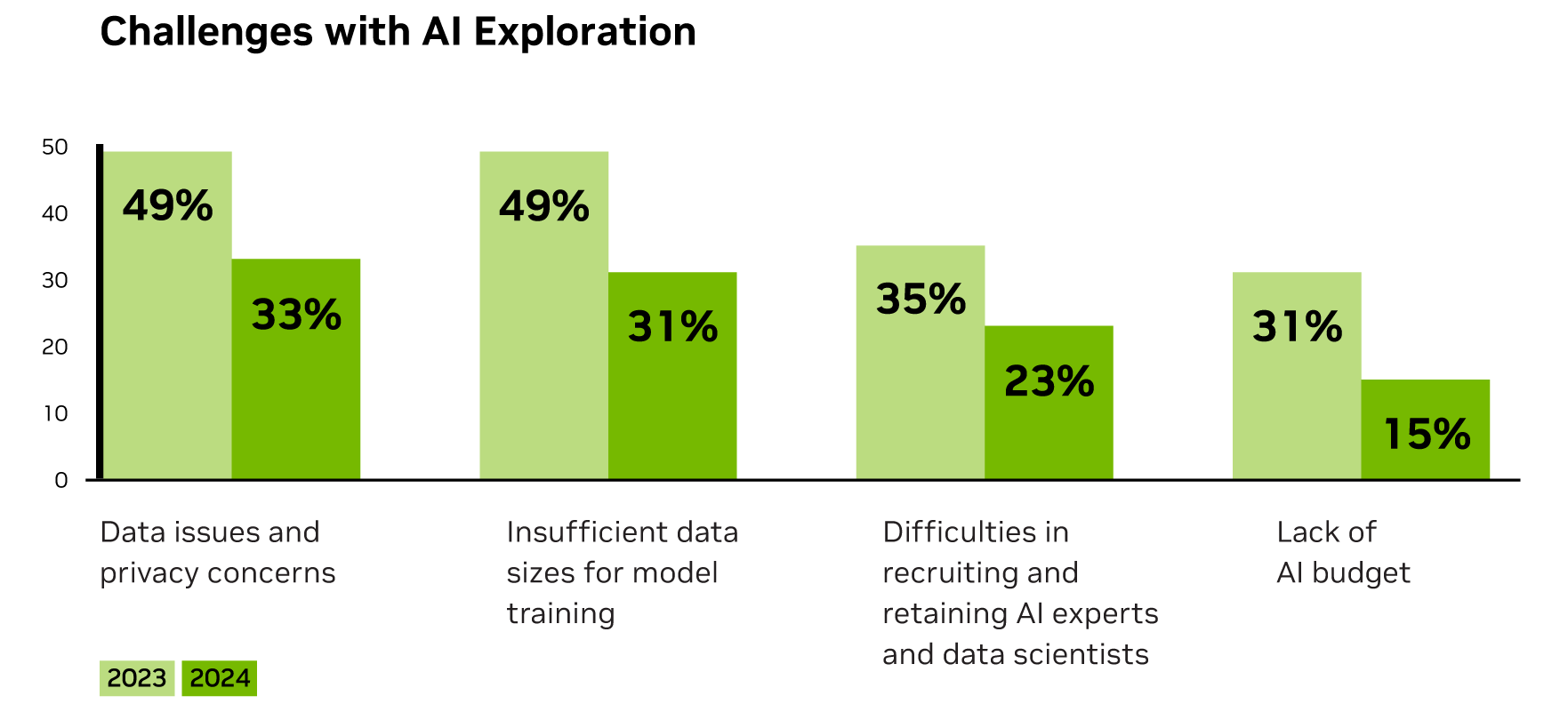
Фінансові установи використовують ШІ для зростання доходів і скорочення витрат, а звіт NVIDIA демонструє значне зростання рівня впровадження та майстерності ШІ. Генеративний ШІ підвищує рентабельність інвестицій у торгівлю, залучення клієнтів тощо, оскільки компанії долають бар'єри на шляху до успішного розгортання ШІ.

