
С ноября 2025 года в Amazon SageMaker AI будет внедрена функция двунаправленной потоковой передачи данных для преобразования речи в текст в режиме реального времени. API vLLM Realtime от Mistral AI обеспечивает бесперебойную двунаправленную потоковую передачу данных между клиентом и сервером для развертывания компактных моделей распознавания речи в режиме реального времени, предлагая полностью...
Новые средства оценки MLLM-as-a-Judge в Strands Evals SDK оптимизируют задачи преобразования изображений в текст, при этом прогнозируется, что к 2030 году 80 % корпоративного программного обеспечения будет мультимодальным. Автоматизированная мультимодальная оценка повышает точность и эффективность разработки программного обеспечения.

Исследователь из Массачусетского технологического института (MIT) Коннор Коули использует искусственный интеллект для выявления потенциальных низкомолекулярных лекарственных препаратов из огромного множества возможных соединений, сочетая в своей работе достижения химической инженерии и информатики. В своей работе Коули объединяет методы машинного обучения и хемоинформатики с целью оптимизации ...
Использование модели StackingRegressor с несколькими базовыми моделями для прогнозирования может оказаться чрезмерно сложной задачей из-за огромного количества задействованных параметров. Демонстрация, в которой модель StackingRegressor применялась к набору данных по диабету, продемонстрировала сложности, связанные с точным прогнозированием целевого значения уровня сахара у пациентов.
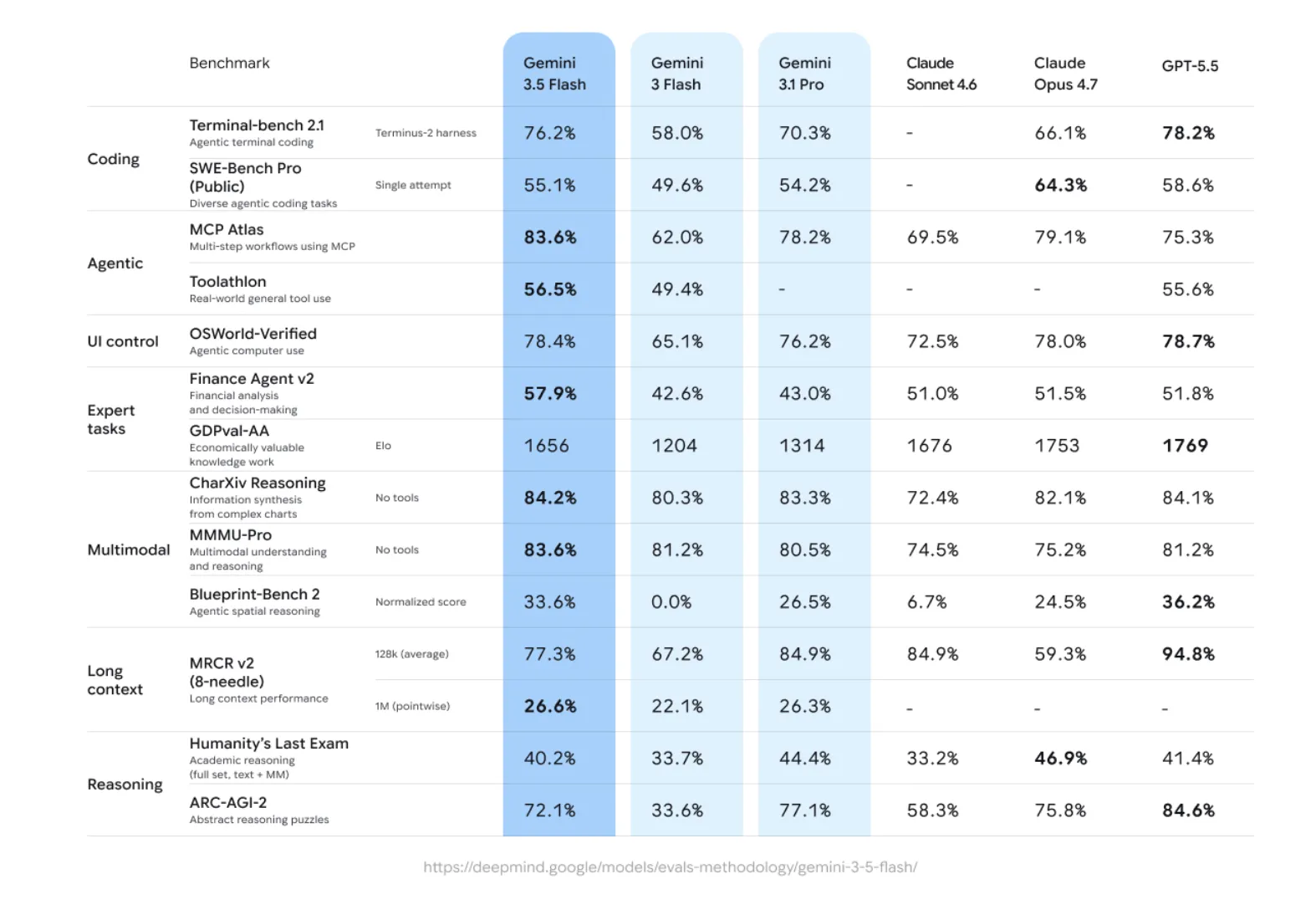
Компания Google представила модель Gemini 3.5 Flash на конференции Google I/O в мае 2026 года, превзойдя предыдущий премиальный уровень благодаря более высокой скорости и сниженной стоимости. Gemini 3.5 Flash демонстрирует отличные результаты в области программирования, выполнении задач, надежности использования инструментов и понимании мультимодальных данных, обеспечивая более быструю обработк...

Amazon SageMaker AI теперь поддерживает API, совместимый с OpenAI, для конечных точек инференса в реальном времени, что упрощает вызов моделей с помощью стандартных SDK. Такие пользователи, как Caffeine.AI, могут легко интегрировать SageMaker в качестве готового к использованию конечной точки, совместимой с OpenAI, без необходимости внесения изменений в код.
