
MIT researchers developed a framework guiding ChatGPT to efficiently solve complex planning problems with an 85% success rate, outperforming baselines. This versatile approach could optimize tasks like scheduling airline crews or managing machine time in factories, revolutionizing planning assistance.

UK gov't pledges economic impact assessment to address concerns from MPs, peers, and creatives like Paul McCartney. Proposal criticized by McCartney, Tom Stoppard, Kate Bush for AI companies to use copyright-protected work without permission.

The diffusion model, pioneered by Sohl-Dickstein et al. and further developed by Ho et al., has been adapted by OpenAI and Google to create DALLE-2 and Imagen, capable of generating high-quality images. The model works by transforming noise into images through forward and backward diffusion processes, maintaining the original image's dimensionality in the latent space.
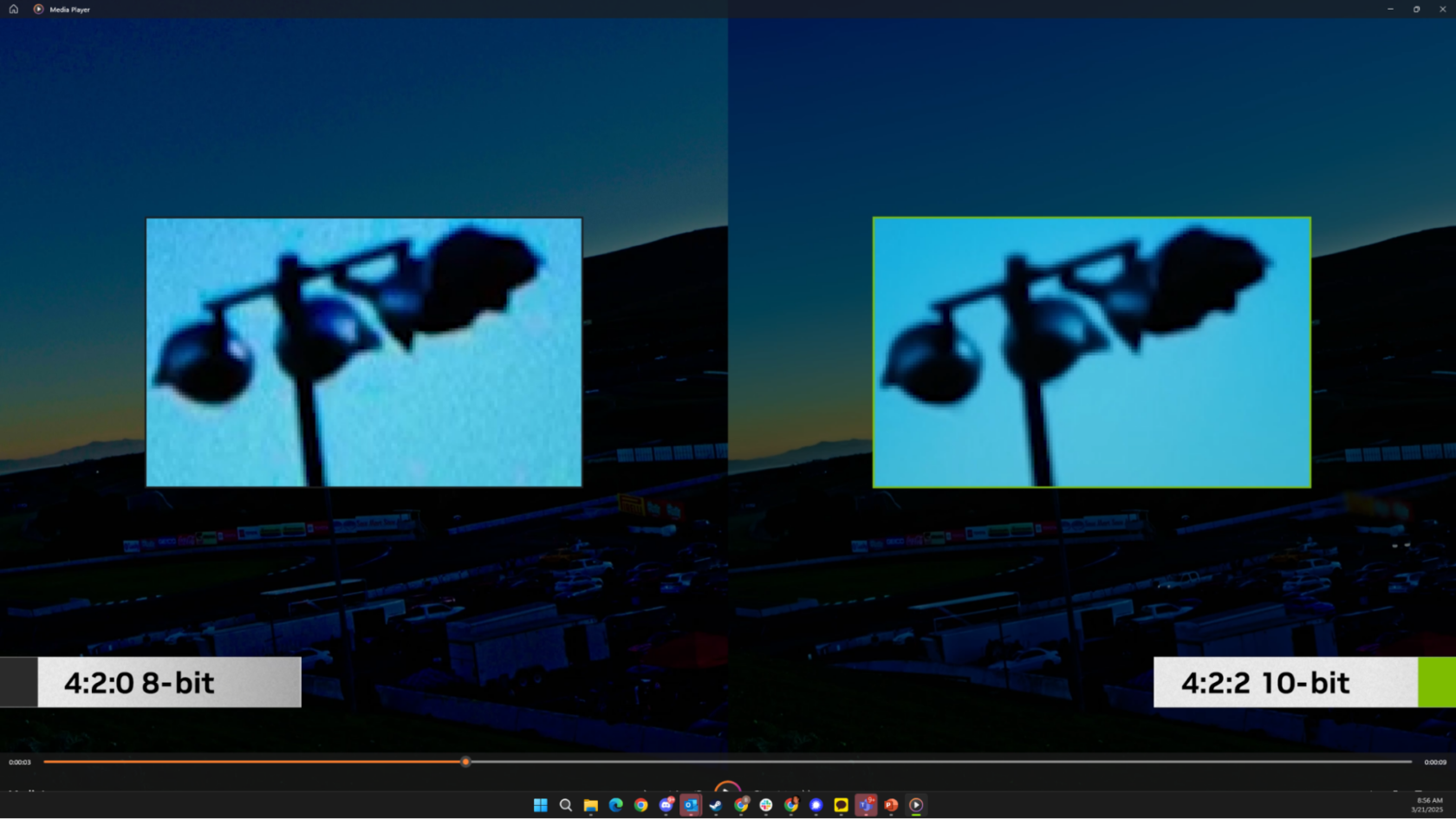
Adobe Premiere Pro (beta) and Adobe Media Encoder now support 4:2:2 color format, enhancing color accuracy and keying. NVIDIA GeForce RTX 50 Series laptops with Blackwell architecture accelerate advanced AI-powered features for video editing workflows.

