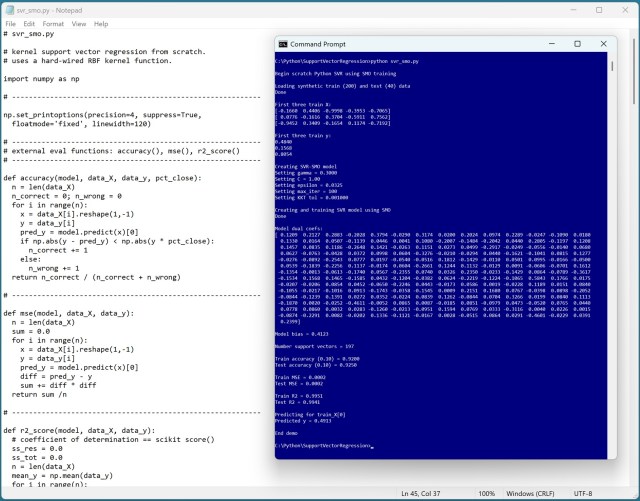
Implementing kernel SVR using Python, the author shares a demo with synthetic data and reveals SVR complexities compared to KRR. The SMO training algorithm and its intricate details are highlighted, showcasing the challenges and uniqueness of SVR implementation.
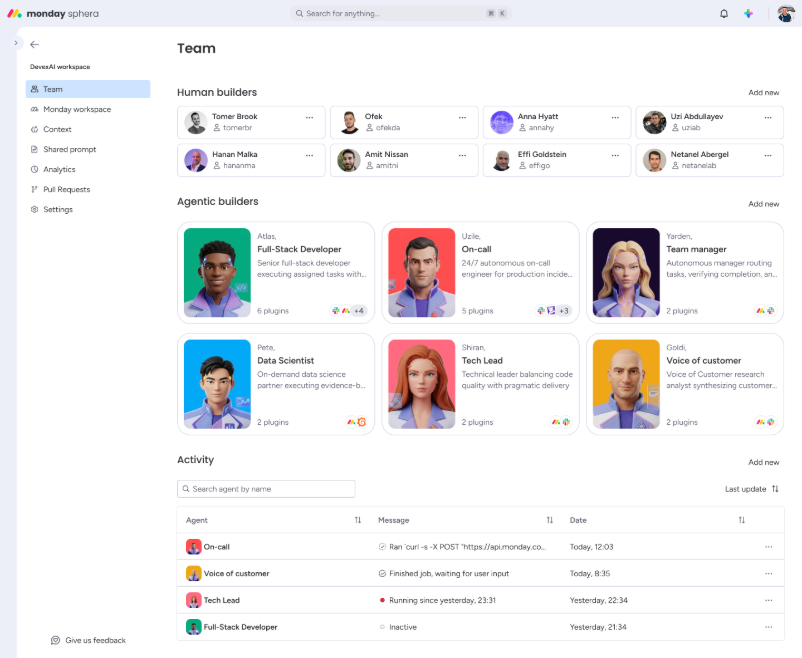
AI Teammates on Amazon Bedrock at monday.com have boosted PR throughput by over half, using AI coding tools at scale in a decade-old code base. Agents at monday are fully agentic, working alongside humans as teammates, not just tools, with a three-level AI engineering journey and innovative architecture using AWS services.
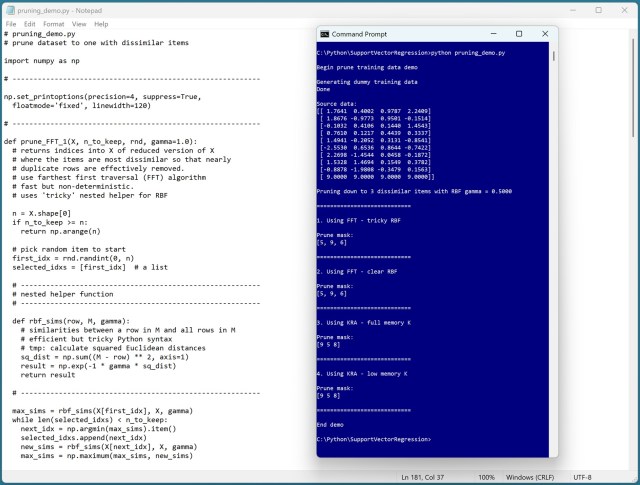
A unique challenge in condensing training data using RBF similarity led to the creation of FFT and KRA pruning functions in Python. FFT prioritizes dissimilarity for efficiency, while KRA ranks items based on average similarity for clarity.