Графічні процесори NVIDIA GeForce RTX 5090 і 5080 на базі архітектури Blackwell забезпечують у 8 разів вищу частоту кадрів завдяки технології DLSS 4. Мікросервіси NVIDIA NIM і AI Blueprints для RTX забезпечують легкий доступ до генеративних моделей ШІ на ПК, прискорюючи розробку ШІ на різних платформах.

Дізнайтеся, як покращити свій RAG-додаток, імітуючи людське мислення в мультиагентній системі. Дізнайтеся, як покращити процеси пошуку даних та міркувань для отримання більш точних результатів.
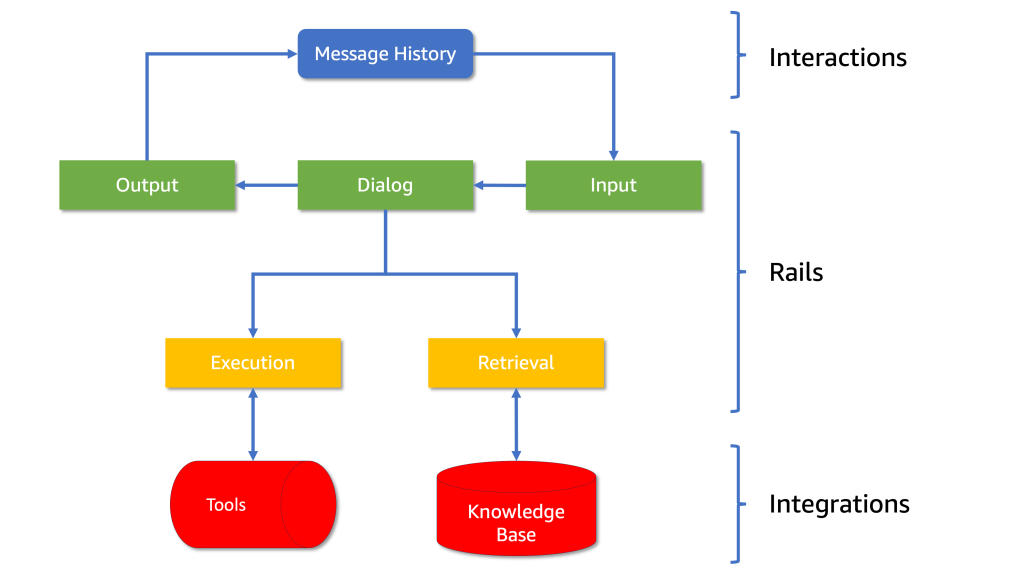
Компанії використовують LLM для підвищення залученості клієнтів, але стикаються з проблемами, коли їм важко залишатися в курсі подій. Компанія AnyCompany Pet Supplies використовує NeMo Guardrails для асистента зі штучним інтелектом, потоків розмов та інтеграції даних, щоб покращити досвід клієнтів.

Кейр Стармер пропустив саміт ШІ в Парижі, втративши можливість зустрітися з Макроном, Моді, Венсом і Маском. Відсутність прем'єр-міністра на міжнародній конференції, організованій Ріші Сунаком, викликає здивування.
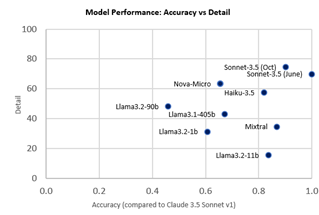
Trellix Wise на основі штучного інтелекту автоматизує розслідування загроз для команд безпеки, заощаджуючи час і розширюючи охоплення. Партнерство Trellix з Amazon Nova Micro забезпечує швидші висновки при значно менших витратах, оптимізуючи розслідування.

В оновленому керівництві Alphabet знято заборону на використання ШІ для зброї та спостереження, що викликало етичні занепокоєння. Зміна оголошена перед невтішним звітом про прибутки.
