
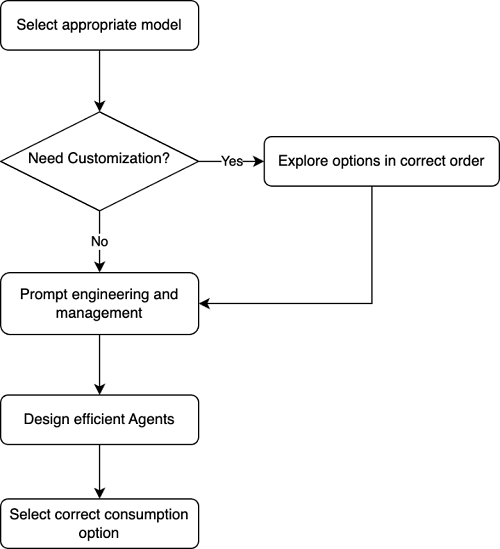
Дослідники Массачусетського технологічного інституту та IBM вдосконалюють LLM для планування подорожей, поєднуючи їх з алгоритмами Нова методика може визначати обмеження, пропонувати альтернативи та допомагати користувачам ефективно розробляти реалістичні та логічні плани подорожей.
Генеративний ШІ все частіше використовується для підвищення ефективності та інновацій у різних галузях, але витрати на нього можуть зростати. Amazon Bedrock пропонує високопродуктивні моделі та методи оптимізації витрат для створення додатків генеративного ШІ.

Лауреат премії MIT «Передбачаючи майбутнє комп'ютерних технологій» Енналіз Мейєр представляє B-ботів, синтетичних бактеріальних імітаторів для здоров'я кишечника. Застережлива розповідь Мейєр про модель охорони здоров'я на основі підписки підкреслює потенційну шкоду комерційної системи.
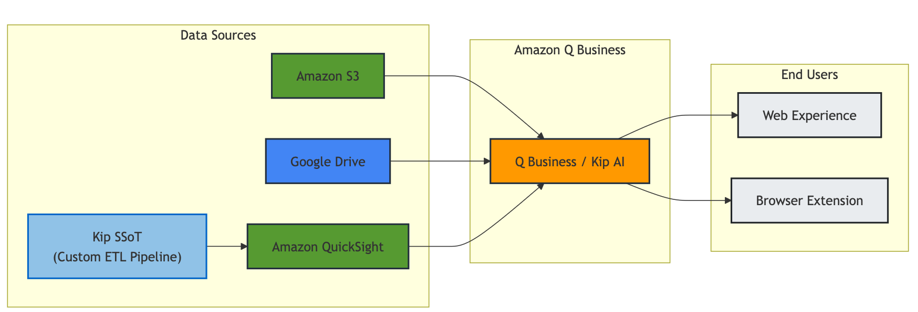
Kepler Group використала Amazon Q Business для демократизації доступу до штучного інтелекту, заощадивши 2,7 години на тиждень на кожного працівника. Рішення було прийнято завдяки безшовній інтеграції з AWS та суворому дотриманню вимог безпеки.

Coactive, заснована Коді Коулманом '13 та Вільямом Гавіріа Рохасом '13, використовує штучний інтелект для аналізу неструктурованих візуальних даних для прийняття швидших та якісніших бізнес-рішень. Платформа допомагає компаніям обробляти зображення, аудіо та відео у великих масштабах, даючи можливість людям працювати ефективніше та вирішувати нові проблеми.

Університет штату Огайо навчатиме студентів відповідальному застосуванню штучного інтелекту, щоб стати лідером у майбутньому. Президент Волтер «Тед» Картер-молодший наголошує на підготовці студентів до інтеграції ШІ.

Викладач музики у великому британському університеті висловлює занепокоєння впливом ШІ на академічну сферу, підозрюючи студентів у використанні ШІ для написання есе та музики, через що викладачі відчувають себе безсилими і не знають, як вирішити цю проблему. Стрімке поширення ШІ в освіті ставить питання про академічну доброчесність і належне використання інструментів ШІ в університетах, висвіт...

Дослідники Apple виявили обмеження в передових моделях штучного інтелекту, що ставить під сумнів прагнення індустрії до створення більш потужних систем. Згідно з документом Apple, великі моделі міркувань стикаються з падінням точності, коли мають справу зі складними проблемами.

WPP очолює кампанії, створені штучним інтелектом, за допомогою Meta, що дозволяє фірмам створювати рекламу. ШІ швидко трансформує світову рекламу, і WPP щорічно інвестує 300 мільйонів фунтів стерлінгів у дані та технології.

Дженсен Хуанг (NVIDIA) і прем'єр-міністр Великобританії Стармер відкрили Лондонський технологічний тиждень, сигналізуючи про інтеграцію ШІ в національну політику та економіку. Великобританія планує інвестувати 1 мільярд фунтів стерлінгів у дослідницькі обчислення ШІ до 2030 року, демонструючи прихильність до інновацій та розвитку навичок ШІ.

Getty Images звинуватила Stability AI у навчанні ШІ на фотографіях, захищених авторським правом, що стало загрозою для індустрії генеративного ШІ. Високий суд Лондона розглядає позов Getty про порушення авторських прав і торгових марок проти Stability AI за використання її фотоархівів.

Анонси ШІ від Apple на WWDC були зосереджені на поступових оновленнях, таких як живий переклад і додаток Workout Buddy з голосом, згенерованим штучним інтелектом. Незважаючи на тиск конкуренції, нові функції Apple не дотягують до існуючих можливостей Android.

Генеральний директор WPP Марк Рід піде у відставку після 30 років, оскільки штучний інтелект загрожує рекламній індустрії. Акції досягли 5-річного мінімуму.

Пакет інструментів штучного інтелекту під назвою Humphrey навчить усіх державних службовців Англії та Уельсу підвищувати продуктивність. Канцлер Пет Макфадден очолює ініціативу з реформування державної служби за допомогою практичного навчання ШІ для 400 000+ співробітників.
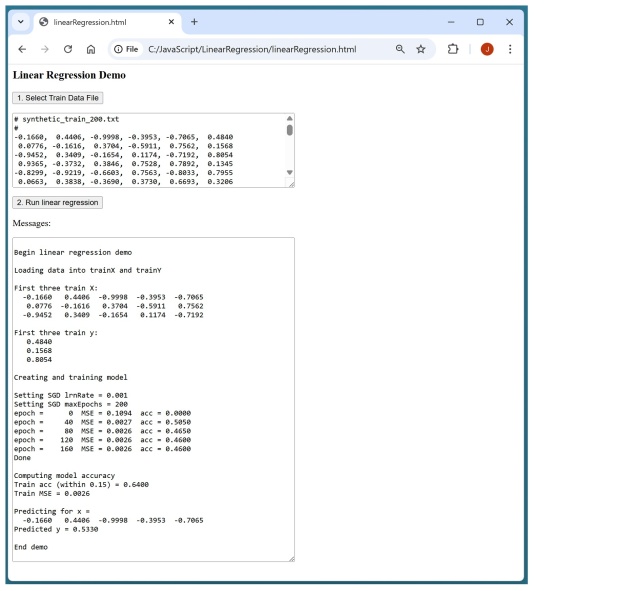
Система лінійного регресійного прогнозування демонструється з використанням JavaScript на стороні клієнта для простоти. Навчена модель досягла точності 64.00% завдяки нелінійній структурі даних. Нещодавно помер відомий художник Роберт МакГінніс, відомий своїми культовими обкладинками книг та кіноплакатами.