Dimitri Bertsekas, influential professor in EECS at MIT, passed away at 83. Known for pioneering work in optimization and mentoring future leaders in the field.

NVIDIA CEO Jensen Huang commissions powerful AI platform at Naval Postgraduate School, enabling students and faculty to access large-scale computing for real-world applications like weather prediction and cybersecurity. Collaboration with NPS aims to educate leaders in AI technologies, emphasizing the importance of engaging with and leveraging advancements in computing.

NVIDIA Vera Rubin platform revolutionizes AI factories with extreme codesign across chips and rack trays, delivering unprecedented performance and efficiency. Leading companies like CoreWeave, Microsoft, and Tesla are already leveraging Vera Rubin's purpose-built networking for accelerated AI production.

Amazon Nova 2 models excel in reasoning, enhancing prediction performance on challenging tasks like coding and math. Self-Distilled Reasoning (SDR) mitigates catastrophic forgetting, improving target performance without compromising general performance.
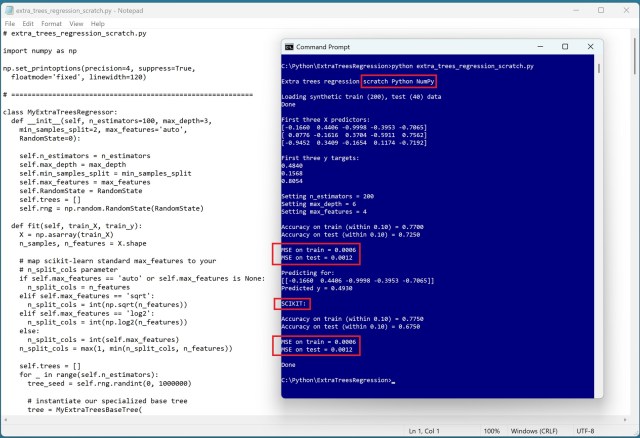
Extra Trees Regressor is an ensemble ML algorithm predicting continuous values with greater randomization than Random Forests. Implementing it from scratch in Python yielded results close to scikit-learn's module, showcasing its subtle yet tricky implementation.
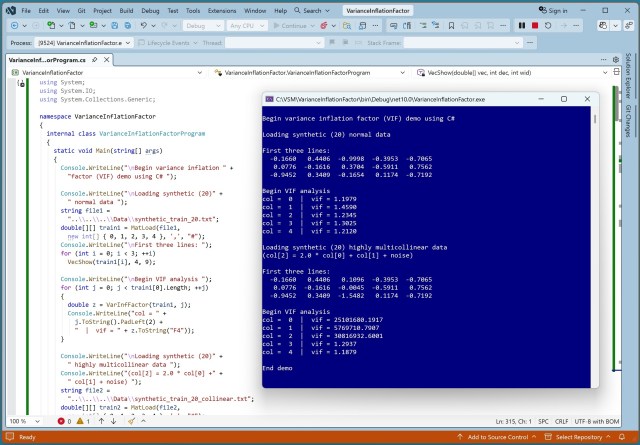
Multicollinear training data impacts model interpretability. VIF helps detect correlation levels. Refactoring Python demo to C# required implementing linear regression class and helper functions.

Developers can now customize AWS DeepRacer devices with a new bootloader, extending device life. The bootloader allows for installation of custom operating systems, modern Linux distributions, and more, providing flexibility and innovation for developers.

At SIGGRAPH, NVIDIA showcases AI advancements in neural rendering, world models, and simulation techniques. NVIDIA leaders discuss how these technologies are revolutionizing digital world creation and usage across various industries.
