Багатоагентні генеративні системи штучного інтелекту поєднують спеціалізовані агенти для більш ефективного вирішення складних завдань, а Amazon Nova забезпечує високу пропускну здатність і економічну ефективність. Ці системи забезпечують ітеративне самовдосконалення та надмірність, максимізуючи рівень успішності та якість відповідей.

Міністр фінансів Кеті Галлахер оголошує про програму штучного інтелекту в державній службі, яка сприятиме підвищенню продуктивності. Плани використання штучного інтелекту для обробки конфіденційних документів та бізнес-кейсів викликають занепокоєння щодо ризиків безпеки.
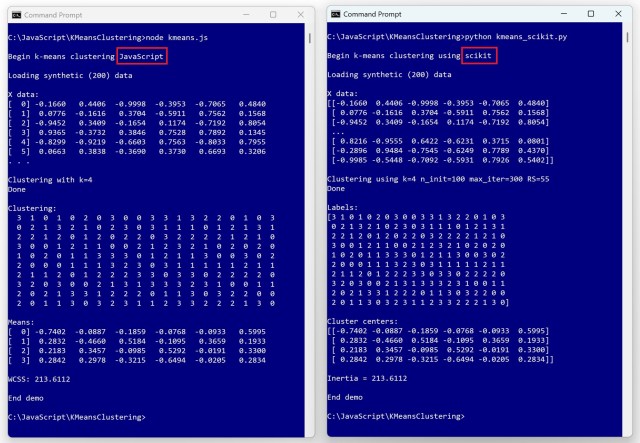
Демонстрація кластеризації JavaScript k-means з використанням синтетичних даних у порівнянні з модулем scikit-learn. Ідентичні результати, отримані за допомогою коду scikit після коригування параметрів.
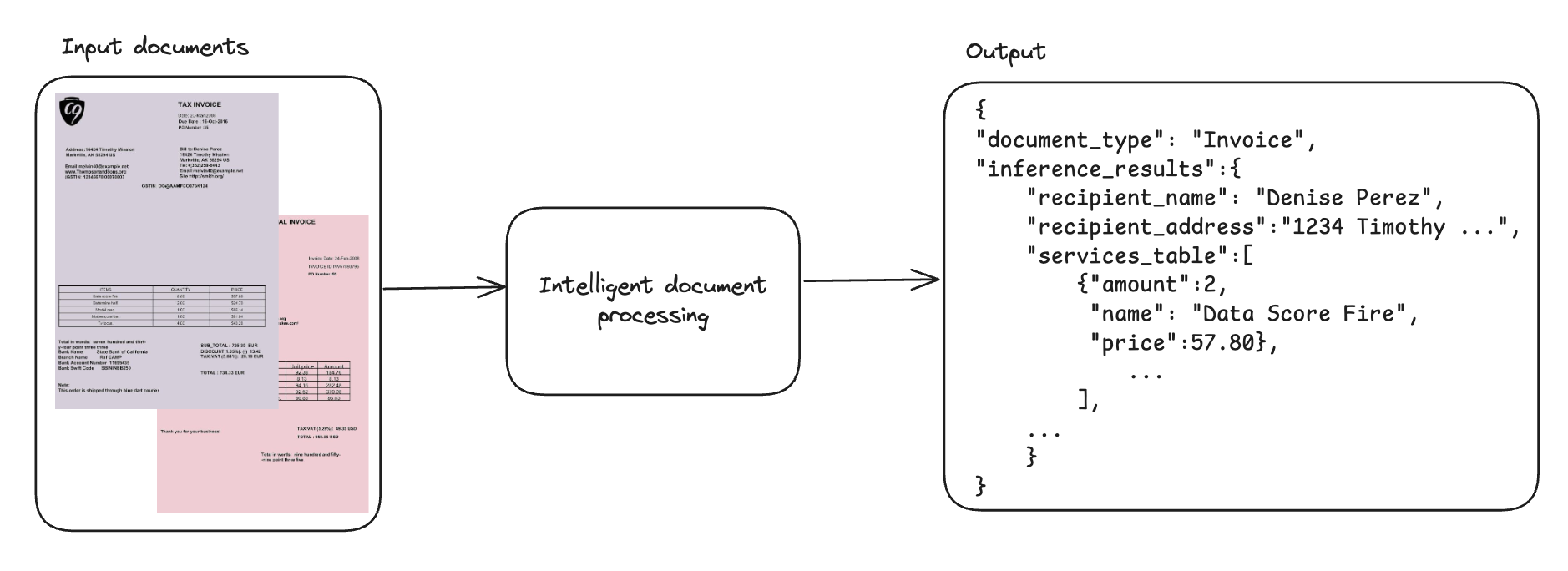
Інтелектуальна обробка документів (IDP) використовує штучний інтелект для вилучення структурованих даних з різних документів, зменшуючи кількість помилок і підвищуючи ефективність. Моделі мовного бачення (VLM) революціонізують IDP, поєднуючи текстове міркування та візуальну інтерпретацію для досягнення безпрецедентної точності.