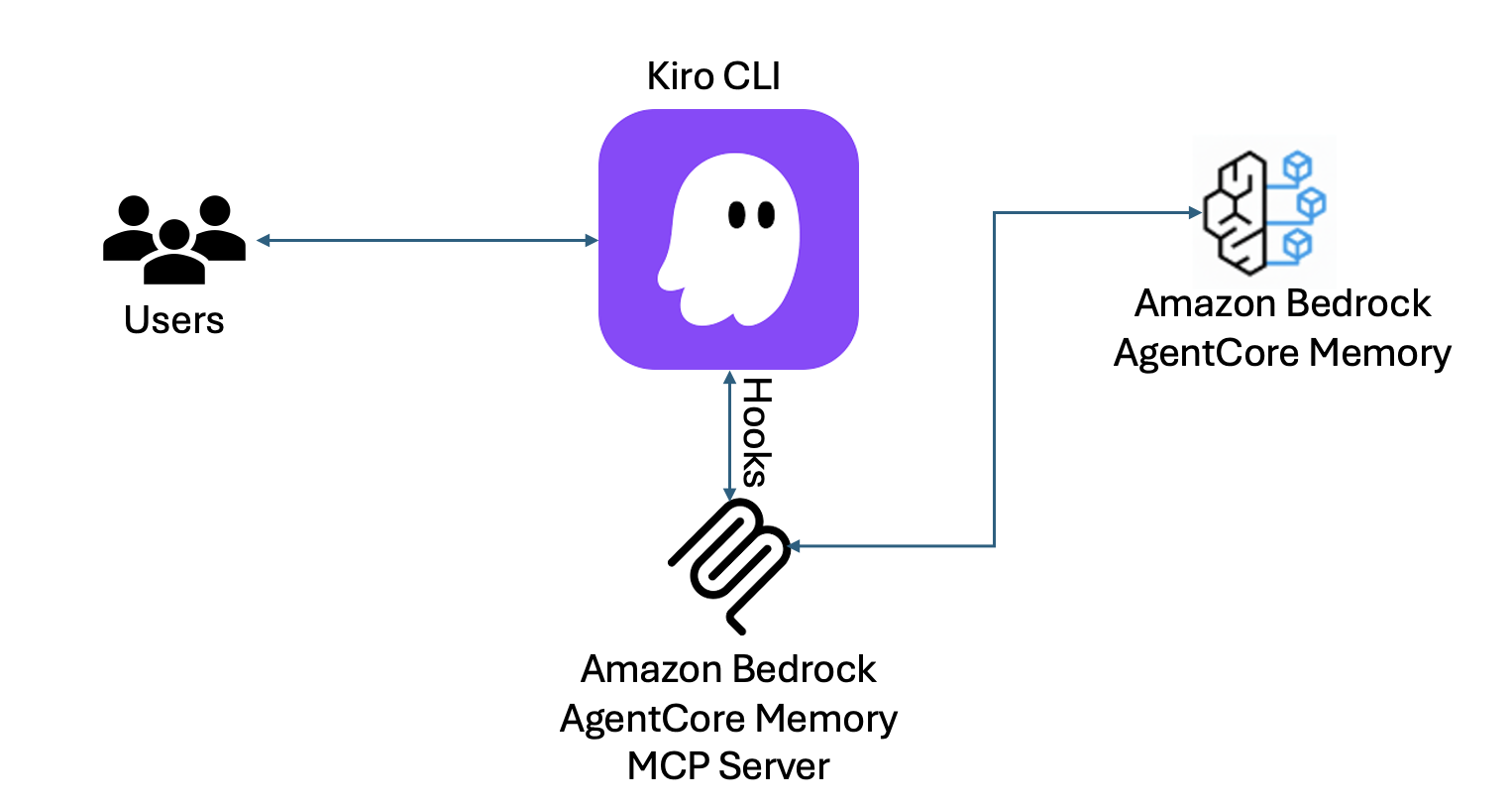
Kiro CLI теперь предлагает расширенную функцию запоминания контекста благодаря интеграции с Amazon Bedrock AgentCore Memory. Настраиваемый сервер MCP обеспечивает сохранение контекста и персонализированный подход к пользователям в разных сеансах.
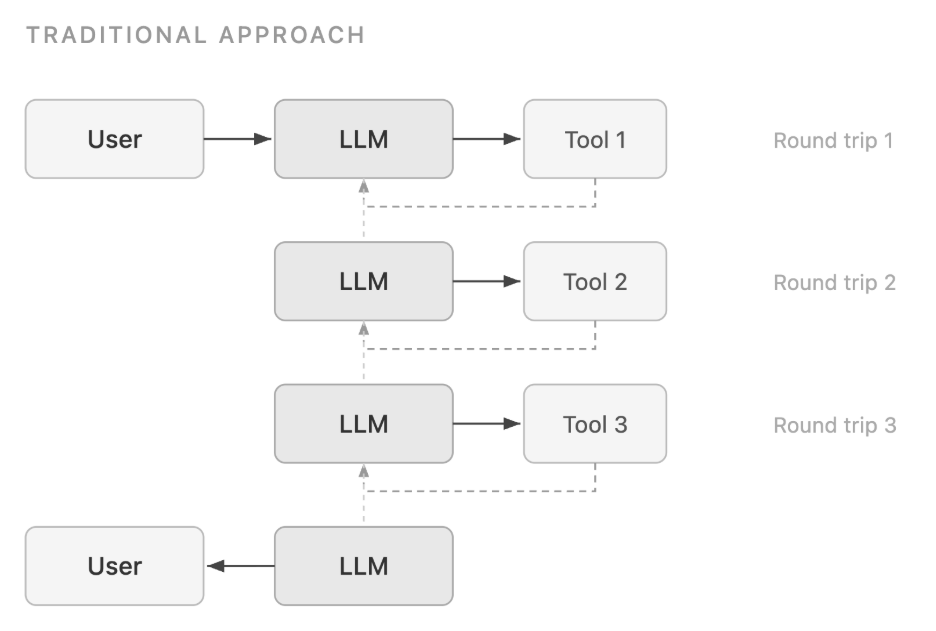
Программный вызов инструментов (PTC) сокращает задержки и снижает потребление токенов, позволяя крупным языковым моделям писать код, который программно вызывает несколько инструментов в изолированной среде выполнения. PTC эффективно применяется для обработки данных, численных вычислений, оркестрации процессов и задач, требующих соблюдения конфиденциальности

Amazon SageMaker Feature Store предлагает новые возможности, в том числе интеграцию с Lake Formation и свойства таблиц Iceberg. Это помогает организациям оптимизировать контроль доступа и сократить расходы на хранение моделей машинного обучения.