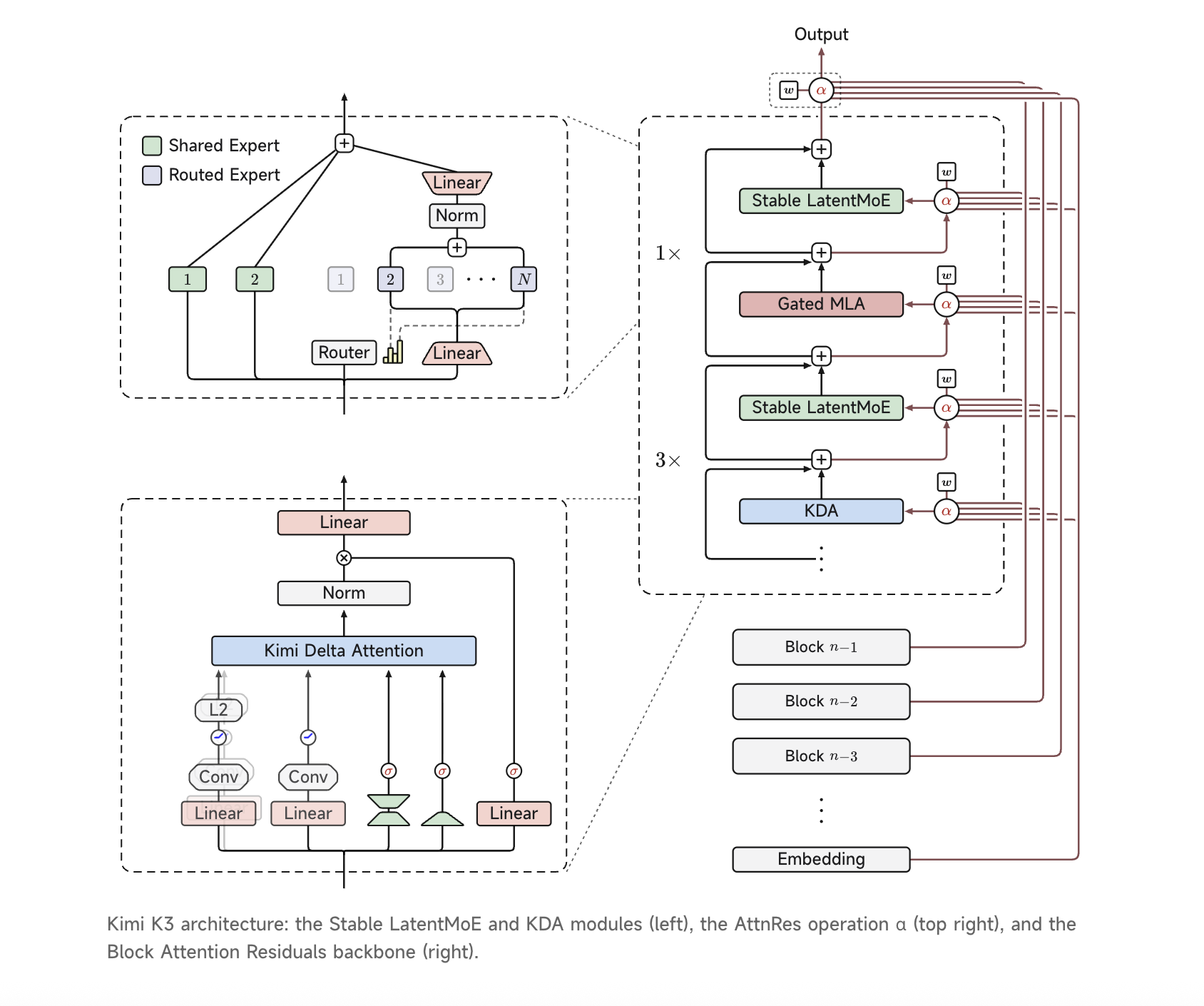
Moonshot AI introduces Kimi K3, a groundbreaking 2.8-trillion-parameter model with innovative architectural updates. K3 outperforms other models, offering improved efficiency and scaling in long-horizon coding and reasoning tasks.
