
Девід Салле використовує штучний інтелект на своїх картинах для отримання диких, розлогих результатів. Чи зможе штучний інтелект сказати щось нове про творчість художника?
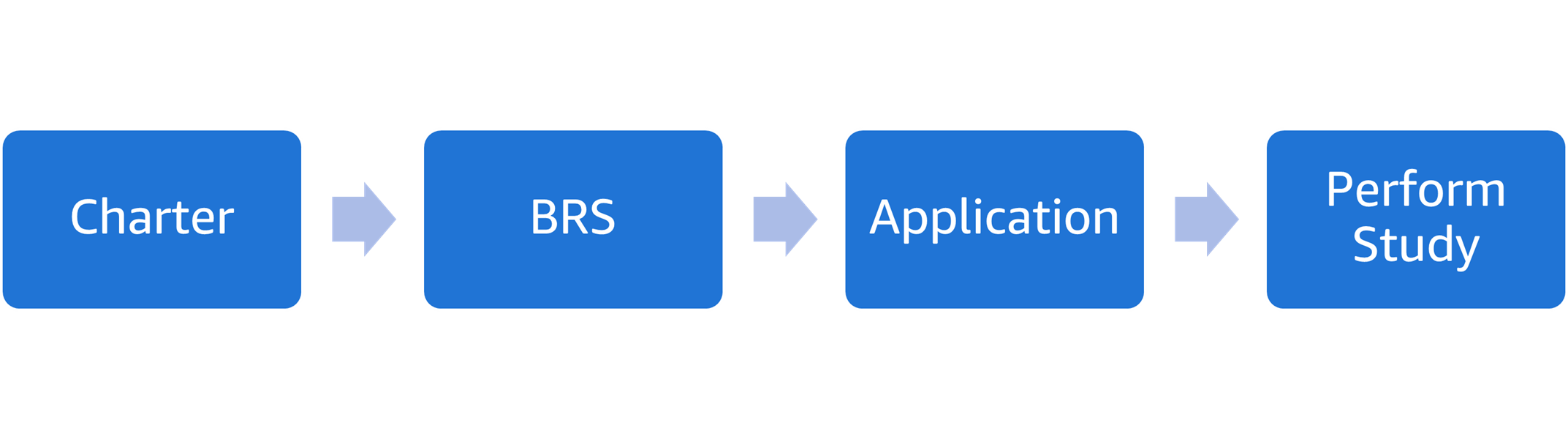
Компанія Clario, лідер у галузі рішень для кінцевих даних для клінічних досліджень, модернізувала генерацію документів за допомогою сервісів штучного інтелекту AWS, щоб оптимізувати робочі процеси. Рішення автоматизує генерацію BRS, скорочуючи трудомісткі ручні завдання та мінімізуючи помилки в документації клінічних досліджень.

Nvidia інвестує $500 млрд в інфраструктуру штучного інтелекту в США на тлі загроз Трампа щодо імпорту. Генеральний директор пообідав в Мар-а-Лаго.

Палата представників штату Техас, контрольована республіканцями, ухвалить закон, що встановлює обмеження для центрів обробки даних, що може затримати плани Трампа щодо інфраструктури штучного інтелекту. Спільне підприємство Stargate побудує 20 дата-центрів для обчислювальних потужностей ШІ, щоб підвищити конкурентоспроможність США проти Китаю.
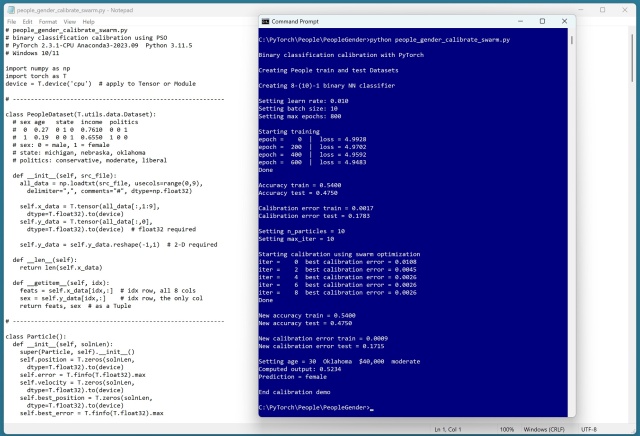
Похибка калібрування в моделях прогнозування має вирішальне значення. Демонстрація з використанням PyTorch та PSO показує, як її ефективно покращити.

AWS пропонує оптимізовані рішення для розгортання великих мовних моделей, таких як Mixtral 8x7B, використовуючи чипи AWS Inferentia та AWS Trainium для високопродуктивного виведення. Дізнайтеся, як розгорнути модель Mixtral на екземплярах AWS Inferentia2 для економічно ефективної генерації тексту.