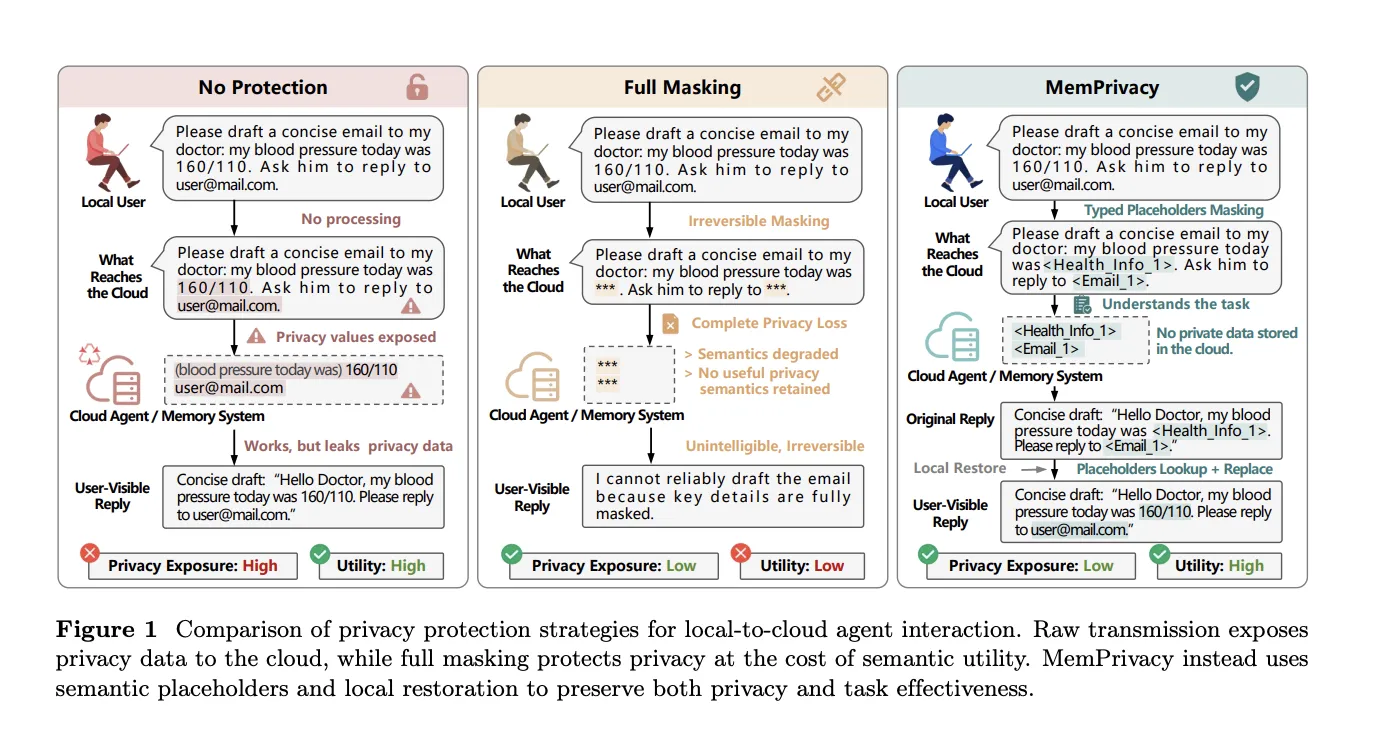
Технология MemPrivacy, разработанная MemTensor, HONOR Device и Университетом Тунцзи, заменяет конфиденциальные данные пользователей структурированными токенами, обеспечивая защиту конфиденциальности при управлении памятью в облаке без ущерба для функциональности или качества отклика. Эта локальная обратимая система псевдонимизации гарантирует семантически неискаженное взаимодействие при одновр...
