
Исследователи MIT CSAIL обнаружили, что краткосрочное руководство может значительно повысить производительность ранее считавшихся «неэффективными» нейронных сетей за счет согласования внутренних представлений. В отличие от дистилляции знаний, руководство напрямую передает структурные знания, используя архитектурные предубеждения нетренированных сетей для эффективного обучения.

Технологические компании извлекают выгоду из ИИ, но общество платит за это огромными выбросами углерода, равными выбросам Нью-Йорка. Исследования показывают, что воздействие ИИ на окружающую среду превышает глобальный спрос на бутилированную воду.

Отчет AI Security Institute показывает, что многие люди используют универсальные помощники, такие как ChatGPT и Amazon Alexa. Треть жителей Великобритании обращаются к ИИ за эмоциональной поддержкой, а каждый десятый использует чат-ботов каждую неделю.

После террористической атаки на пляже Бонди платформы заполонила дезинформация, подпитываемая искусственным интеллектом. Среди ложных сведений были утверждения о фальшивой операции и участии актеров, изображающих жертв кризиса.

Члены профсоюза отвергают использование ИИ в искусстве и отказываются от цифрового сканирования, чтобы защитить свое изображение. 99% голосуют против ИИ, если не будут гарантированы меры защиты.

Комиссия по производительности отклонила спорное предложение о разрешении технологическим компаниям использовать материалы, защищенные авторским правом, для обучения искусственного интеллекта. Правительству рекомендовано подождать 3 года, прежде чем пересматривать австралийские правила авторского права и влияние новых технологий.

ИИ ускоряет разработку ML путем определения методов, генерации кода и настройки гиперпараметров, что значительно сокращает время создания модели.

Trump Media and Technology Group объединяется с TAE Technologies в рамках сделки на сумму 6 млрд долларов с целью объединения Truth Social с энергетическими решениями на базе искусственного интеллекта. Это объединение направлено на то, чтобы извлечь выгоду из бума искусственного интеллекта и удовлетворить растущий спрос на энергию.

Разработчики корпоративных решений переходят на использование автономных ИИ-агентов для решения сложных задач. Strands Agents, Amazon Bedrock AgentCore и NVIDIA NeMo Agent Toolkit предлагают мощное решение для проектирования, оркестрации и масштабирования безопасных мультиагентных систем на AWS. Эти инструменты оптимизируют разработку, развертывание и оптимизацию производительности ИИ-агентов ...
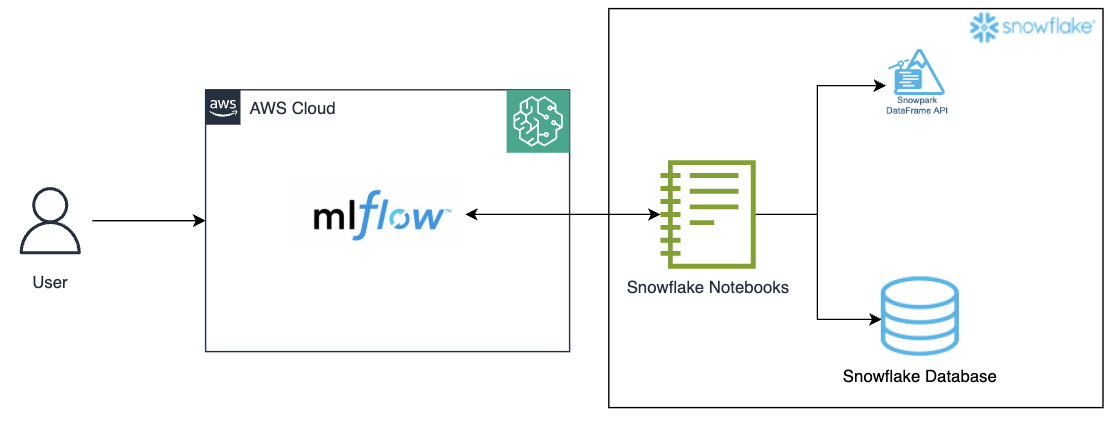
Интегрируйте управляемый Amazon SageMaker MLflow с Snowflake, чтобы оптимизировать рабочие процессы машинного обучения и улучшить совместную работу, ускорив внедрение ИИ/машинного обучения. MLflow Tracking централизует регистрацию экспериментов и управление моделями, повышая прозрачность и эффективность жизненного цикла машинного обучения.

MIT и MIT-IBM Watson AI Lab разрабатывают PaTH Attention, адаптивную технологию кодирования для трансформаторов, устраняющую ограничения в отслеживании состояния. Представленная на NeurIPS, эта разработка направлена на расширение возможностей систем искусственного интеллекта при сохранении масштабируемости и эффективности.

Поиск работы стал изнурительным занятием из-за фальшивых объявлений и запутанных описаний компаний. Только 5% британцев являются безработными, сталкиваясь с отказом и неопределенностью на рынке труда.

Игрушки на базе искусственного интеллекта набирают популярность: в Китае их производит более 1500 компаний. Mattel сотрудничает с OpenAI над созданием новых продуктов, таких как Grem, милый чат-бот.

Amazon ведет переговоры об инвестировании более 10 млрд долларов в OpenAI для финансирования центров обработки данных. Потенциальная оценка OpenAI может превысить 500 млрд долларов.

Миллиардер, генеральный директор Nvidia, подчеркивает мощь искусственного интеллекта на вечеринке в Лондоне во время визита Трампа, вызывая дискуссию о влиянии технологий на политику. Дженсен Хуанг объявляет об инвестициях в искусственный интеллект, вызывая новую промышленную революцию и предоставляя возможности счастливым гостям.