
Нова гра Anlife: Motion-learning Life Evolution, яка викликала критику, зокрема з боку Хаяо Міядзакі, тепер доступна на Steam після суперечливої реакції на технологію штучного інтелекту. Розробники оговталися від критики Міядзакі і випустили унікальне програмне забезпечення, що поєднує симуляцію життя і науковий проект.
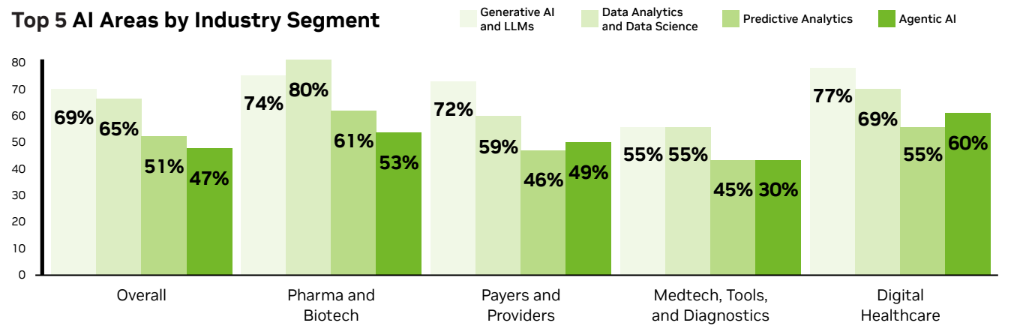
Опитування NVIDIA показує, що в галузі охорони здоров'я штучний інтелект застосовується для медичної візуалізації, розробки ліків та зниження витрат, а відкрите програмне забезпечення та агентний штучний інтелект набирають популярності. Застосування штучного інтелекту зростає у всіх секторах охорони здоров'я, зокрема в цифровій медицині.

Акції Uber, Mastercard та American Express падають через спекулятивний сценарій апокаліпсису штучного інтелекту від Citrini Research на Substack. Інвестори стурбовані попередженням про те, що автономні системи штучного інтелекту можуть зруйнувати економіку США в найближчому майбутньому.
Meta укладає угоду з AMD на суму 60 млрд доларів на тлі побоювань щодо бульбашки штучного інтелекту

Власник Meta купує чіпи для штучного інтелекту на суму 60 млрд доларів у компанії AMD, що є частиною тенденції до витрат на штучний інтелект у розмірі 660 млрд доларів у США, «великої ставки» на штучний інтелект. Аналітики припускають, що це може свідчити про зміну стратегії Meta у сфері штучного інтелекту.
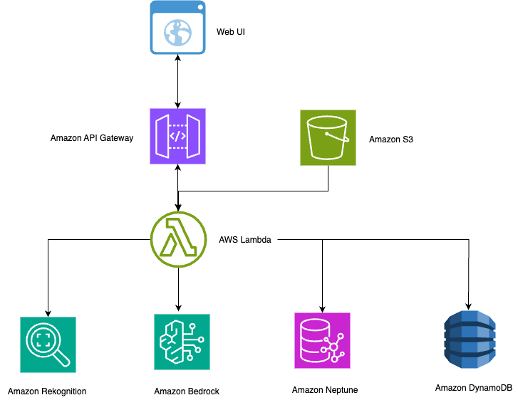
Інтелектуальні системи пошуку фотографій використовують комп'ютерний зір та обробку природної мови, щоб революціонізувати організацію фотографій. Amazon Rekognition, Neptune та Bedrock забезпечують персоналізований пошук із складним відображенням взаємозв'язків для тисяч зображень.

Технологічні мільярдери вкладають гроші в проміжні вибори в Каліфорнії; Індія кидає виклик домінуванню США і Китаю в галузі штучного інтелекту на саміті. Занепокоєння щодо штучного інтелекту викликає рух робітників.