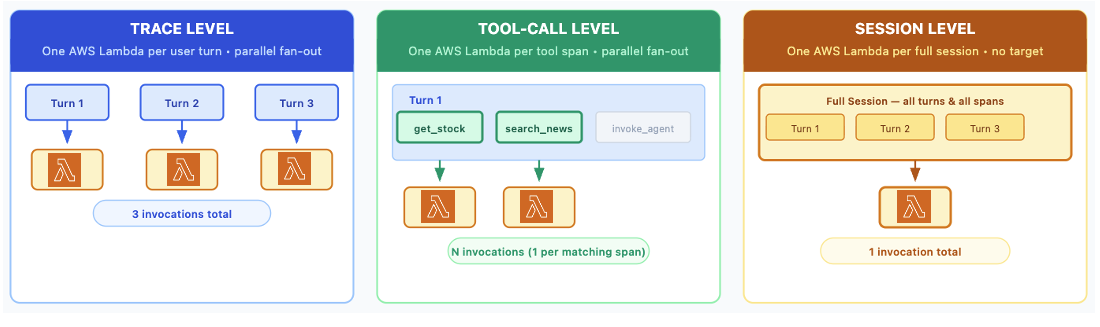
Amazon Bedrock AgentCore Evaluations предлагает настраиваемые оценочные алгоритмы на основе собственного кода для оценки агентных приложений в таких специализированных областях, как финансовые услуги. Эти алгоритмы обеспечивают контроль над логикой подсчета баллов, что позволяет проводить индивидуальную оценку качества агентов и легко интегрировать их в рабочие процессы разработки.

Компания NVIDIA представляет NVFP4 для обучения с использованием 4-битной плавающей запятой, достигая точности 62,58 % на модели Mamba-Transformer и превосходя базовые показатели FP8. NVFP4 оптимизирует динамический диапазон и точность, обеспечивая ускорение выполнения операций GEMM в 2–3 раза по сравнению с FP8 на тензорных ядрах Blackwell.
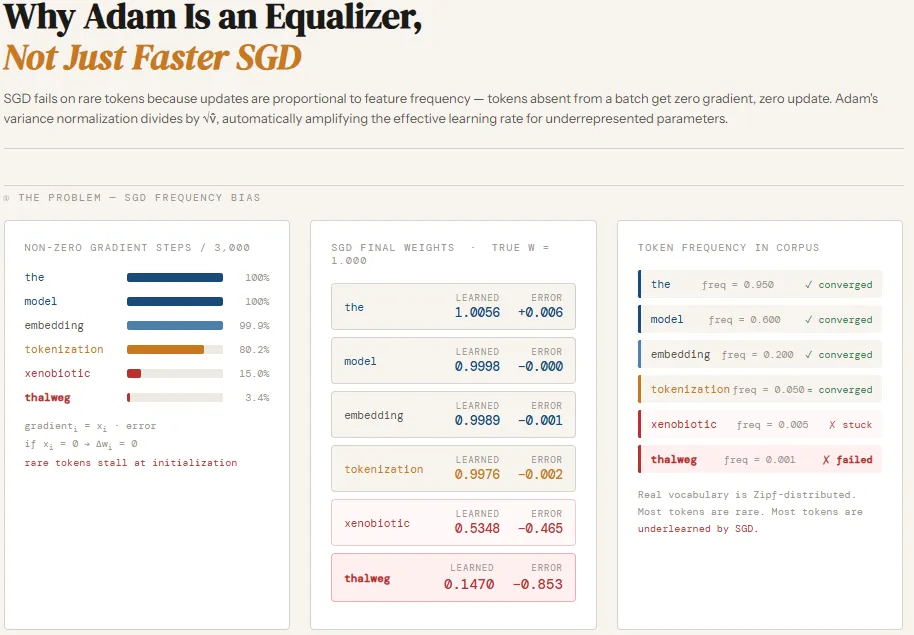
Языковые модели сталкиваются с проблемами оптимизации из-за неравномерного распределения токенов. Адаптивная оптимизация Adam позволяет редким токенам обучаться быстрее, чем при использовании стандартного алгоритма SGD.
