
Откройте для себя шесть увлекательных статей прошлой недели, которые стоит прочитать в эти выходные. Будьте в курсе последних актуальных тем и оставайтесь в курсе событий.

ManticAI преуспевает в Metaculus Cup, вызывая дискуссию о точности прогнозов искусственного интеллекта и человека. Бывший исследователь Google DeepMind, соучредитель британского стартапа, занял 8-е место в международном конкурсе.
Искусственный интеллект теперь является стратегическим партнером в процессе принятия решений, что требует тщательного выбора и обучения для выполнения конкретных задач. Подключение агентов к источникам данных имеет решающее значение для получения точных ответов, учитывающих контекст, а также для сохранения институциональных знаний внутри организаций.
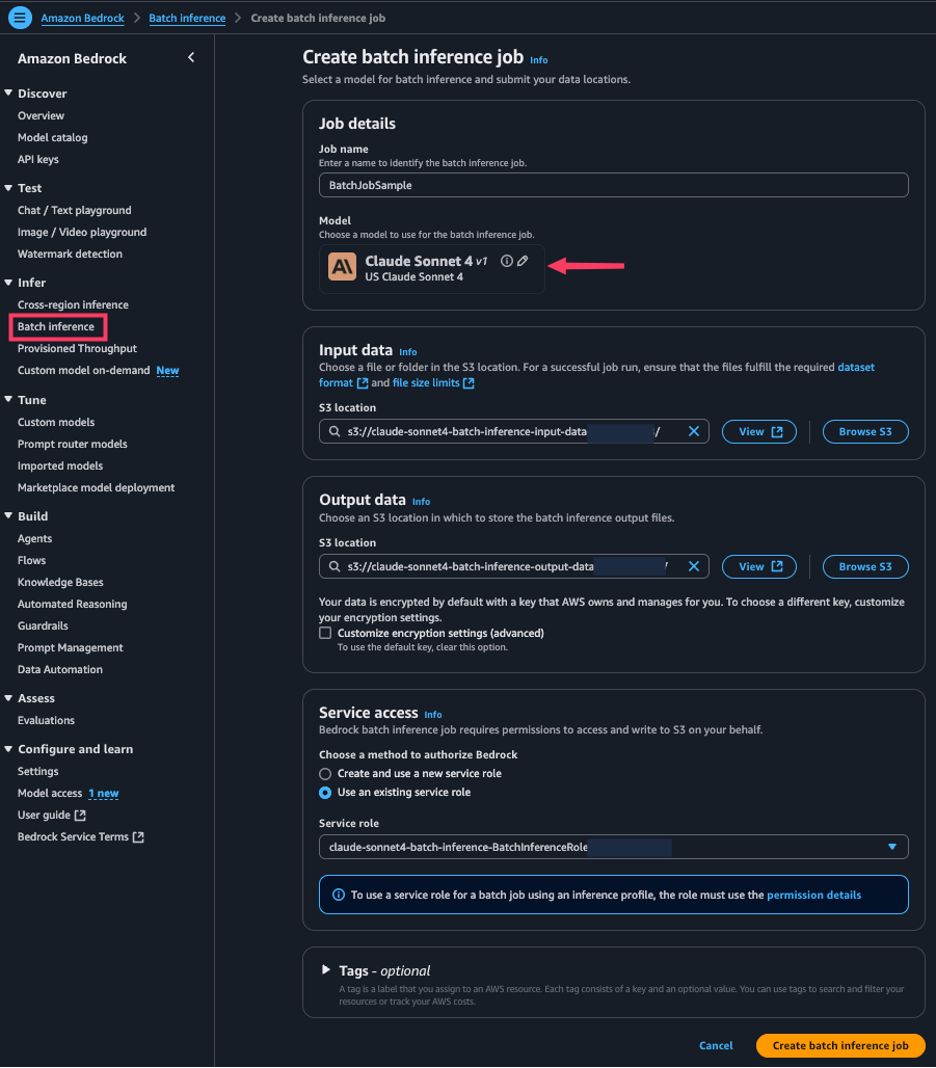
Amazon Bedrock batch inference предлагает экономичную массовую обработку больших наборов данных, идеально подходящую для анализа исторических данных и резюмирования текстов. Новые функции включают расширенную поддержку моделей и повышение производительности, а также возможности мониторинга заданий для оптимизации эффективности.