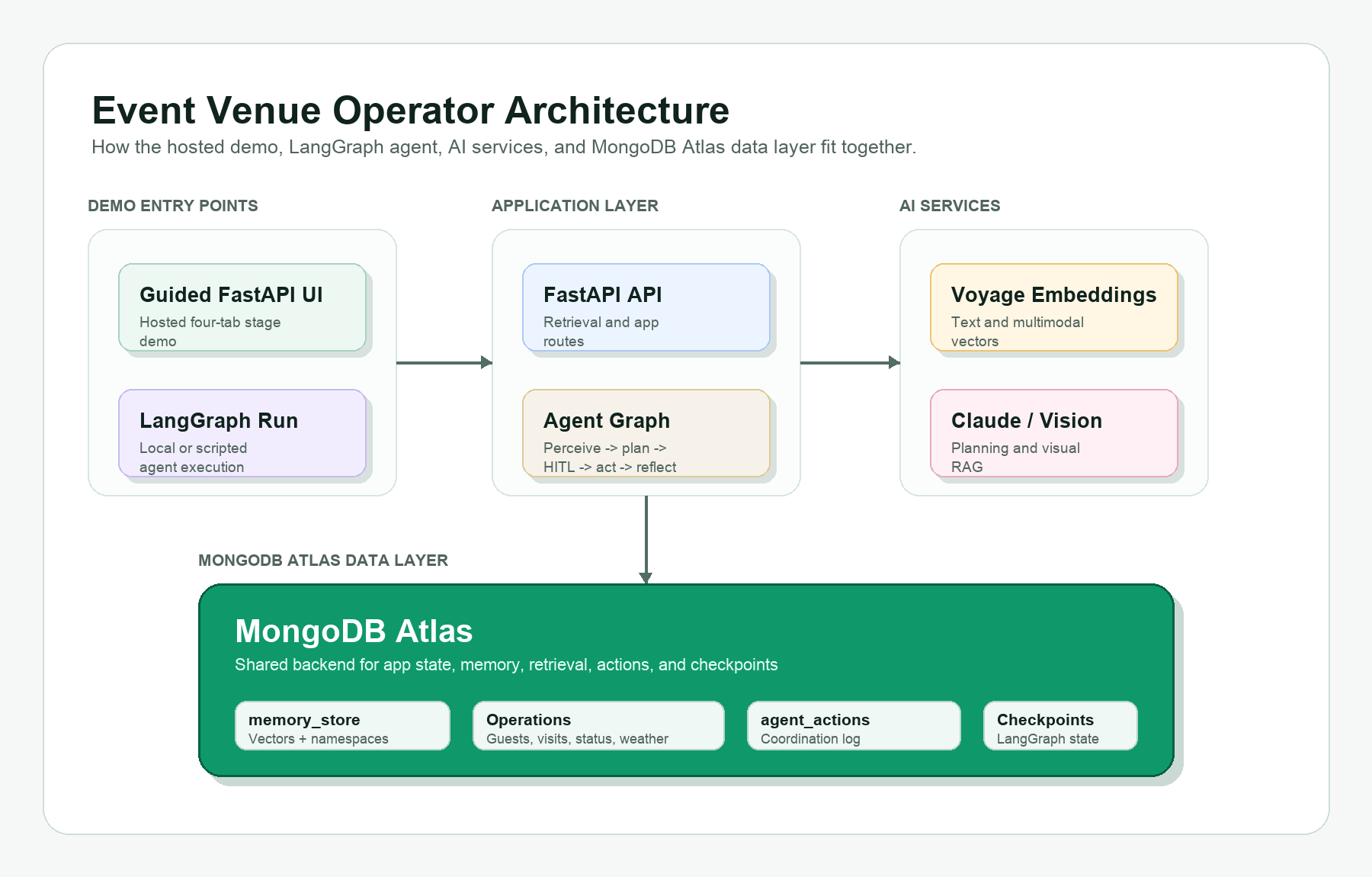
Build a sophisticated event-venue operator demo using MongoDB Atlas, Voyage AI embeddings, and LangGraph. Explore the complexities of managing a premium tennis tournament with high fan expectations and potential weather risks.

Bailey Flanigan's diverse interests led her from medicine to music to computational democracy research. Her journey across disciplines at top institutions shapes her innovative approach to meaningful democratic participation.
