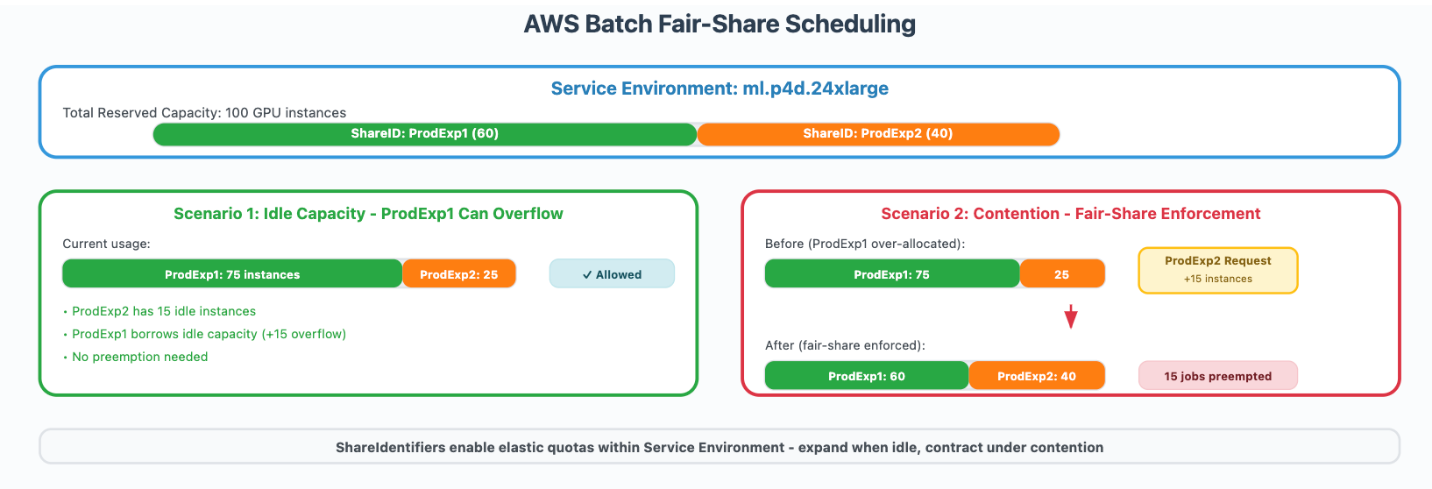
Amazon Search оптимізував використання графічних процесорів (GPU), використовуючи AWS Batch для завдань SageMaker Training, збільшивши пікове використання графічних процесорів з 40% до понад 80%. Керуване рішення дозволило застосувати розширені критерії пріоритетності, забезпечити безперебійну інтеграцію та підвищити ефективність розробки моделей в Amazon Search.

Дослідники з Массачусетського технологічного інституту (MIT) розробили нову систему на базі штучного інтелекту для пошуково-рятувальних роботів, яка дозволяє швидко створювати точні 3D-карти складних об'єктів. Система може обробляти довільну кількість зображень у режимі реального часу, що спрощує її масштабування для застосування в реальних умовах під час катастроф та в промислових умовах.

Світові фондові ринки падають у зв'язку з охолодженням оцінок компаній, що займаються штучним інтелектом. Керівники банків попереджають про можливу корекцію ринку після рекордних максимумів

