
Scuderia Ferrari HP и AWS сотрудничают, чтобы революционизировать анализ пит-стопов с помощью машинного обучения, оптимизируя производительность и эффективность в Формуле 1®. AWS помогает модернизировать процесс, автоматизируя синхронизацию видео и телеметрических данных, что позволяет быстрее проводить анализ и выявлять ошибки.

Математические навыки важны для исследовательских должностей в таких компаниях, как Deepmind и Google Research, в то время как для промышленных должностей требуется меньшая глубина знаний. Высшее образование коррелирует с более высокими заработками в сфере машинного обучения.
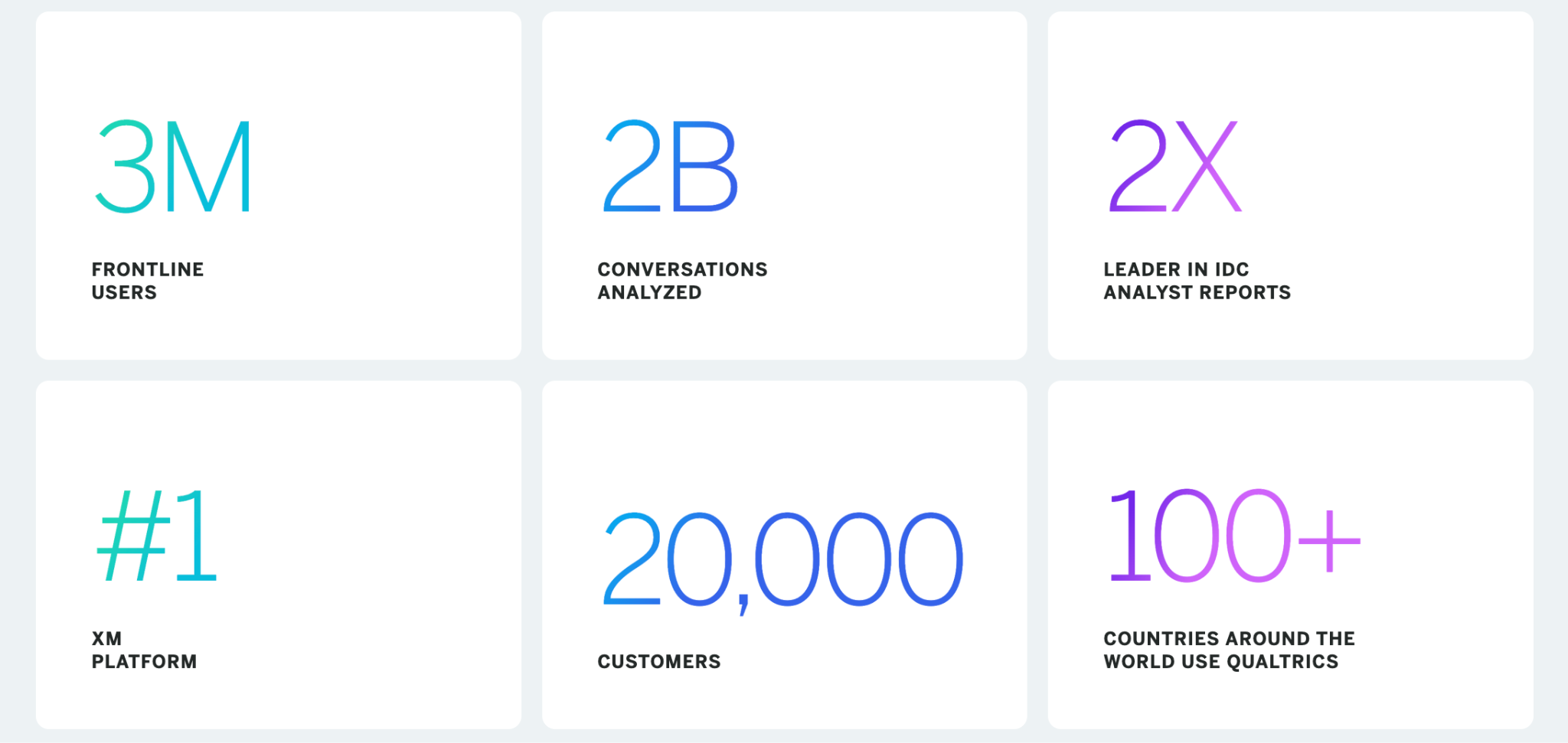