AI models are replacing traditional algorithms in algorithmic pipelines due to their higher resource requirements. Centralized inference servers may improve efficiency in processing large-scale inputs through deep learning models, as shown in a toy experiment using a ResNet-152 image classifier on 1,000 images.

AI can enhance job search success, but requires a delicate balance with human interaction. Don't miss out on opportunities by underestimating AI's potential impact.

Graph Convolutional Networks (GCNs) and Graph Attention Networks (GATs) have limitations with large graphs and changing structures. GraphSAGE offers a solution by sampling neighbors and using aggregation functions for faster and scalable training.

GitHub Actions, a CI/CD tool, is not just for software - it automates data workflows, from setting up environments to deploying ML models. Free and easy to use, it offers pre-built actions and community support for automating tasks within repositories.
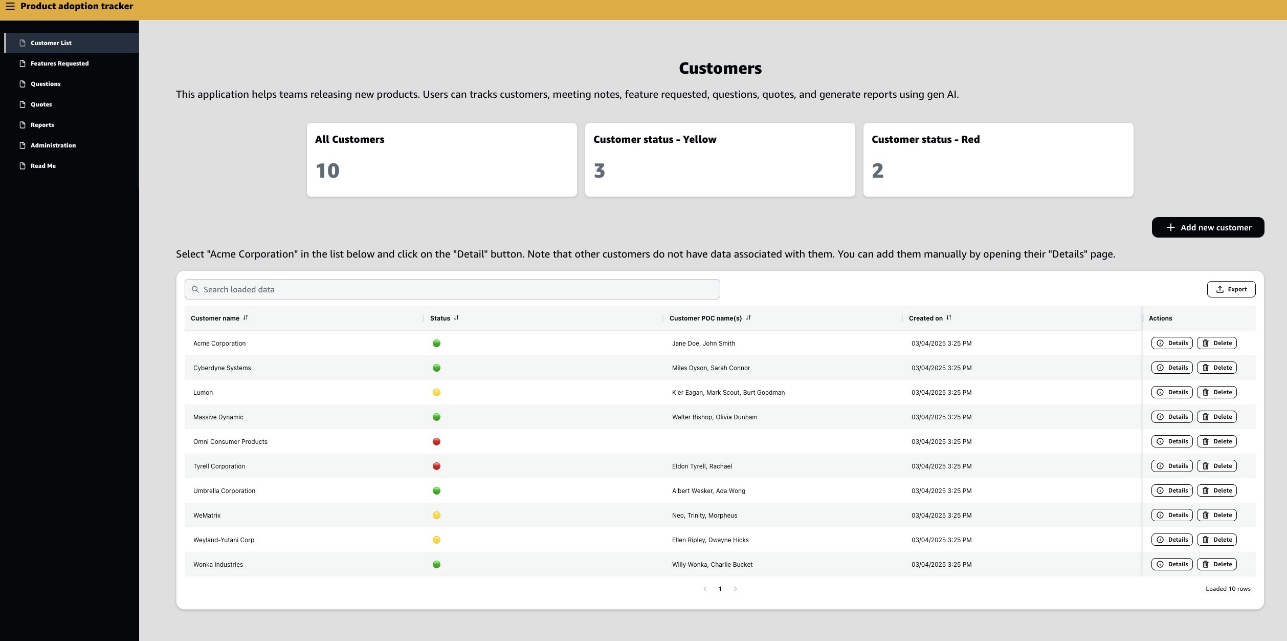
AWS App Studio is an AI-powered service enabling quick application development for various industries. New features like Prebuilt solutions catalog and Cross-instance Import and Export streamline the process, reducing setup time to under 15 minutes.
