Глобальна магістральна мережа AWS забезпечує надійне надання послуг у 34 регіонах, 600 точках доступу CloudFront тощо. AWS використовує GML фреймворк GraphStorm для прогнозування та пом'якшення ризиків перевантаження мережі, вирішуючи складні завдання управління мережею.

Несподіваними науковими новинами 2024 року стали віспа в ДРК, ШІ на Нобелівських преміях та астронавти, що застрягли на мілині. Що принесе 2025 рік? Ієн Семпл та Ганна Девлін прогнозують майбутні великі історії.
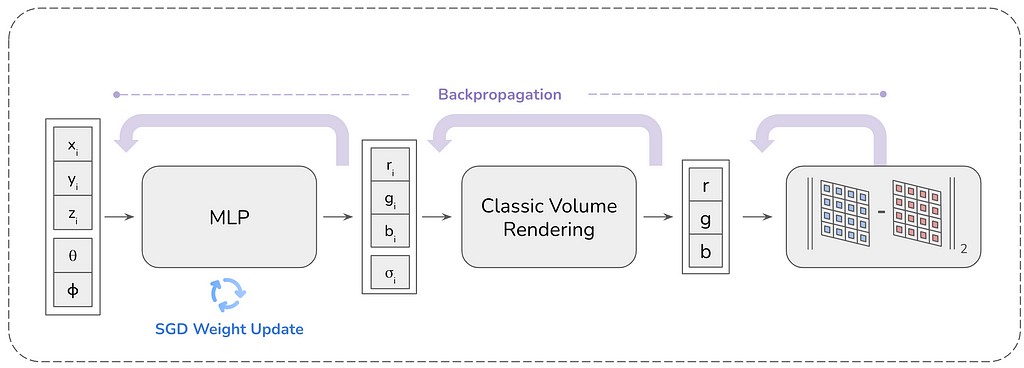
NeRF - це передовий метод рендерингу 2D-зображень з 3D-сцен, що використовує надбудований MLP для стиснення інформації про сцену. Це значно зменшує вимоги до пам'яті і дозволяє генерувати зображення з будь-якого напрямку перегляду.
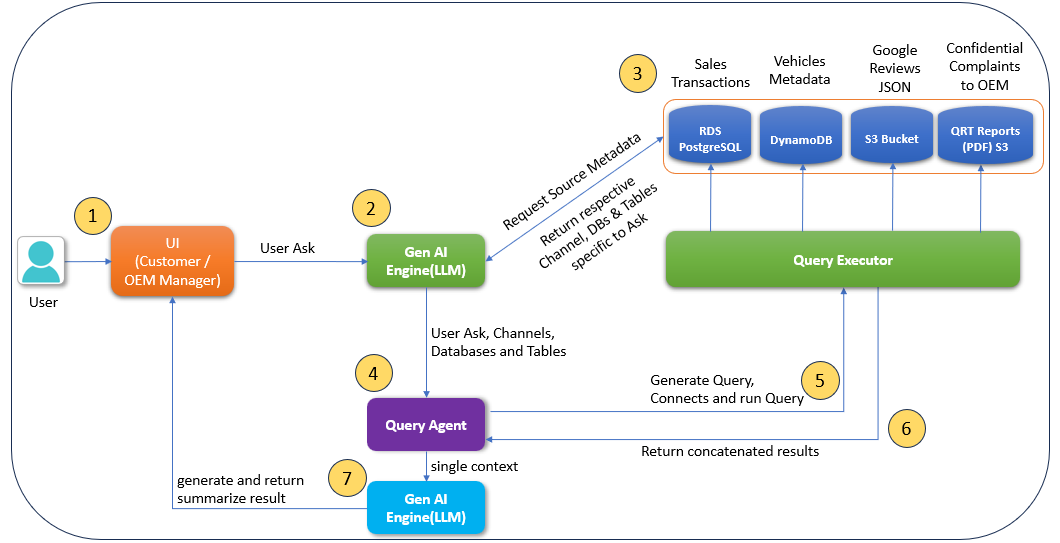
AutoWise Companion від HCLTech використовує штучний інтелект, щоб спростити рішення про купівлю автомобіля для клієнтів і покращити аналіз даних для виробників. Рішення витягує інформацію з різних джерел даних, надаючи персоналізовані рекомендації та підвищуючи рівень задоволеності клієнтів.