Компания Qualtrics является первопроходцем в области управления опытом (XM) с использованием возможностей искусственного интеллекта, ML и NLP, повышающих связь с клиентами и их лояльность. Платформа Socrates компании Qualtrics, работающая на базе Amazon SageMaker, способствует инновациям в области управления опытом с помощью передовых технологий ML.
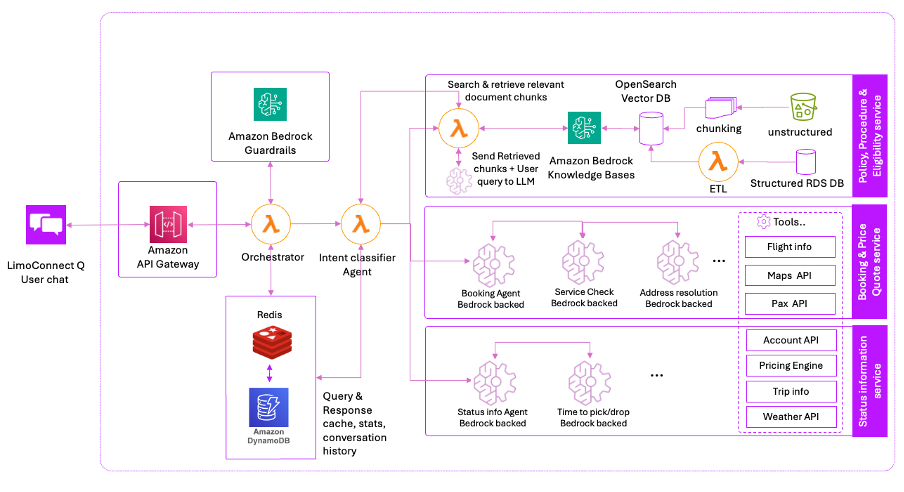
Компания Vxceed интегрирует генеративный искусственный интеллект в свои решения и запускает LimoConnectQ с использованием Amazon Bedrock для улучшения качества обслуживания клиентов и повышения операционной эффективности в сфере безопасного управления наземным транспортом. Задача: найти баланс между инновациями и безопасностью, чтобы соответствовать строгим нормативным требованиям государствен...