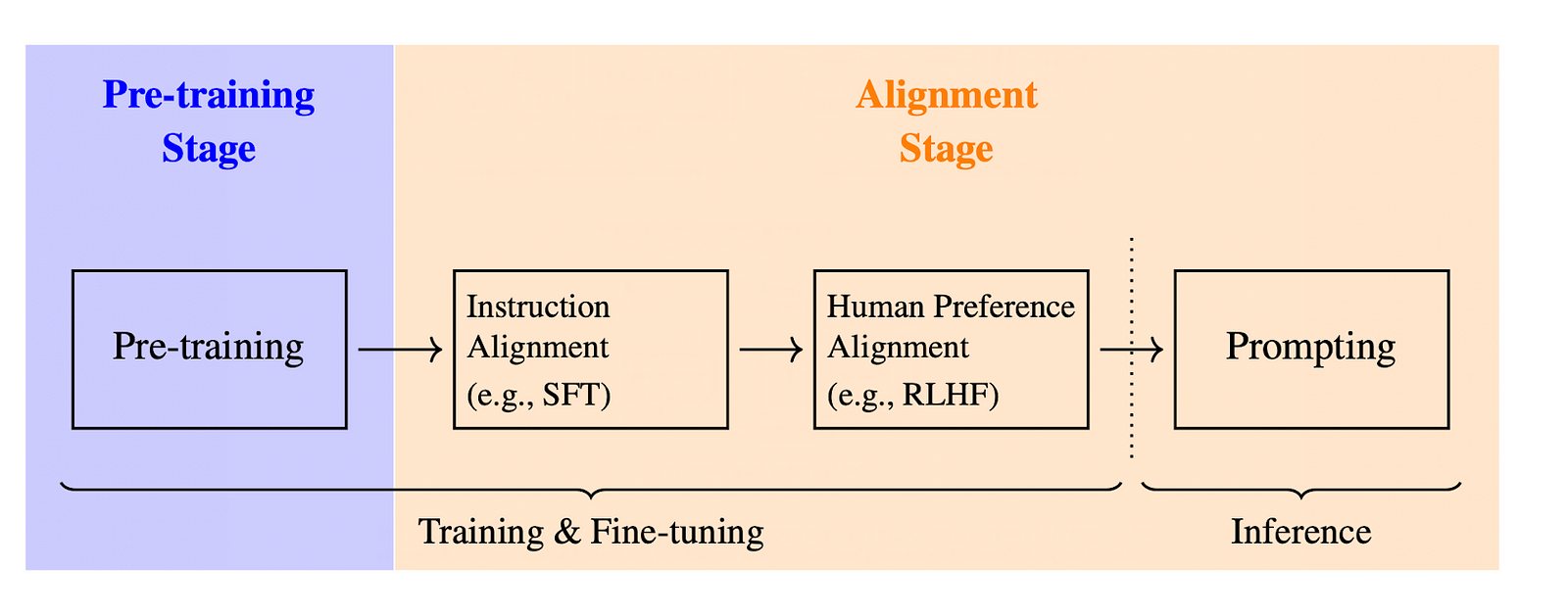
Економічна ефективність ШІ від Deepseek привертає увагу. Дізнайтеся про навчання з підкріпленням у великих мовних моделях, зосередившись на TRPO, PPO та GRPO. Вивчіть основи RL, використовуючи аналогію з лабіринтом, і як це застосовується в LLM для вдосконалення відповідей на основі людського зворотного зв'язку.
BBC розкритикувала Apple Intelligence за неточні підсумки новин, що змусило Apple призупинити роботу інструменту. Серед помилок штучного інтелекту були неправдиві повідомлення про таких відомих діячів, як Біньямін Нетаньяху та Рафаель Надаль.
Уряд Албанії заборонив використання чат-бота DeepSeek AI на федеральних пристроях з міркувань національної безпеки, що викликало занепокоєння на американських фондових біржах. Міністр внутрішніх справ Тоні Берк називає причиною заборони поради спецслужб, а не китайське походження чат-бота.

