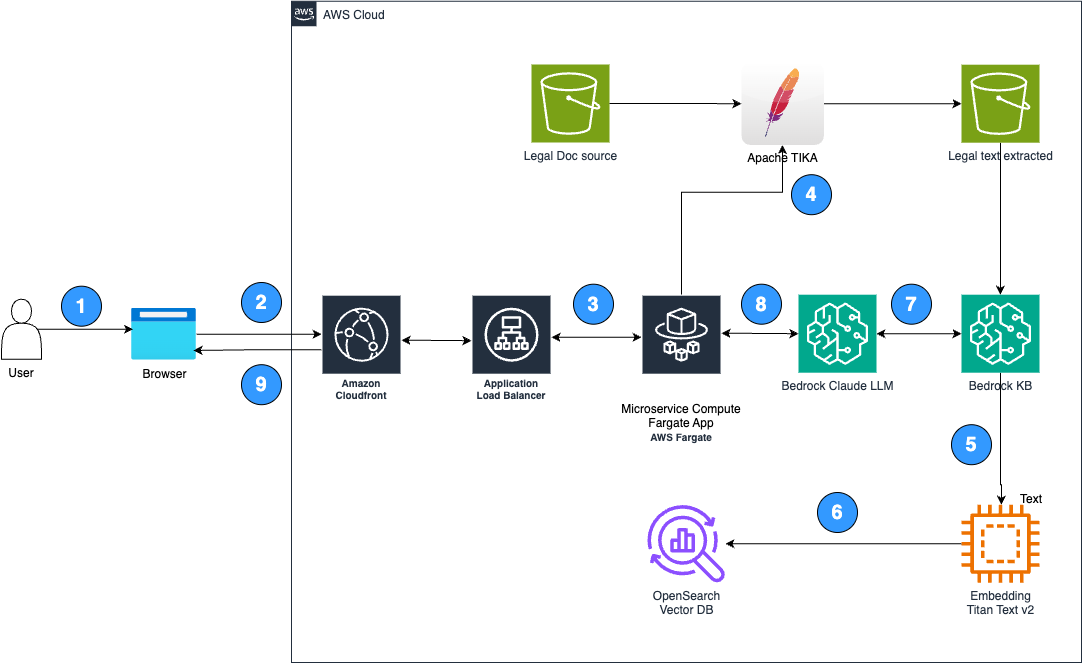
Lexbe використала Amazon Bedrock, щоб революціонізувати процес перегляду юридичних документів за допомогою штучного інтелекту та машинного навчання, підвищивши ефективність і точність. Завдяки інтеграції Amazon Bedrock у Lexbe Pilot юридичні команди можуть швидко отримувати інформацію з величезних масивів даних, запобігаючи дороговартісним помилкам.
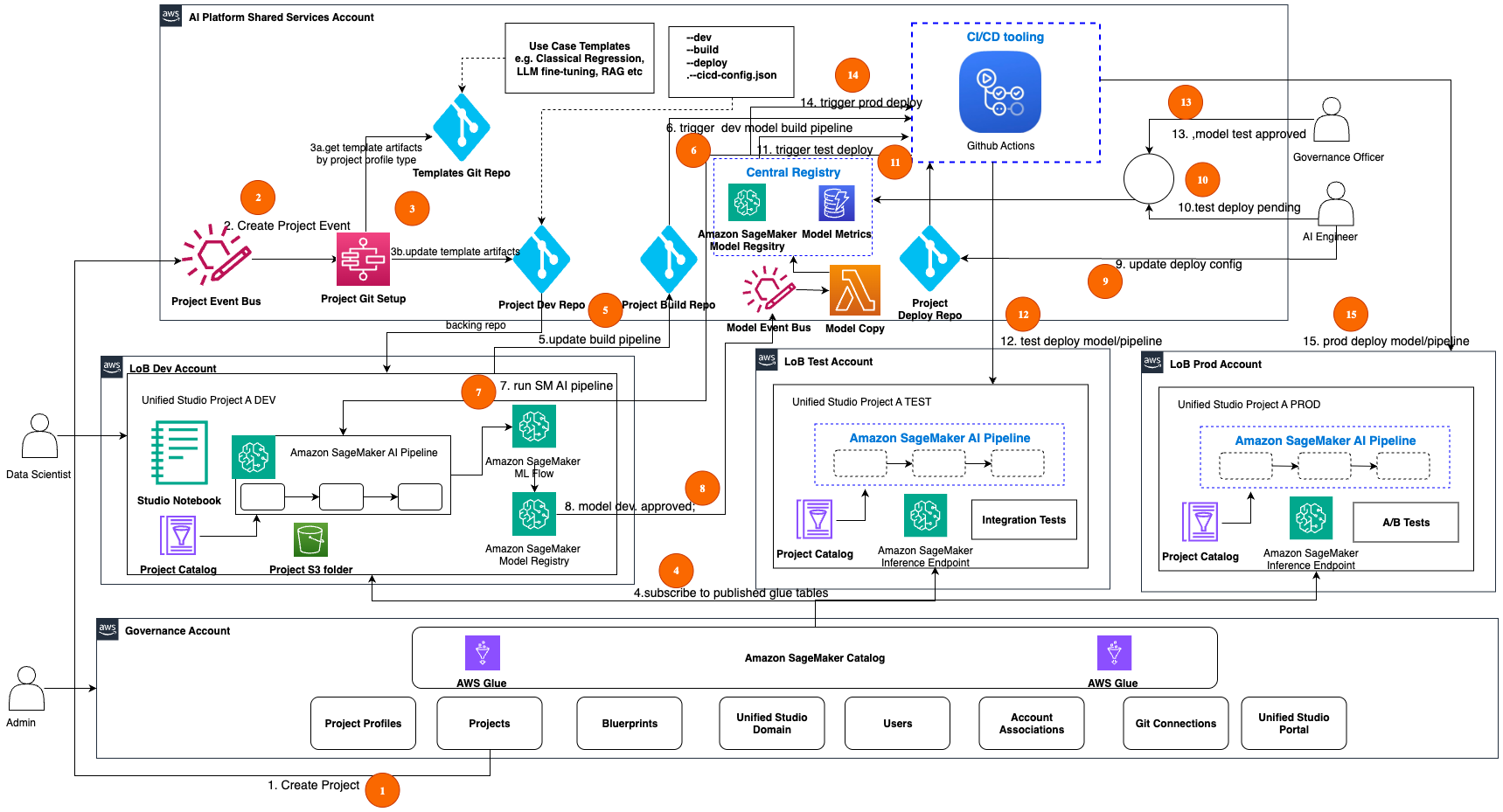
Amazon SageMaker Unified Studio оптимізує робочі процеси з даними, аналітикою та штучним інтелектом. Серед викликів — масштабування, автоматизація та контроль управління. Архітектурні стратегії та масштабована структура допомагають керувати багатокористувацькими середовищами та автоматизувати AIOps у SageMaker Unified Studio.