Новый инструмент искусственного интеллекта предсказывает риск развития 1000 заболеваний. Возвращение додо или неандертальцев? Интересные возможности.
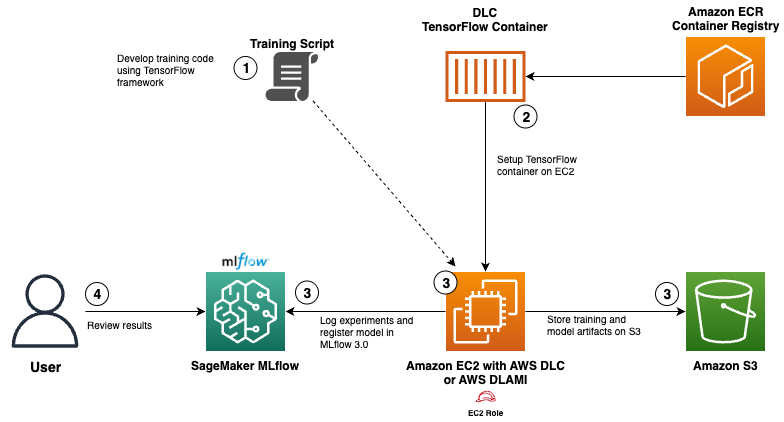
Контейнеры AWS Deep Learning Containers (DLC) и управляемый MLflow на Amazon SageMaker AI предлагают решение для организаций со специальными требованиями к машинному обучению. DLC предоставляют предварительно настроенные контейнеры Docker с оптимизированными фреймворками, а управляемый SageMaker MLflow оптимизирует управление жизненным циклом с помощью расширенных возможностей.

Massive Attack удаляет свою музыку из Spotify из-за инвестиций генерального директора в военные ИИ-технологии. Они присоединяются к кампании «No Music for Genocide» против Израиля.

Италия принимает новаторский закон об искусственном интеллекте, предусматривающий тюремное заключение за вредное использование и ограничивающий доступ детей. Правительство Джорджии Мелони приводит законодательство в соответствие с законом ЕС об искусственном интеллекте, чтобы регулировать использование технологий в Италии.

Джонни Геллер предупреждает об угрозе искусственного интеллекта для ремесла рассказчика, поскольку крупные технологические компании получают прибыль от материалов, защищенных авторским правом. Британская издательская индустрия стоимостью 11 миллиардов фунтов стерлингов

Amazon Bedrock представляет Stability AI Image Services, предлагающий 9 инструментов для точного создания и редактирования изображений. Мощные подсказки контролируют такие элементы, как тон и текстура, максимально повышая визуальные результаты для профессиональных нужд.

ChatGPT от OpenAI вызвал широкое распространение генеративного ИИ в различных отраслях. Симпозиум MGAIC Массачусетского технологического института исследует будущий потенциал и этические проблемы генеративного ИИ, уделяя особое внимание разработке моделей мира для более интеллектуальных систем ИИ.
Исследование Кембриджского университета посвящено влиянию игрушек с искусственным интеллектом на развитие детей и их право на неприкосновенность частной жизни. Вопросы, поднятые в связи с игрушками с искусственным интеллектом, касаются подтверждения любви, обмена разговорами и интерпретации социальных сигна

Модель искусственного интеллекта Gemini 2.5 от Google DeepMind достигла исторического прорыва, решив реальную проблему и завоевав золотую медаль на международном конкурсе. Это событие, сопоставимое с победой Deep Blue и искусственного интеллекта над чемпионом мира по игре в го, демонстрирует возможности искусственного интеллекта.

Nvidia, OpenAI и Microsoft инвестируют миллиарды в связи с визитом Трампа. Среди гигантов Кремниевой долины выделяется Microsoft, которая обязалась инвестировать в Великобританию 30 млрд долларов.

Дженсен Хуанг из Nvidia инвестирует 500 млн фунтов стерлингов в британскую компанию NScale, прогнозируя, что Великобритания станет будущей сверхдержавой в области искусственного интеллекта с потенциальным доходом в 50 млрд фунтов стерлингов. Хуанг подчеркивает потенциал Великобритании в области искусственного интеллекта, приобретая долю в британской компании, занимающейся облачными вычислениями.