Понад 100 мільйонів людей використовують персоніфікованих чат-ботів для різних цілей - від віртуальних «дружин» до підтримки психічного здоров'я. Чат-боти зі штучним інтелектом трансформують людський зв'язок, імітуючи людську взаємодію завдяки адаптивному навчанню та персоналізованим відповідям.
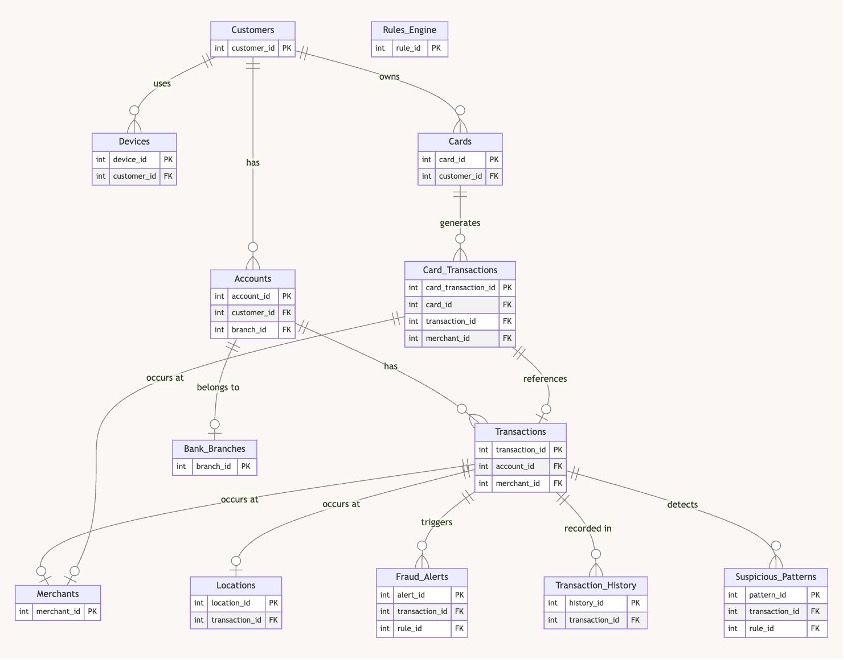
Генеративний ШІ, як-от Amazon Web Services (AWS), надає можливості перетворення тексту в SQL для ефективнішого дослідження даних. Реалізація в масштабі підприємства з розширеними інструментами обробки помилок підвищує ефективність запитів до бази даних.

Створення веб-додатків з інтеграцією генеративного ШІ є складним завданням, але розбиття його на шари, такі як стек ШІ, може допомогти зорієнтуватися в цьому ландшафті. Такі компанії, як OpenAI, використовують різні рівні, співпрацюючи з Microsoft для створення інфраструктури та веб-скребків для даних, щоб забезпечити роботу таких додатків, як ChatGPT.
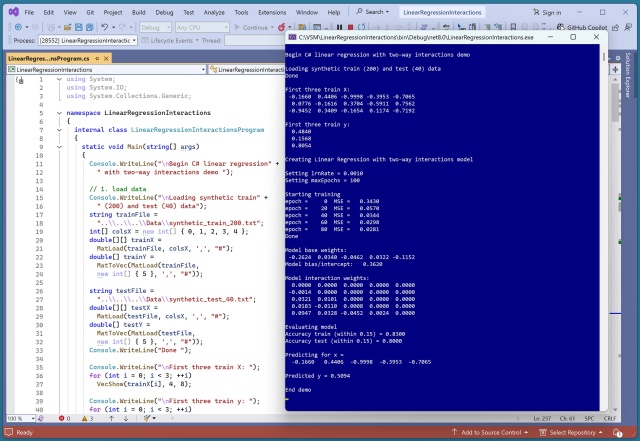
Застосування лінійної регресії з двосторонніми взаємодіями значно підвищило точність прогнозування. Модель досягла 83% точності на навчальних даних і 80% на тестових даних, що свідчить про її ефективність.

Ультраправа ідеологія перетворюється на супрематичний виживання. Рух за корпоративні міста-держави стикається з проблемами, незважаючи на підтримку потужних гравців.

OpenAI подає в суд на Ілона Маска за переслідування і домагається судового позову, щоб зупинити подальші атаки на компанію. Суперечка між співзасновниками загострюється, коли OpenAI переходить від некомерційної до комерційної структури.

Моделі штучного інтелекту, такі як CNN, імітують людську візуальну обробку, але мають проблеми з причинно-наслідковими зв'язками. Незважаючи на те, що вони перевершують людину в деяких завданнях, їм не вдається узагальнювати класифікацію зображень, виділяючи обмеження.

Короткий зміст: У статті обговорюються людські аспекти машинного навчання, підкреслюється важливість комунікації та розуміння кінцевих користувачів. Вона також висвітлює роль інженерів AI/ML, команд MLOps і зацікавлених сторін у створенні цінних додатків.
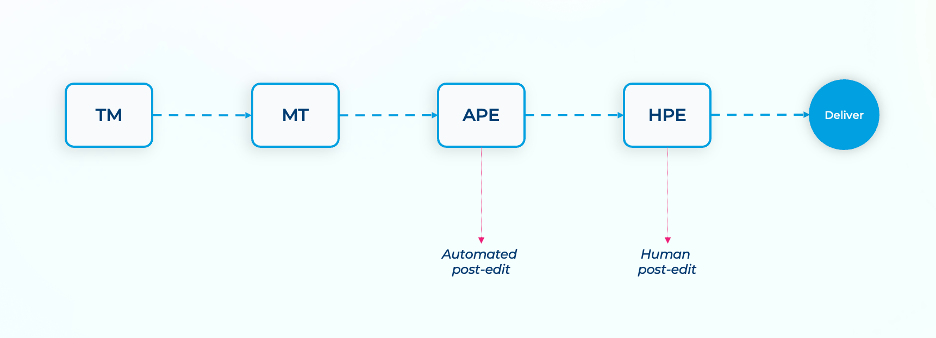
TransPerfect співпрацює з AWS, щоб оптимізувати переклад багатомовного контенту за допомогою моделей Amazon Bedrock AI, підвищуючи ефективність і масштабованість. Співпраця спрямована на оптимізацію робочих процесів, зниження витрат і прискорення доставки контенту для компаній, що розвиваються в глобальному масштабі.