Amazon Devices & Services використовує технологію цифрових двійників NVIDIA для вдосконалення виробництва за допомогою програмного забезпечення штучного інтелекту, навчання роботів для аудиту та інтеграції продуктів без фізичного прототипування. Цей інноваційний підхід забезпечує швидші та ефективніші перевірки і дозволяє гнучко організувати виробничі процеси для різноманітних продуктів за доп...
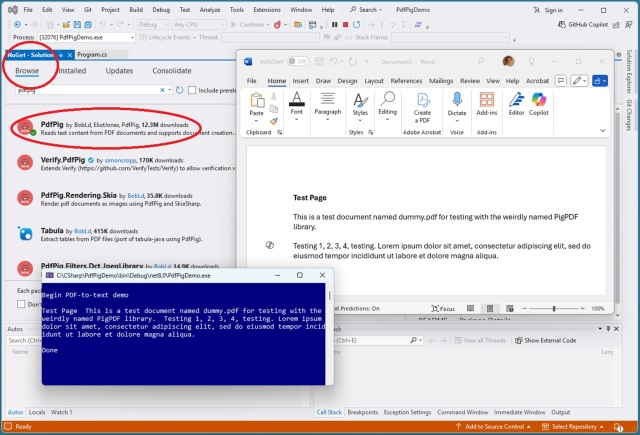
Витяг тексту з PDF-файлів може бути складним завданням через їх візуальний характер. Провідними бібліотеками C# для цього завдання є iText і PdfPig, а PyMuPDF для Python є найкращим вибором.
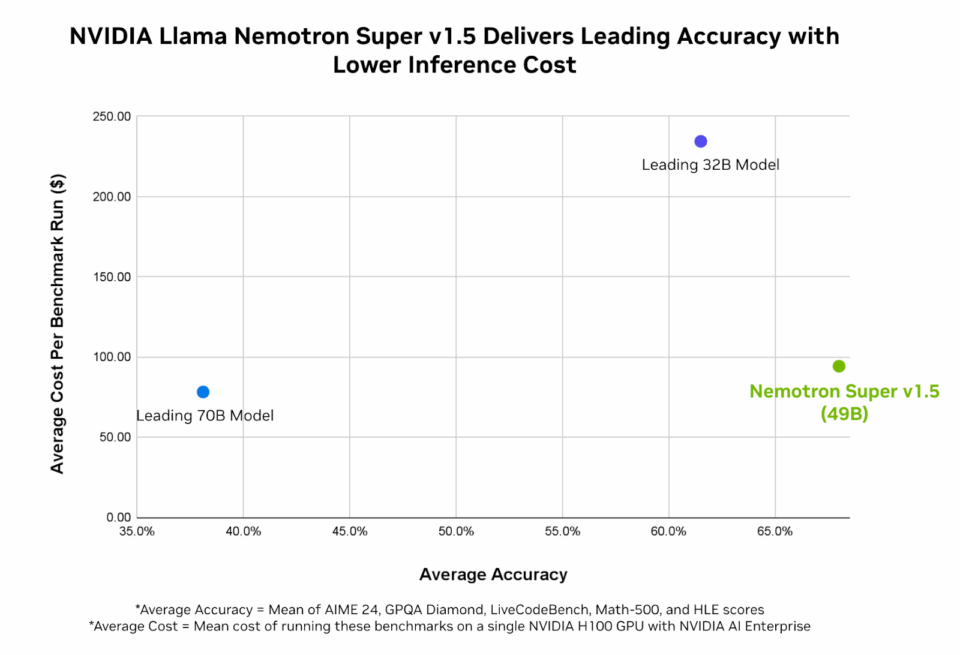
Штучний інтелект, такий як NVIDIA Nemotron і Cosmos, до 2028 року принесе 450 мільярдів доларів додаткового прибутку. Ці моделі забезпечують найвищу точність і ефективність для корпоративного штучного інтелекту, підвищуючи продуктивність і покращуючи процес прийняття рішень.