Объединенные Арабские Эмираты и США подписывают соглашение о создании крупного кампуса искусственного интеллекта, вызывая опасения по поводу влияния Китая. Соглашение подчеркивает изменения в партнерстве в области ИИ при администрации Трампа.

Новая поправка к законопроекту о данных требует от компаний, занимающихся искусственным интеллектом, раскрывать информацию об использовании контента, защищенного авторским правом, что противоречит ранее отклоненной версии. Предложение депутата Бибана Кидрона направлено на то, чтобы ограничить использование компаниями ИИ работ, защищенных авторским правом, без разрешения.

Марк Цукерберг пропагандирует искусственный интеллект для человеческих отношений, представляя себе будущее, в котором люди будут дружить с алгоритмами. Несмотря на скептицизм, некоторые уже заявляют о реальных связях с ИИ-терапевтами и чат-ботами.

Google DeepMind представила AlphaEvolve, систему искусственного интеллекта, которая эволюционирует код, открывая новые алгоритмы кодирования и анализа данных. Используя генетические алгоритмы и Gemini Llm, AlphaEvolve подсказывает, мутирует, оценивает и размножает код в поисках оптимальных решений.

Статья на Pure AI упрощает процесс преобразования больших языковых моделей ИИ с помощью аналогии с фабрикой, делая его доступным для неинженеров и бизнес-профессионалов. Аналогия разбивает процесс на такие этапы, как вход в погрузочный док, сортировка материалов и конечная сборка, предлагая четкое понимание того, как работают трансформеры.
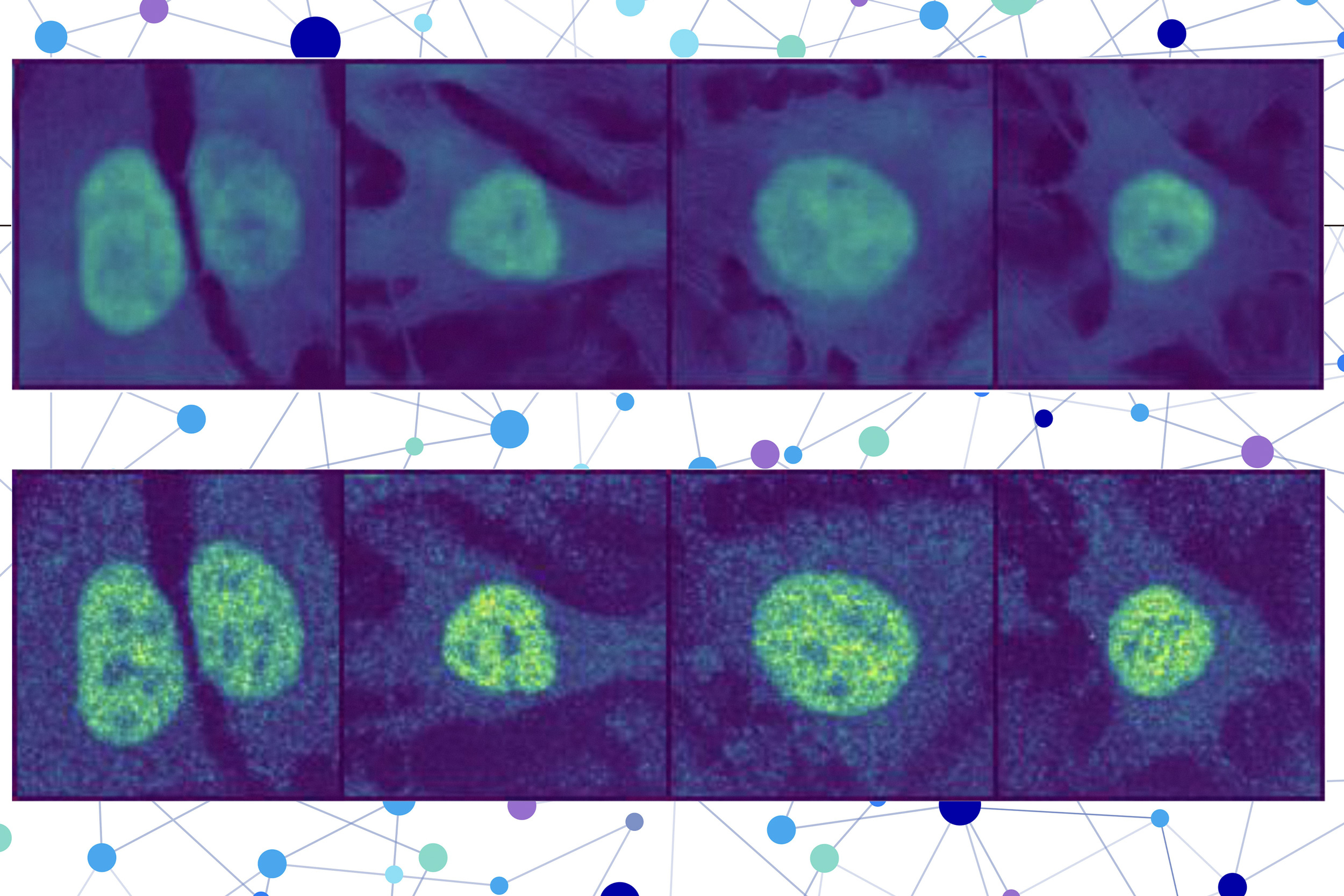
Новый вычислительный подход предсказывает расположение белков в клетках, помогая в диагностике заболеваний и определении мишеней для лекарств. Исследователи из Массачусетского технологического института, Гарварда и Института Брод разработали метод локализации белков в одной клетке с помощью моделей искусственного интеллекта.

Специалист по анализу данных подчеркивает важность контрольных показателей в проектах по науке о данных. Контрольные показатели обеспечивают повышение производительности и помогают в общении с клиентами и выборе моделей.

