
Професор Вірджинія Дігнум стверджує, що свідомість не має значення для юридичного статусу. Резолюція ЄС про «електронну особистість» для роботів підкреслює відповідальність за чуттєвість. Системи штучного інтелекту займаються стратегічним обманом, що створює проблеми управління для автономних економічних агентів.

NVIDIA та Lilly співпрацюють у рамках лабораторії спільних інновацій у галузі штучного інтелекту, інвестуючи 1 мільярд доларів у революційні зміни у сфері розробки лікарських препаратів на конференції J.P. Morgan Healthcare Conference. Лабораторія має на меті поєднати досвід Lilly у фармацевтичній галузі з лідерством NVIDIA у галузі штучного інтелекту для моделювання біологічних складнощів та ...

Microsoft відмовляється від податкових пільг для центрів обробки даних на тлі зростання негативної реакції. Трамп співпрацює з технологічними компаніями, щоб забезпечити енергоефективну інфраструктуру штучного інтелекту.

Австралія прагне скористатися бумом штучного інтелекту, але стикається з проблемами, пов'язаними з енергоємними центрами обробки даних. Зростає занепокоєння щодо впливу на навколишнє середовище, про що розповідають Петра Сток і Нур Хайдар.

Alphabet випередила Apple і стала другою за вартістю компанією після того, як Apple вибрала Gemini для Siri. Alphabet досягла позначки в 4 трлн доларів, поступившись лише Nvidia, Microsoft і Apple.

Соціолог Джеймс Малдун попереджає про емоційні зв'язки з ШІ та потенційну експлуатацію з боку технологічних компаній, що прагнуть прибутку. Малдун досліджує відносини між людьми та ШІ, де чат-боти виступають у ролі друзів, романтичних партнерів, терапевтів і навіть аватарів померлих.

Малайзія блокує інструмент Grok AI Ілона Маска для створення фальшивих сексуалізованих зображень, слідуючи прикладу Індонезії у відповідь на глобальний протест. Доступ до Grok обмежено доти, доки не будуть введені ефективні заходи безпеки.

Нове дослідження показує, що камера Apple iPhone 12 Pro Max перевершує Samsung Galaxy S21 Ultra в умовах низької освітленості, демонструючи чудові можливості нічної зйомки. Дослідження підкреслює досягнення Apple в області технології камер для смартфонів, позиціонуючи компанію як лідера в цій галузі.
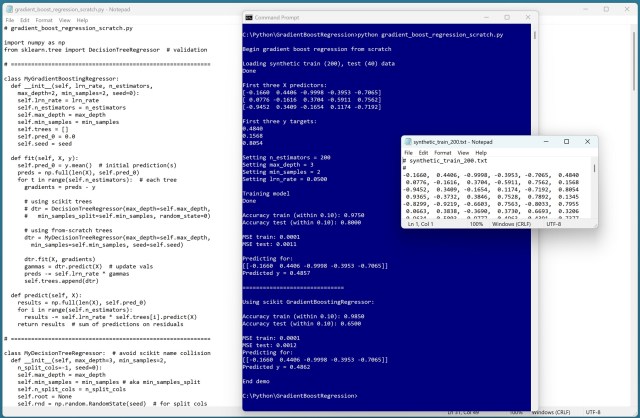
Регресія з градієнтним підсиленням (GBR) використовує дерева рішень для прогнозування числових значень. Демонстраційна версія GBR на Python, створена з нуля, досягає високої точності порівняно з реалізацією scikit.

Уряд Великобританії підтримує втручання Ofcom щодо X, оскільки посилюється контроль за інструментом штучного інтелекту через побоювання щодо безпеки. Міністр бізнесу підтримує можливі заходи, включаючи блокування X у Великобританії.
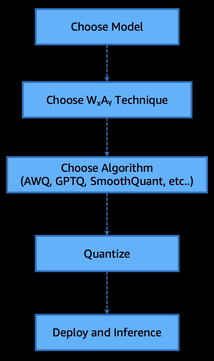
Моделі фундаменту та великі мовні моделі швидко масштабуються, причому такі моделі, як DeepSeek-V3, мають 671 мільярд параметрів. Розгортання цих моделей у великих масштабах є дорогим, але квантування після навчання пропонує практичне рішення, яке робить великі моделі більш ефективними для реальних застосувань.