Кейр Стармер прогнозує трансформацію економіки Великої Британії завдяки штучному інтелекту та заперечує плани щодо заміни голови Казначейства. Тиск на економіку зростає, оскільки зростання зупиняється, фунт знецінюється, а вартість боргу зростає.
Агенти Amazon Bedrock Agents уможливлюють швидку розробку генеративних програм штучного інтелекту для корпоративних систем. Гібридні та периферійні сервіси, такі як AWS Outposts, покращують результати моделювання за допомогою локальних даних, вирішуючи проблеми резидентності даних та відповідності вимогам.

Мультиагентна співпраця з використанням великих мовних моделей (LLM) покращує вирішення проблем, поєднуючи міркування спеціалізованих агентів. Фреймворк MAC від AWS організовує роботу декількох агентів ШІ на базі Amazon Bedrock Agents для ефективного та результативного вирішення проблем завдяки розподіленому вирішенню проблем та спеціалізації.

Британська компанія очолює кампанію за малі модульні реактори (ММР) як більш швидку і економічно ефективну альтернативу великій АЕС Хінклі Пойнт С. ММР пропонують більш швидке і дешеве будівництво у порівнянні з відкладеним і дорогим проектом Хінклі.
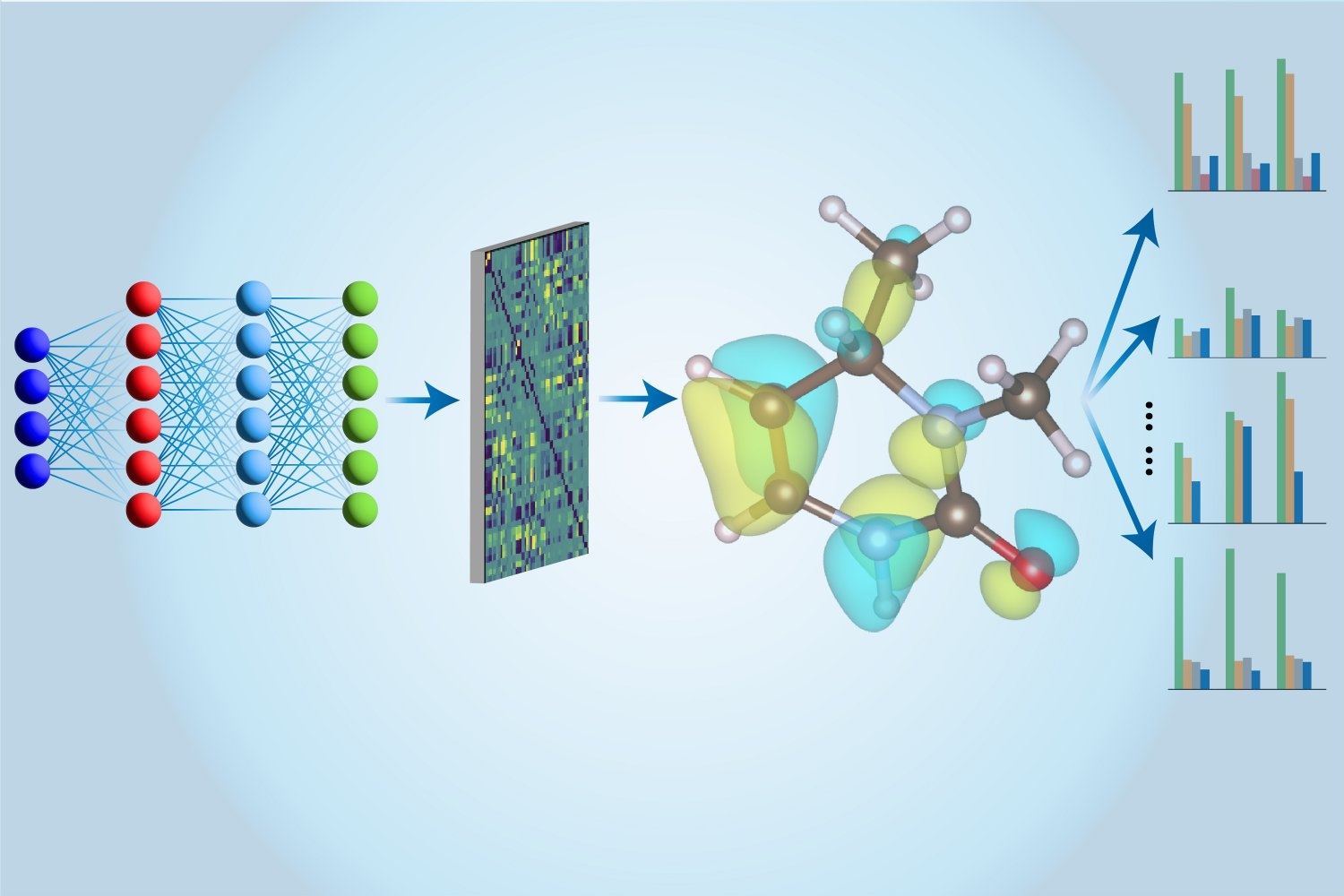
Дизайн матеріалів пройшов шлях від алхімії до машинного навчання. Дослідження під керівництвом Джу Лі представляє новий метод, що використовує теорію зв'язаних кластерів для підвищення точності та швидкості проектування матеріалів.