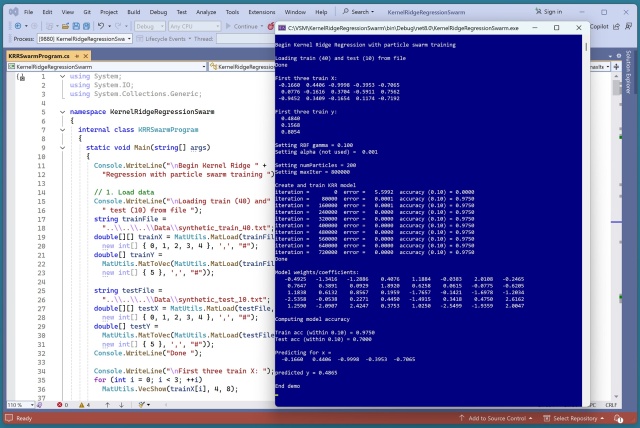
Algorithm combining PSO with EO, EPSO, performs similarly to PSO and EO, not significantly better. Slow for practical use, but shows promise in training a KRR prediction system.
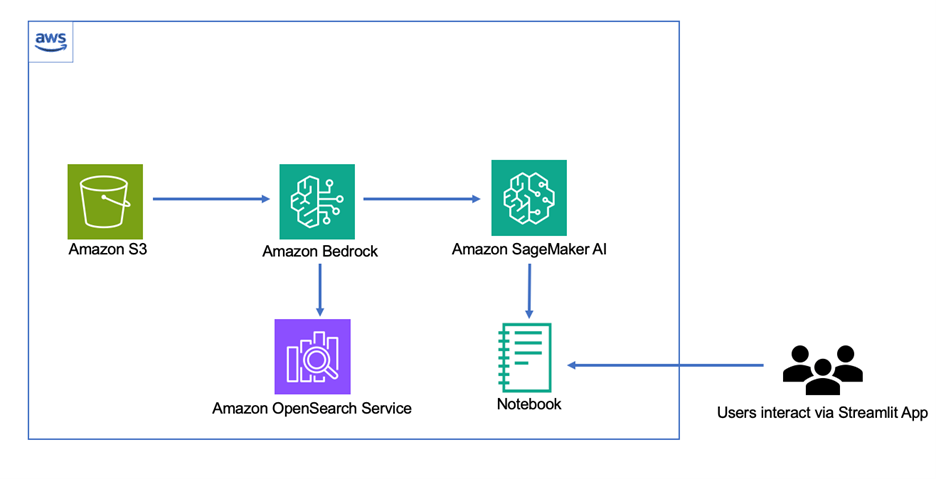
Generative AI boosts content creation efficiency. Constitutional AI and LangGraph ensure ethical behavior in AI systems, enhancing transparency and compliance in content generation processes.

Tony Blair Institute advises UK to relax copyright laws for AI innovation, warns of strain on US relations and potential tariffs. Enforcing stricter licensing rules may threaten national security interests, says thinktank.

MIT's Pattie Maes awarded 2025 ACM SIGCHI Lifetime Research Award for human-computer interaction contributions, advocating for human-centered AI integration. Maes' pioneering work in software agents and wearable devices shapes today's online experience, emphasizing ethical design and human experience enhancement.

ChatGPT gained one million users in five days, sparking interest in AI. Foundation models are key to understanding generative AI's capabilities and applications.

AI is a tool, not a genius, reshaping storytelling with collaboration. It can provoke feeling and lead to knowing in the writer.