Відео, створені за допомогою штучного інтелекту, завойовують YouTube: майже кожен десятий з найпопулярніших каналів містить виключно контент, створений за допомогою штучного інтелекту. Від сюрреалістичних сценаріїв до мильних опер про котів — такі канали, як Super Cat League і Cuentos Facinantes, приваблюють мільйони підписників.

Дослідження LSE виявляє гендерну упередженість у рішеннях щодо догляду, прийнятих на основі штучного інтелекту на основі резюме випадків, що применшують проблеми зі здоров'ям жінок. Інструмент штучного інтелекту Google «Gemma» демонструє мовну упередженість, частіше використовуючи такі терміни, як «інвалід», щодо чоловіків, ніж щодо жінок.
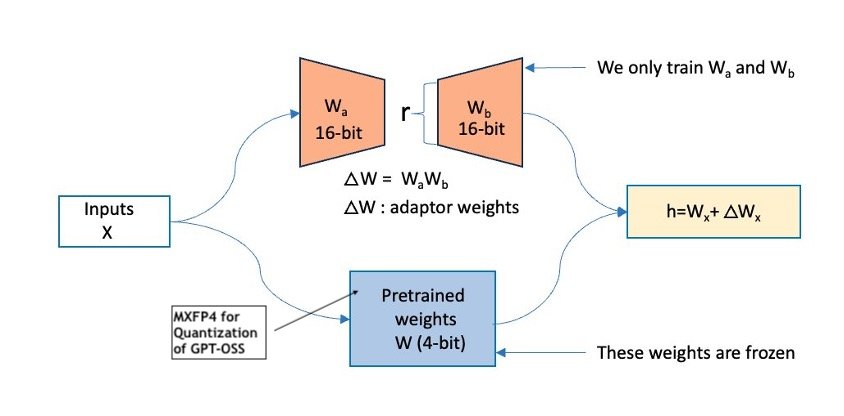
Моделі GPT-OSS від OpenAI, gpt-oss-20b та gpt-oss-120b, доступні на AWS з архітектурою MoE для високої продуктивності міркування та зниження витрат на обчислення. Точне налаштування перетворює моделі на експертів у конкретних галузях, підвищуючи точність і надійність для цільових завдань.

Комісія з продуктивності Австралії розглядає можливість виключення текстового майнінгу з Закону про авторське право. Від друкарських машинок до Commodore 64 — технологія змінює журналістику.

NVIDIA представляє графічні процесори RTX PRO 4000 SFF і RTX PRO 2000 з прискоренням штучного інтелекту для професійних робочих процесів, що забезпечують вищу продуктивність у компактних розмірах. Такі компанії, як Mile High Flood District і Studio Tim Fu, користуються швидкістю та ефективністю графічних процесорів NVIDIA RTX PRO для виконання таких завдань, як моделювання повеней і проектуван...

Доктор Карл Крузельніцький планує запустити чат-бот для запитань про кліматичну кризу, використовуючи свій 40-річний досвід у сфері наукової комунікації. Незважаючи на свій культовий статус, 77-річний вчений прагне розширити свій вплив за допомогою цього інноваційного інструменту.

Співробітники Інституту Алана Тьюринга попереджають про можливий крах через загрозу скорочення державного фінансування. Скарга інформатора висвітлює проблеми управління та внутрішньої культури.
Уникайте надмірного засмаги, щоб запобігти раку шкіри (Попередження про опіки: покоління Z і жахливе зростання популярності надмірного засмаги). Відкрийте для себе скарби ар-нуво в Нансі, Франція, де представлені роботи Еміля Галле та Луї Мажореля (Редакційна стаття, 8 серпня).

Нова модель GPT-5 від OpenAI пропонує розширені можливості, але за високої вартості енергії. Запит рецепта може споживати в 20 разів більше електроенергії, ніж попередня версія.

Нове дослідження показує, що найновіша модель iPhone від Apple має найдовший час автономної роботи серед своїх конкурентів. iPhone 12 Pro Max перевершив пристрої Samsung, Google та OnePlus у тестах на автономність.