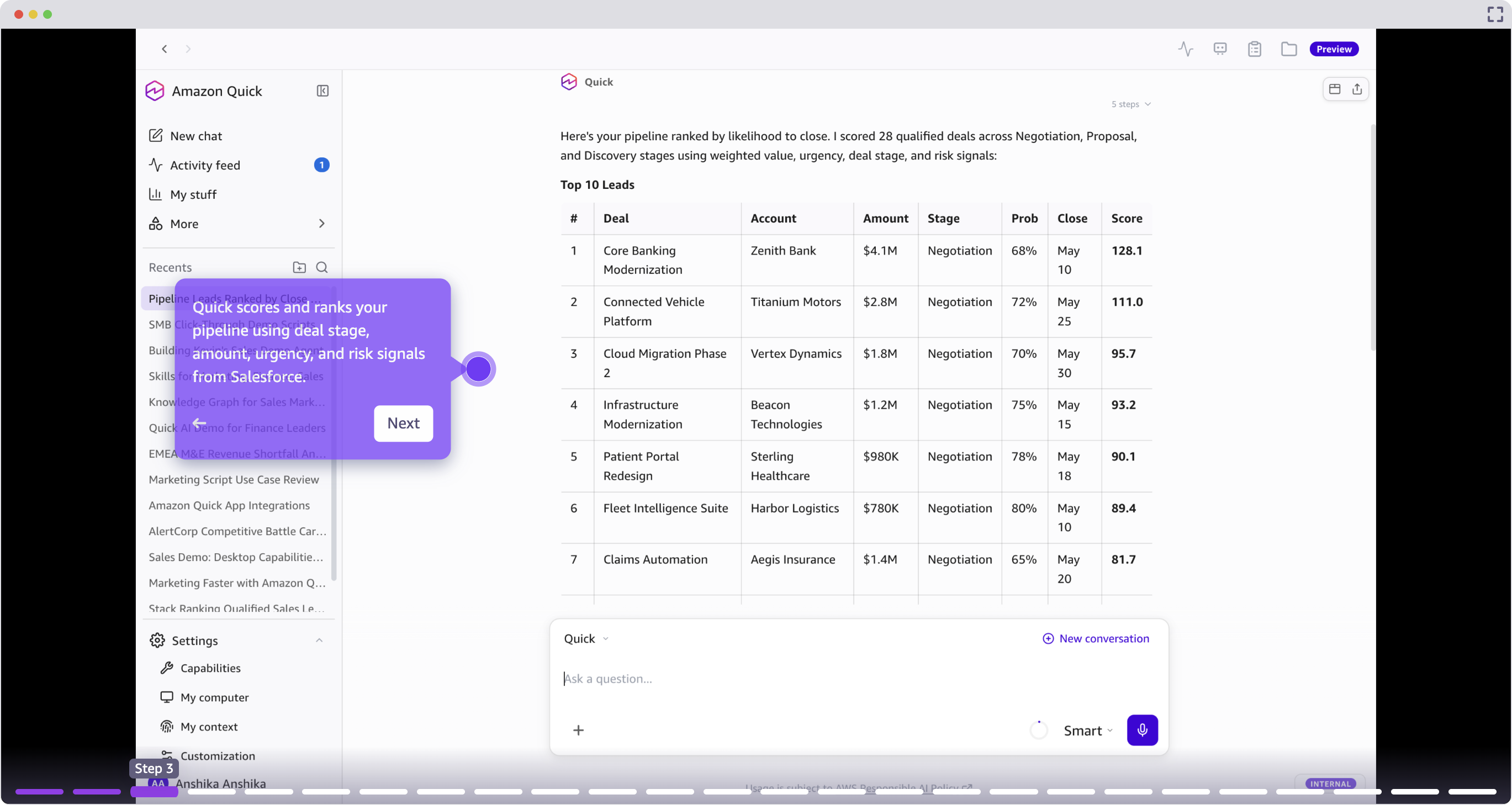
Amazon Quick is an AI assistant that helps sales reps spend more time selling and less on admin tasks. Companies like 3M and AWS are already using Quick to prioritize high-intent prospects and close deals faster.