Bagging и boosting - важнейшие методы ансамблевого анализа в машинном обучении, повышающие устойчивость моделей и снижающие погрешность слабых обучаемых. Ансамбли объединяют прогнозы нескольких моделей для создания мощных моделей, при этом bagging уменьшает дисперсию, а boosting итеративно улучшает ошибки.
Банки борются с неэффективностью обработки документов, но решение SuperAcc от Apoidea Group, основанное на искусственном интеллекте, сокращает время обработки документов более чем на 80 %. Передовые системы извлечения информации SuperAcc оптимизируют процесс привлечения клиентов, соблюдения нормативных требований и цифровой трансформации в банковском секторе.
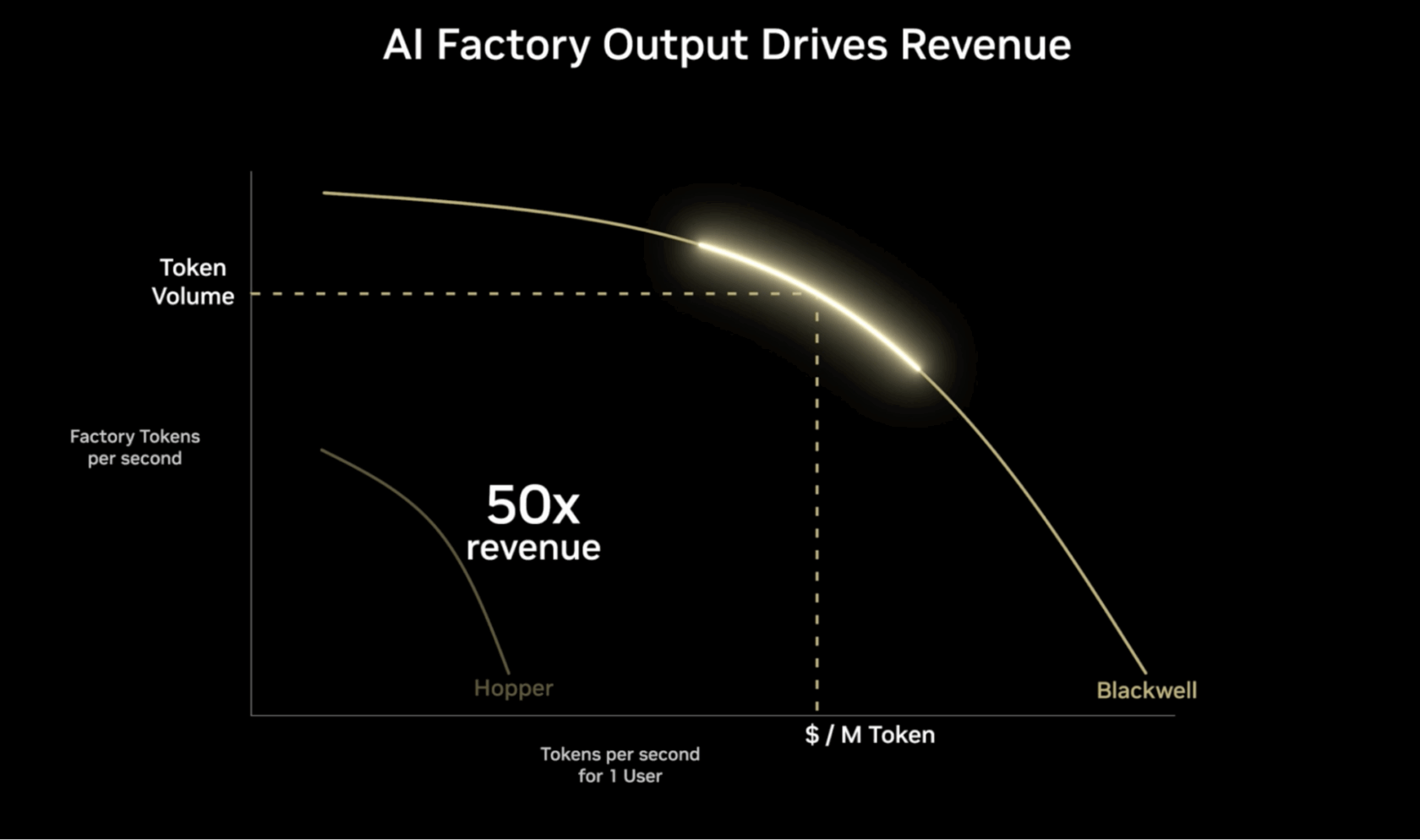
ИИ-фабрики меняют экономику современной инфраструктуры, производя ценные токены в масштабе. Пропускная способность, задержка и пропускная способность являются ключевыми показателями для создания интересного пользовательского опыта и максимизации потенциального дохода на токен.

Задача Монти Холла ставит под сомнение обычную интуицию в принятии решений. Изучив различные аспекты этой головоломки с точки зрения вероятности, мы сможем улучшить процесс принятия решений на основе данных. Придерживаться первоначального выбора или поменять дверь? Ответ может вас удивить.