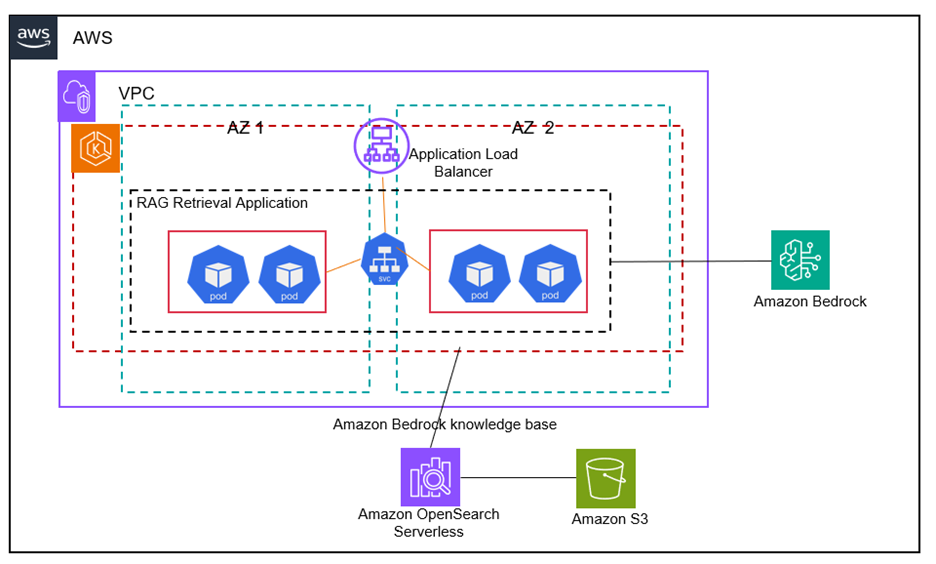
Amazon EKS і Bedrock створюють масштабовані, безпечні рішення RAG для генеративних додатків ШІ на AWS, використовуючи додаткові дані для точних відповідей. Використовуючи керовані групи вузлів EKS, рішення автоматизує виділення ресурсів і ефективно масштабується на основі попиту, підвищуючи продуктивність і безпеку.

Дані навчання ШІ можуть не являти собою Відео з помилками рекрутерів зі штучним інтелектом у TikTok висвітлюють цю проблему.

Нова технологія FaceAge.Age використовує селфі для наукової оцінки старіння, наближаючи персоналізований догляд за шкірою до реальності.

Nvidia продасть сотні тисяч мікросхем штучного інтелекту в Саудівській Аравії, а Cisco співпрацює з G42 з ОАЕ для розвитку сектору штучного інтелекту. Під час турне країнами Перської затоки Трамп заявив про $600 млрд, які Саудівська Аравія зобов'язалася виділити американським технологічним компаніям.

Ініціатива MIT «Формування майбутнього роботи» перетворилася на Центр нерівності Джеймса М. та Кетлін Д. Стоун, який зосереджується на розподілі багатства та впливі технологій на робочу силу. Очолюваний видатними вченими, центр має на меті просувати дослідження, інформувати політиків та залучати громадськість до критично важливих економічних питань.

Навчання лінійного SVR є складним завданням через його недиференційовану функцію втрат, що призвело до вивчення PSO замість еволюційних алгоритмів. Використання PSO для навчання лінійного SVR дало чудові результати, демонструючи важливість налаштування параметрів для оптимізації прогнозуючих моделей.

Протокол Model Context Protocol (MCP) необхідний для інтеграції користувацьких інструментів з Claude Desktop, забезпечуючи централізований спосіб керування інструментами через різні інтерфейси. У порівнянні з традиційними методами, такими як RAG, MCP забезпечує безперешкодну інтеграцію без необхідності створювати власний сервер з нуля.

WebAssembly розширює можливості браузера Бібліотека Pyodide дозволяє запускати код на Python у браузері, що є корисним для дослідників даних та фахівців з машинного навчання.

Ширу Перлмуттер, керівника офісу з авторських прав США, звільнили після звіту про добросовісне використання ШІ. Бібліотекар Конгресу також звільнений.

Палата лордів підтримала поправку до законопроекту про дані, яка змушує ШІ-компанії розкривати інформацію про використання матеріалів, захищених авторським правом, всупереч бажанням уряду. Депутати вимагають прозорості в моделях штучного інтелекту, що є ударом по планах уряду щодо захисту авторських прав.

Керівники технологічних компаній прагнуть автоматизувати всю працю за допомогою штучного інтелекту, отримуючи при цьому заробітну плату. Засновник Fairly Trained попереджає про рішучість еліти замінити людей на робочі місця.

Президент України запросив Папу Римського Лева XIV до України, закликавши ЗМІ припинити поляризацію мови. Лев виступає за відповідальне використання штучного інтелекту в журналістиці.

Стаття досліджує витоки даних в Data Science, акцентуючи увагу на прикладах, а не на теорії. Визначаються типи витоків, такі як витік цілей та забруднення при розбитті тестів, та надаються рекомендації щодо усунення кожного з них.

Останні великі мовні моделі, такі як o1/o3 від OpenAI та R1 від DeepSeek, використовують ланцюжок думок (CoT) для глибокого мислення. Новий підхід, PENCIL, кидає виклик цьому методу, дозволяючи моделям стирати думки, підвищуючи ефективність міркувань.
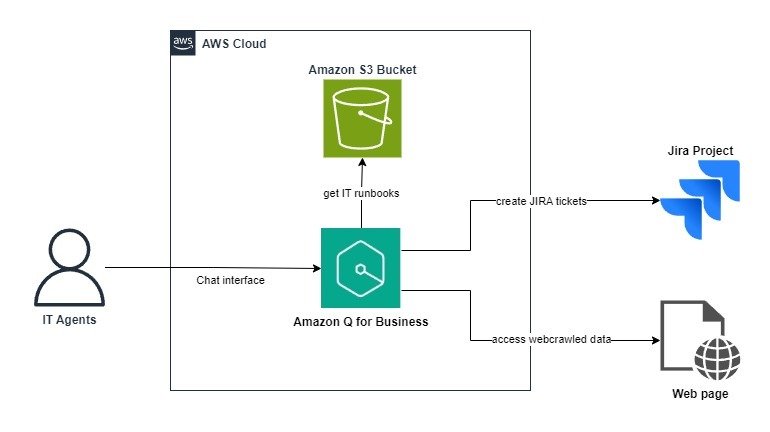
Amazon Q Business пропонує масштабовану допомогу зі штучним інтелектом для команд ІТ-підтримки, підвищуючи продуктивність завдяки розумінню природної мови та персоналізованим відповідям. Інтегруючись з Jira та налаштовуючи бази знань, Amazon Q впорядковує процеси усунення несправностей, скорочуючи час і зусилля на вирішення ІТ-викликів.