Alphabet стикається з уповільненням темпів зростання доходів і потенційною втратою конкурентних переваг до 2025 року. Незважаючи на невиконання очікувань щодо доходів, компанія перевершує прогнози щодо прибутку на акцію завдяки сильному лідерству у сфері ШІ.
АІ-бабуся» Daisy від O2 - це штучний інтелект, створений для боротьби з шахраями, які витрачають свій час на сумніви та плутанину. Тактика Дейзі змушує шахраїв зітхати та огризатися, демонструючи силу штучного інтелекту в боротьбі з шахрайством.
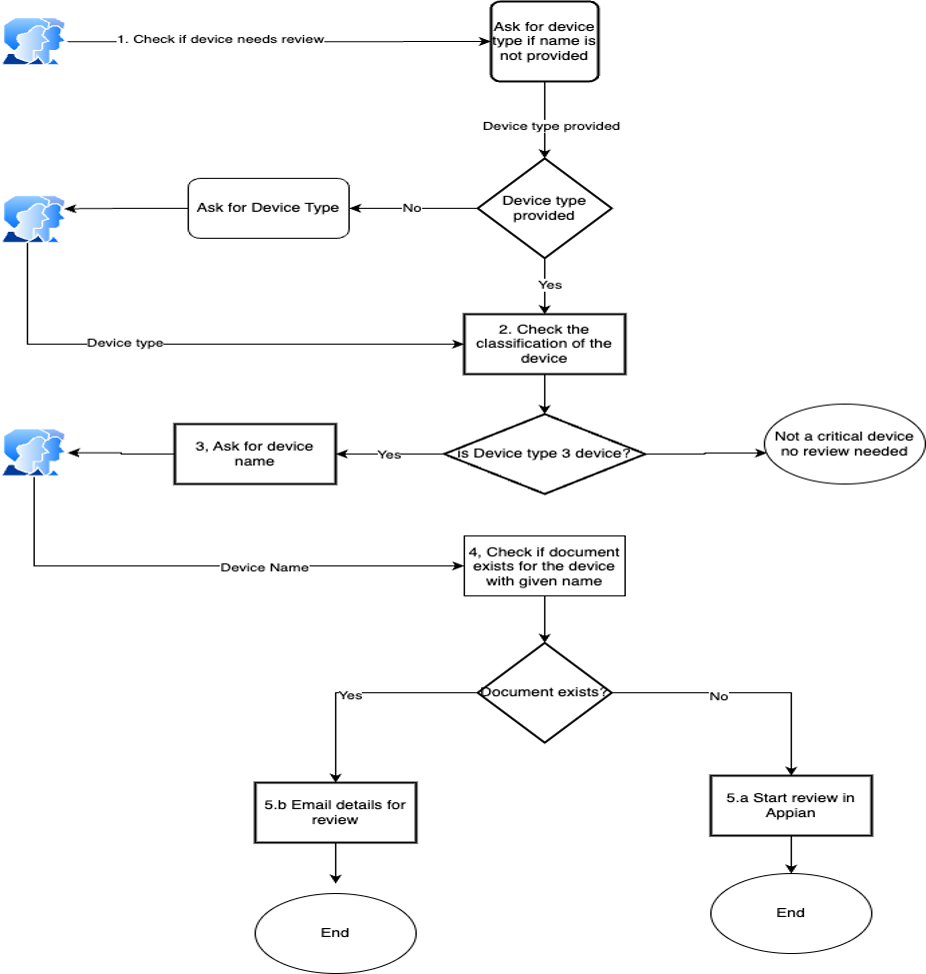
Генеративний ШІ покращує бізнес-системи за допомогою агентів Amazon Bedrock Agents, оптимізуючи робочі процеси та автоматизуючи завдання. Це рішення інтегрується з Appian Case Management Studio, демонструючи ефективний доступ до даних та можливості оркестрування.