Компанії, що займаються штучним інтелектом, досягли фінансових рекордів з оцінкою в 5 трлн доларів і квартальним доходом в 100 млрд доларів, уклавши угоди на суму майже 600 млрд доларів. Google, Microsoft і Tesla входять до числа 200 компаній, що розташовані в величезному промисловому центрі Тахо-Рено, який займає десятки тисяч акрів в пустелі Невади.
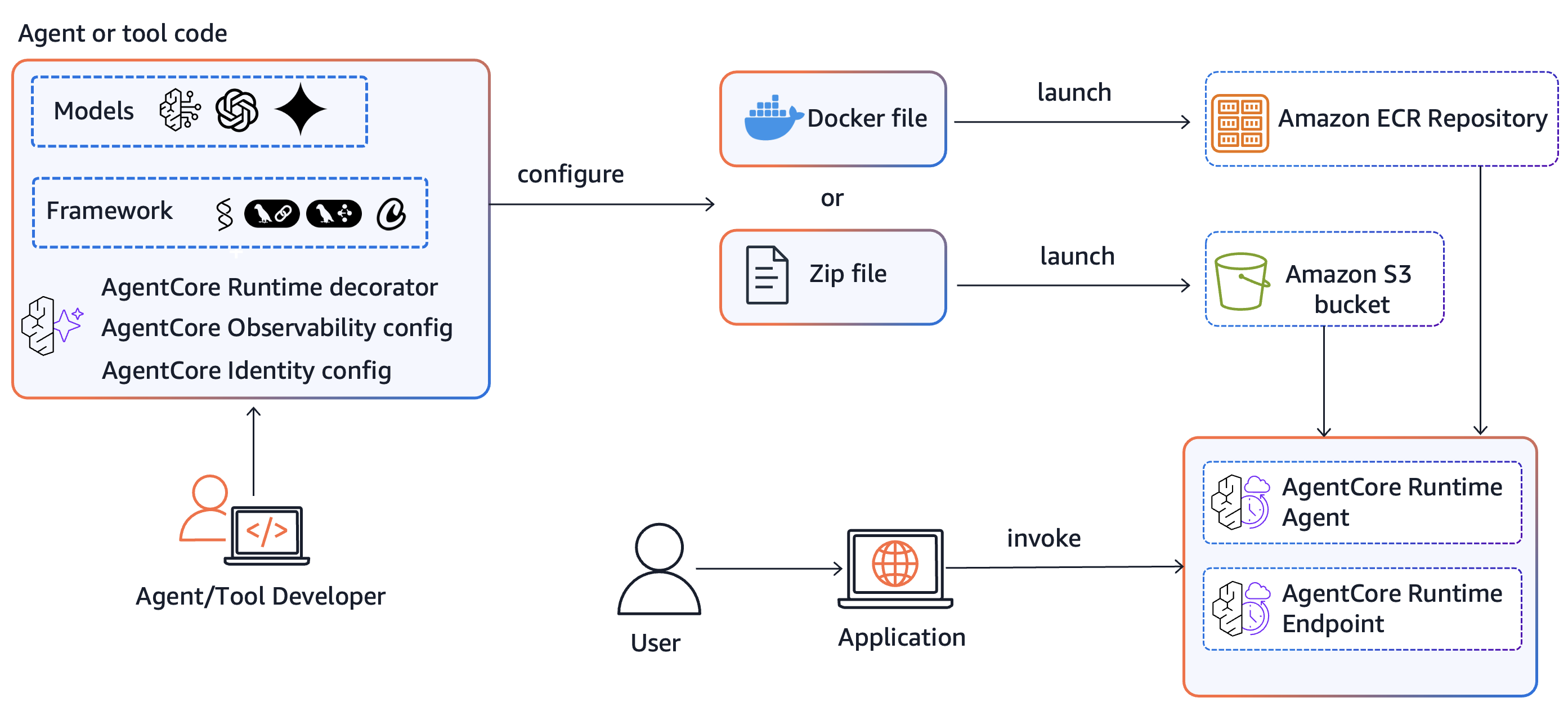
Amazon Bedrock AgentCore пропонує два методи розгортання: на основі контейнерів та пряме розгортання коду (для Python), що забезпечує гнучкість для розробників. Пряме розгортання коду спрощує процес шляхом упаковки коду та залежностей у zip-архів, що є вигідним для тих, хто не бажає мати справу з Docker.

Лондонська компанія Stability AI, співзасновником якої є Джеймс Кемерон, виграла історичну справу проти Getty Images щодо порушення авторських прав. Це рішення є ударом для власників авторських прав, які без дозволу використовують моделі штучного інтелекту з даними, захищеними авторським правом.

Google планує до 2027 року запустити в космос центри обробки даних на базі штучного інтелекту, використовуючи супутники на сонячних батареях, щоб задовольнити зростаючий попит на обробку даних штучним інтелектом. Інженери планують вивести на орбіту на висоті 400 миль над Землею близько 80 супутників, скориставшись зниженням вартості запуску ракет.

OpenAI укладає угоду з Amazon на суму 38 млрд доларів про використання дата-центрів AWS і чіпів Nvidia в рамках програми інвестицій в інфраструктуру штучного інтелекту на суму 1,4 трлн доларів.

П'ята виставка Photo Oxford демонструє фотографії, зроблені власноруч і некомерційні, включаючи мистецтво Майкла Крістофера Брауна, створене за допомогою штучного інтелекту. Виставка Брауна «90 миль» за допомогою сюрреалістичних зображень, що не дають спокою, відображає небезпечну подорож кубинців, які втікають до Флориди на саморобних човнах.