Кейт Моссе та Річард Осман критикують план лейбористів, який дозволяє компаніям зі створення штучного інтелекту видобувати художні твори, попереджаючи, що це може придушити творчість і прирівнятись до крадіжки. Кейр Стармер схвалює план дій з 50 пунктів, спрямований на перетворення Великої Британії на наддержаву ШІ, включаючи зміни у використанні технологічними компаніями захищених авторським ...

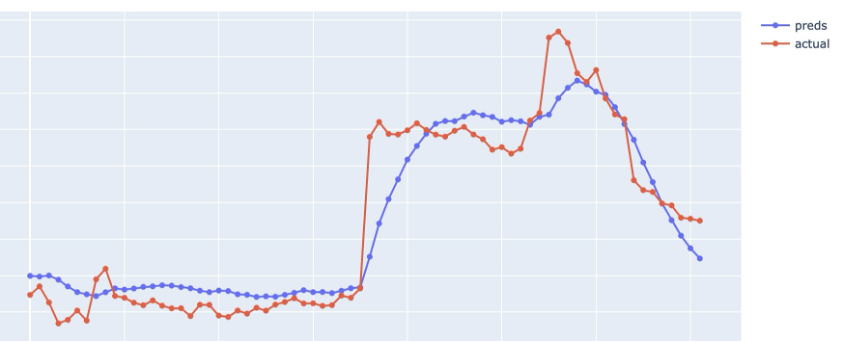
Лінійна регресія з двосторонніми взаємодіями може значно підвищити точність прогнозування. Модель була успішно реалізована за допомогою C# і досягла високого рівня точності.
Дослідники Массачусетського технологічного інституту з Інституту досліджень мозку Макговерна виявили життєво важливу роль точного визначення часу в слухових нейронах для розпізнавання голосів і визначення місцезнаходження звуків. Використовуючи машинне навчання, моделі команди надають інформацію для вивчення порушень слуху та розробки інтервенцій.

Кейр Стармер планує збільшити обчислювальну потужність ШІ в 20 разів до 2030 року. Але чи не суперечитимуть енергоємні дата-центри цілям Великобританії щодо чистої енергії?

Зона зростання ШІ лейбористів біля водосховища Абінгдон викликає занепокоєння щодо тиску водопостачання. Кейр Стармер планує збільшити потужність ШІ з меншою кількістю обмежень на будівництво дата-центрів.

Віджай Гадепаллі з Лабораторії Лінкольна Массачусетського технологічного інституту обговорює розвиток генеративного штучного інтелекту в обчисленнях, його вплив на навколишнє середовище та стратегії скорочення викидів для більш зеленого майбутнього. LLSC зосереджується на підвищенні ефективності обчислень, зменшенні енергоспоживання за рахунок обмеження потужності та моніторингу робочих навант...