Структуровані виходи в додатках штучного інтелекту мають вирішальне значення для забезпечення узгодженості та валідації. Фреймворк Outlines від .txt на AWS Marketplace покращує генеративний штучний інтелект для точного обміну даними та зменшення кількості помилок у середовищах з високими ризиками.
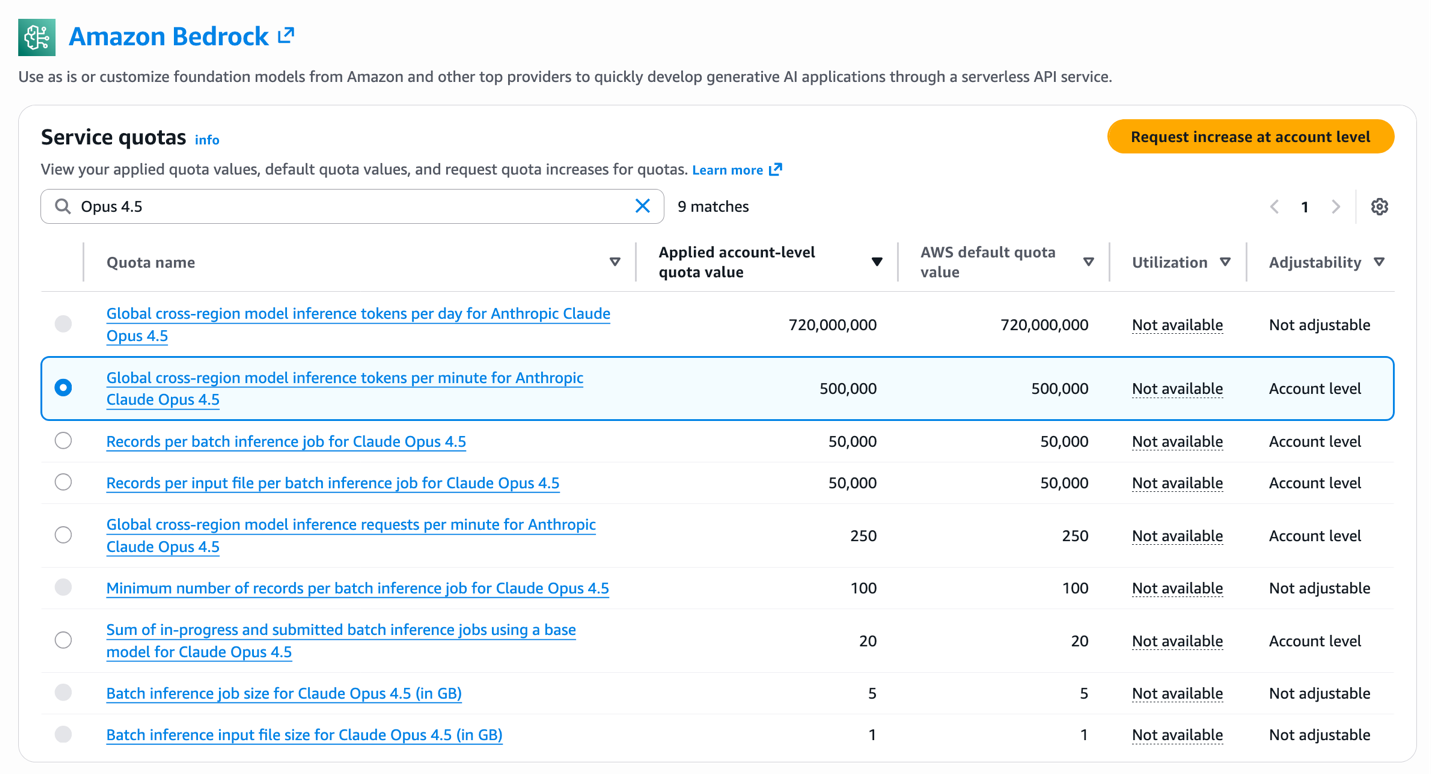
Організації в Таїланді, Малайзії, Сінгапурі, Індонезії та Тайвані тепер можуть отримати доступ до моделей штучного інтелекту Anthropic через Global CRIS на Amazon Bedrock, що забезпечує вищі квоти, економічну ефективність та інтелектуальну маршрутизацію запитів для випадків використання штучного інтелекту, таких як чат-боти та системи фінансового аналізу. Global CRIS забезпечує безперебійний р...

Штучний інтелект обманює нас реалістичними онлайн-сценаріями, стираючи межу між реальністю та технологіями. Гумористичний ролик в Instagram із 3D-діркою в Нью-Йорку викликає екзистенційні сумніви щодо того, що є реальним.

Експерт з штучного інтелекту Тобі Уолш критикує австралійський уряд за відсутність регулювання у сфері штучного інтелекту та попереджає про ризик розвитку психозу під час взаємодії з чат-ботами. Уолш називає прагнення Кремнієвої долини до отримання прибутку за допомогою технологій штучного інтелекту «необережним» і прогнозує, що гонка за штучним інтелектом принесе як переваги, так і ризики.