В'язниця HMP Wandsworth отримала дозвіл на використання штучного інтелекту для запобігання помилковим звільненням ув'язнених після того, як команда впровадила «швидкі виправлення». Міністр юстиції Джеймс Тімпсон підкреслює потенціал чат-ботів зі штучним інтелектом у в'язничній системі.
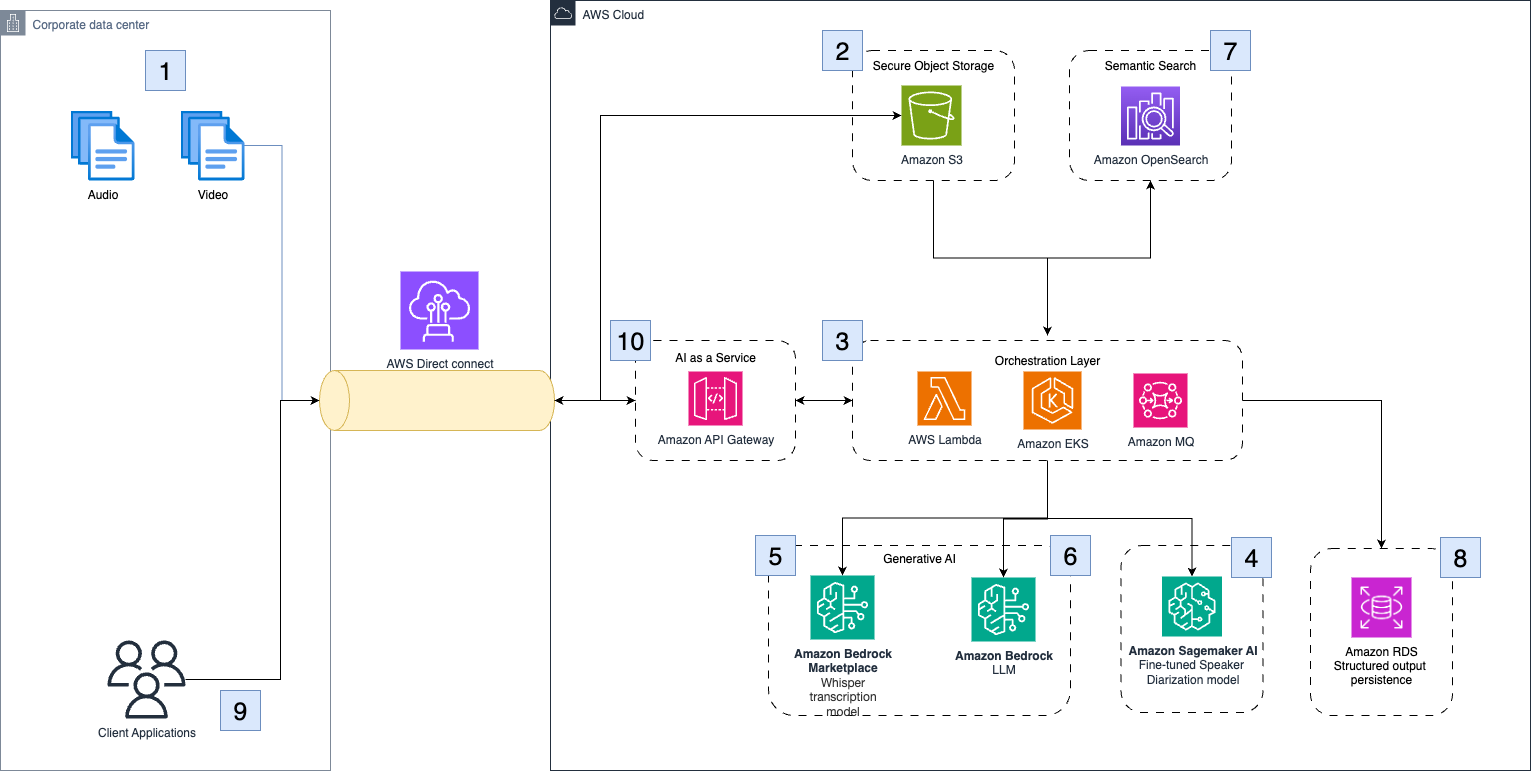
Clario використовує штучний інтелект та Amazon Bedrock для автоматизації аналізу інтерв'ю COA, покращуючи якість даних та оперативну ефективність клінічних випробувань. За допомогою впровадження діаризації мовців та LLM Clario прагне зменшити мінливість, підвищити надійність даних, оптимізувати операції та прискорити прийняття рішень для досягнення кращих результатів випробувань.