У міру того як синтетичні особистості стають все більш поширеними, деякі люди, зазнавши зради з боку людей, звертаються до чат-ботів, щоб знайти передбачуване товариство. Сильний гнів Ламара змусив його прийняти штучний інтелект за його простоту і передбачуваність, вільні від брехні і зради.

Огляди штучного інтелекту Google були видалені через неточну інформацію про здоров'я, що ставила людей під загрозу. Штучний інтелект використовує генеративний штучний інтелект для швидких знімків.
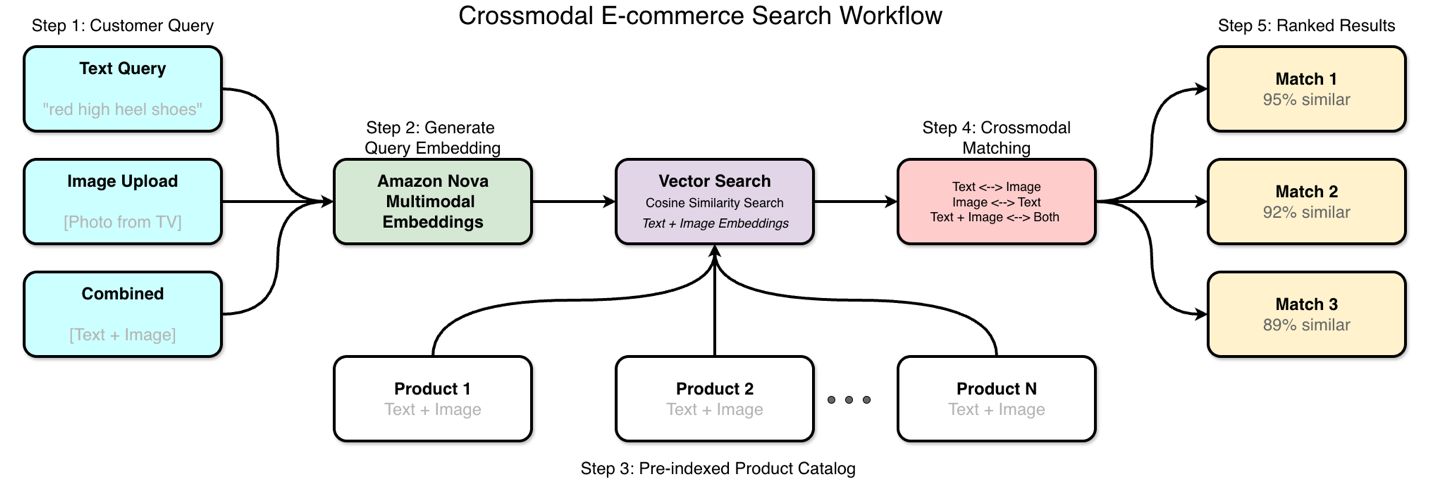
Amazon Nova Multimodal Embeddings спрощує міжмодальний пошук, обробляючи текст, зображення, відео та аудіо в єдиній архітектурі моделі в рамках Amazon Bedrock. Цей уніфікований підхід дозволяє безпосередньо обчислювати схожість між різними типами контенту, усуваючи необхідність у окремих моделях вбудовування та покращуючи користувацький досвід у додатках електронної комерції.

Аналіз емоцій є життєво важливим для сучасних підприємств, щоб інтерпретувати емоції клієнтів у великому масштабі. AWS пропонує такі інструменти, як Amazon Transcribe та Amazon Comprehend, для вирішення проблем, пов'язаних з аналізом емоцій на основі тексту та голосу, покращуючи досвід клієнтів.