США борються із затримками та скасуванням будівництва нових центрів обробки даних на тлі буму штучного інтелекту через проблеми з ланцюгами постачання, дефіцит енергії та опір місцевих жителів. Інвестори обережно ставляться до потенційної бульбашки штучного інтелекту, яка може вплинути на розширення інфраструктури.
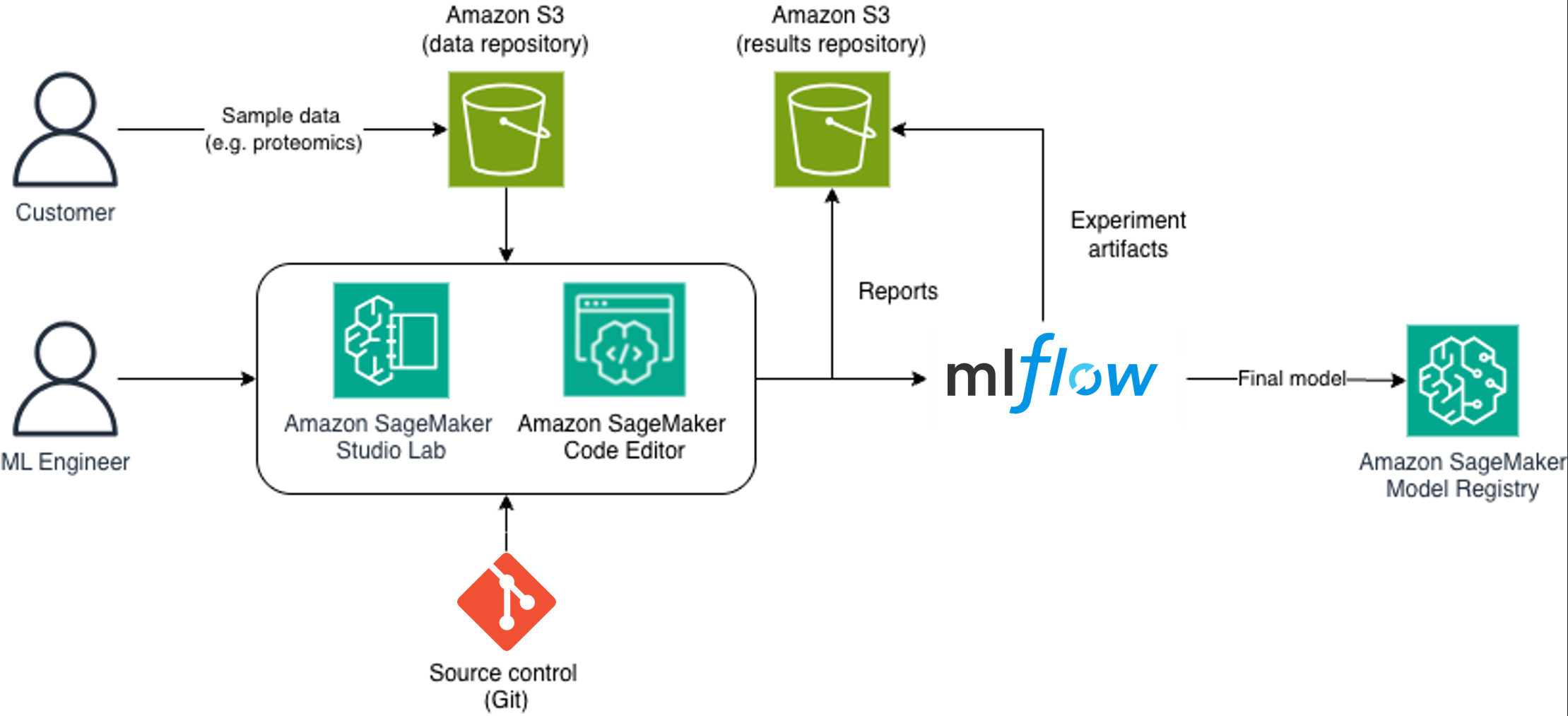
Дослідники в галузі прецизійної медицини стикаються з проблемами, пов'язаними з наборами даних у тестах на раннє виявлення захворювань. Компанія Sonrai у співпраці з AWS створила надійну платформу MLOps з використанням штучного інтелекту Amazon SageMaker для забезпечення простежуваності та відтворюваності в регульованих середовищах.
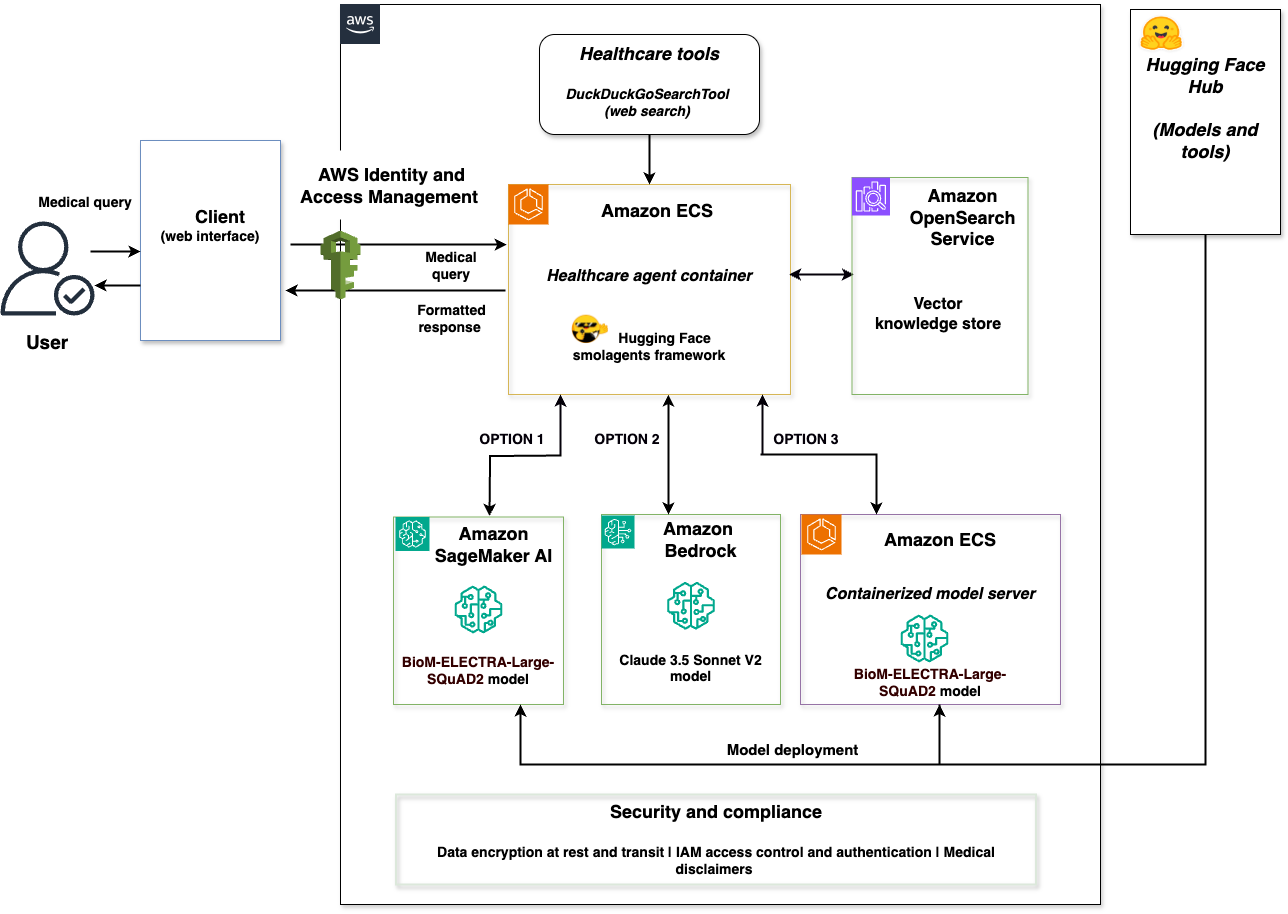
Hugging Face представляє бібліотеку Python smolagents для створення автономних агентів. Інтеграція з AWS забезпечує медичного AI-агента можливостями багатомодельного розгортання та підтримки клінічних рішень.

Критична нестача робочої сили в таких галузях, як будівництво, вирішується за допомогою автономних систем, таких як ті, що розроблені компанією Bedrock Robotics. Використовуючи моделі Vision-Language, вони оптимізують підготовку даних для навчання моделей штучного інтелекту, забезпечуючи автономну роботу обладнання з точністю до сантиметра.

Anthropic повідомляє, що китайські компанії витягли інформацію з чат-бота Claude за допомогою техніки «дистиляції», звинувачуючи їх у крадіжці інтелектуальної власності. OpenAI також висунула подібні звинувачення минулого місяця.