Аутсорсинг оригінальних ідей за допомогою ChatGPT для планування весілля викликає занепокоєння щодо автентичності та зв'язку у відносинах. Використання генеративної штучної інтелекту в процесах прийняття особистих рішень становить загрозу для справжніх емоційних зв'язків.

Громади в посушливих регіонах вимагають прозорості, оскільки уряди залучають іноземні інвестиції. Масштабні центри обробки даних, що сприяють буму штучного інтелекту, стикаються з опором, який можна порівняти з намаганням зупинити лавину.

Інвестори все більше турбуються, оскільки витрати ChatGPT ставлять під сумнів оптимізм Кремнієвої долини. Як OpenAI може дозволити собі зобов'язання на суму 1,4 трлн доларів?

У наш цифровий вік споглядання мистецтва може покращити самопочуття та надихнути на творчість. Художники дають поради, як жити мистецтвом, подалі від постійних відволікань та штучного інтелекту.

Філіп Ізола, доцент кафедри електротехніки та інформатики, досліджує інтелект, подібний до людського, в моделях штучного інтелекту, зосереджуючись на комп'ютерному зорі та машинному навчанні. Його мета — зрозуміти спільні риси інтелекту людини, тварин та штучного інтелекту, щоб безпечно інтегрувати штучний інтелект у суспільство.

Нимбізм, що базується на штучному інтелекті, може перешкоджати реалізації житлових планів уряду, оскільки Objector надає швидкі, підкріплені політикою заперечення проти заявок на планування. Новий інструмент дозволяє людям легко сканувати заявки та знаходити підстави для заперечень за лічені хвилини.

Штучний інтелект використовується для обману в вікторинах і заміни книжкових клубів, але результати можуть зіпсувати задоволення, як це видно на прикладі Substack. У своєму Substack Вілл Сторр критикує есе, створені штучним інтелектом, за відсутність глибини та оригінальності.

Штучний інтелект трансформує сферу охорони здоров'я завдяки транскрипції в режимі реального часу та діагностичним рекомендаціям, що викликає занепокоєння щодо відносин між пацієнтами та лікарями. Використання штучного інтелекту в клініках змінює спосіб запису та обробки медичної інформації, що потенційно може змінити основи взаємодії в сфері охорони здоров'я.

Морган Фріман розмірковує про те, як штучний інтелект «вкрав» його голос, і про важливість чіткої дикції. Його культовий голос, відточений важкою працею, продовжує зачаровувати аудиторію.