Дослідження Орегонського державного університету оцінює кількість видів тварин, що знаходяться під загрозою вимирання, у 3500. Дослідники Массачусетського технологічного інституту розробляють алгоритми штучного інтелекту для моніторингу та захисту вразливих популяцій диких тварин
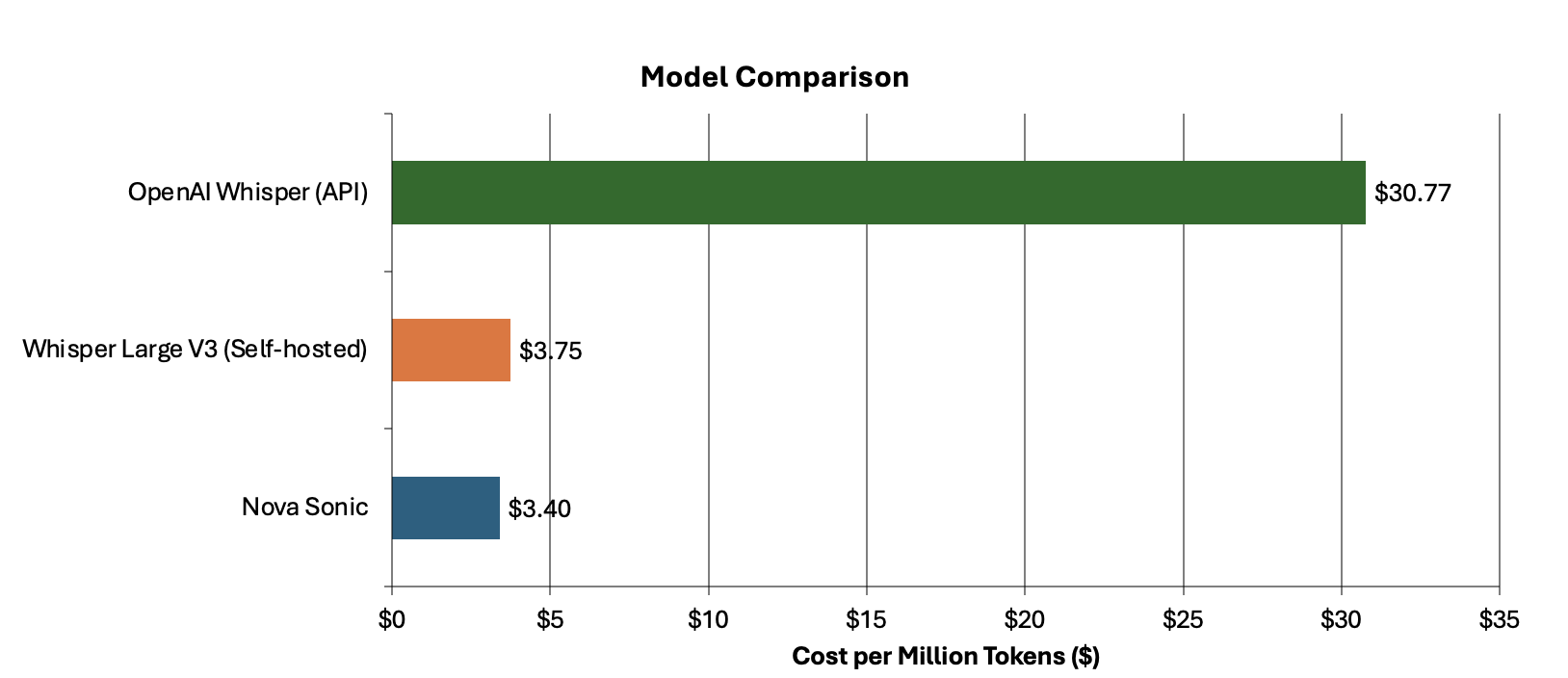
Switchboard, MD використовує транскрипцію в режимі реального часу для ефективної роботи контакт-центрів у сфері охорони здоров'я, покращуючи якість обслуговування пацієнтів та зосередженість персоналу. Їхня платформа штучного інтелекту скорочує час очікування в черзі та кількість відмов від дзвінків, підвищуючи зацікавленість пацієнтів та

Експерти з Інституту безпеки штучного інтелекту британського уряду та провідних університетів виявили слабкі місця в понад 440 тестах нових моделей штучного інтелекту, поставивши під сумнів їхню достовірність. Ці недоліки можуть потенційно поставити під загрозу безпеку та ефективність штучного інтелекту, що випускається на ринок.

Посібник MIT Teaching Systems Lab «Посібник з штучного інтелекту в школах: перспективи для тих, хто в розгубленості» має на меті допомогти викладачам шкіл та ліцеїв подолати виклики, пов'язані з інтеграцією технологій штучного інтелекту в навчальний процес. Проект включає думки понад 100 учнів та вчителів, які закликають до скромності та стимулюють дискусію про вплив штучного інтелекту на освіту.

Найкращі таланти стікаються до фінансів та технологій, залишаючи позаду традиційні офісні роботи. Міські квантові компанії пропонують високі зарплати, затьмарюючи колись престижні професії.

Дослідники MIT розробили FSNet, інструмент, який вирішує задачі енергомереж швидше, ніж традиційні методи, забезпечуючи при цьому дотримання системних обмежень. FSNet поєднує машинне навчання та оптимізацію для пошуку кращих рішень складних проблем, пропонуючи цінність для різних застосувань.