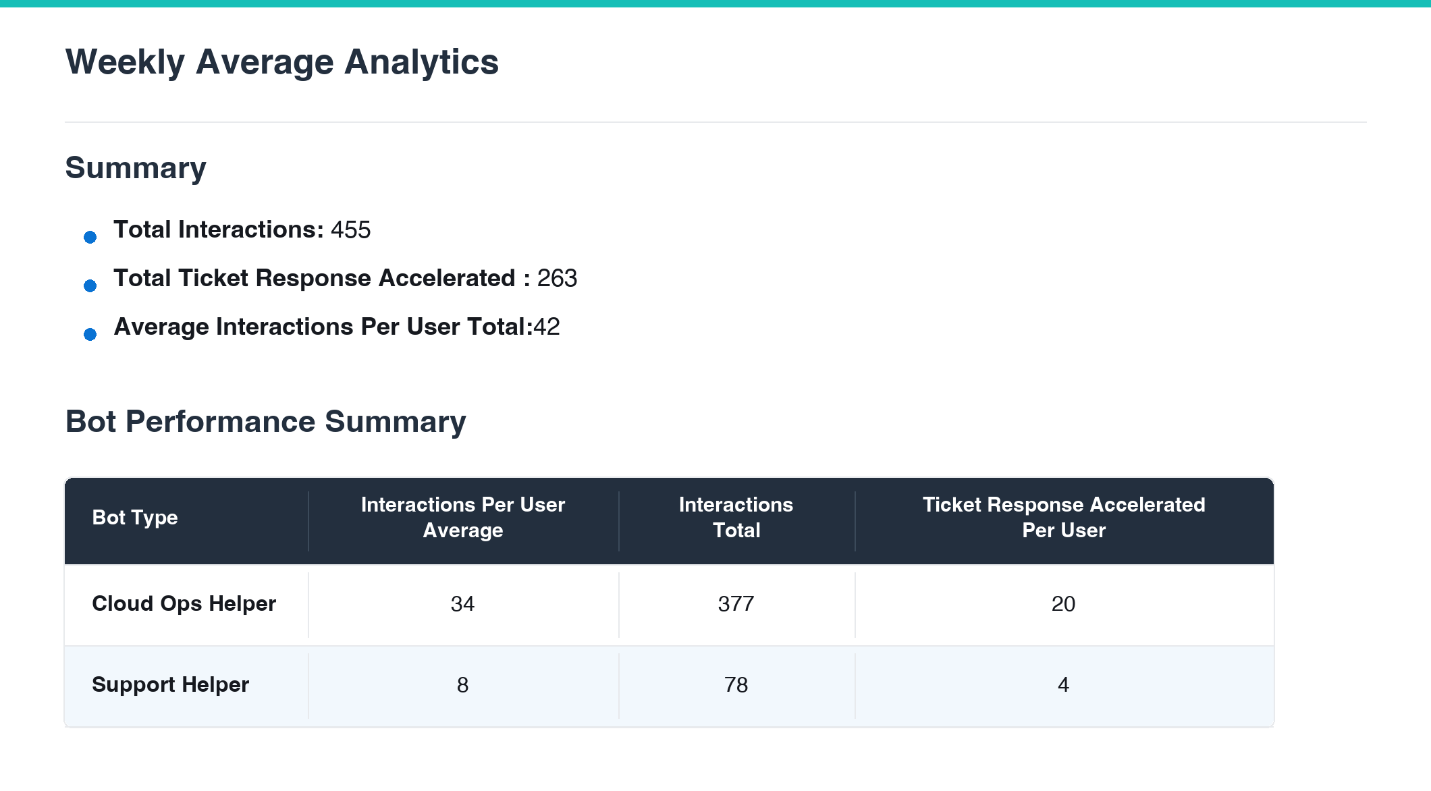
Aderant оптимизирует работу службы поддержки с помощью Amazon Quick, сократив время поиска на 90 % и ускорив подготовку документации на 75 %. Функции на базе искусственного интеллекта объединяют поиск по шести системам, что позволяет инженерам обеспечивать более быструю и оперативную поддержку.
Регрессия AdaBoost использует деревья решений, обученные на взвешенных данных, для повышения точности прогнозов. Результаты показывают переобучение: высокая точность на обучающих данных, но более низкая точность на невиданных тестовых данных.