Cowork від Anthropic знаменує собою якісне зрушення від чат-орієнтованих асистентів до автономних цифрових колег, здатних самостійно планувати та виконувати робочі завдання безпосередньо на комп’ютері користувача. Контрольований доступ до файлів робить ШІ практичним інструментом для підготовки звітів, аналітики та управління даними.
Система Speech-to-Reality перетворює голосові команди на реальні об'єкти, поєднуючи технології обробки природної мови, 3D генеративний ШІ та роботизований монтаж. Користувачу досить попросити стілець, табурет або полицю, і робот-маніпулятор збере потрібний об’єкт усього за 5 хвилин.

Найсучасніші моделі штучного інтелекту від технологічних лідерів, таких як OpenAI та DeepSeek, почали дедалі частіше генерувати неправдиву інформацію. Причини цього досі невідомі. Стрімке зростання “галюцинацій” ставить під загрозу довіру користувачів до ШІ.

Сімейство Phi-4 від Microsoft – це нове покоління малих мовних моделей, які створені для вирішення складних завдань, таких як програмування, математика та планування, і які часто перевершують великі моделі. Вони наводять переконливі міркування, залишаючись при цьому ефективними для використання в середовищах з низькою затримкою.

GPT-4.5, найдосконаліший ШІ від OpenAI, має покращене розуміння природної мови, посилений емоційний інтелект та більш природні діалоги. Модель чудово справляється з креативним письмом, мозковим штурмом і вирішенням проблем, мінімізуючи галюцинації ШІ для більш надійних результатів.
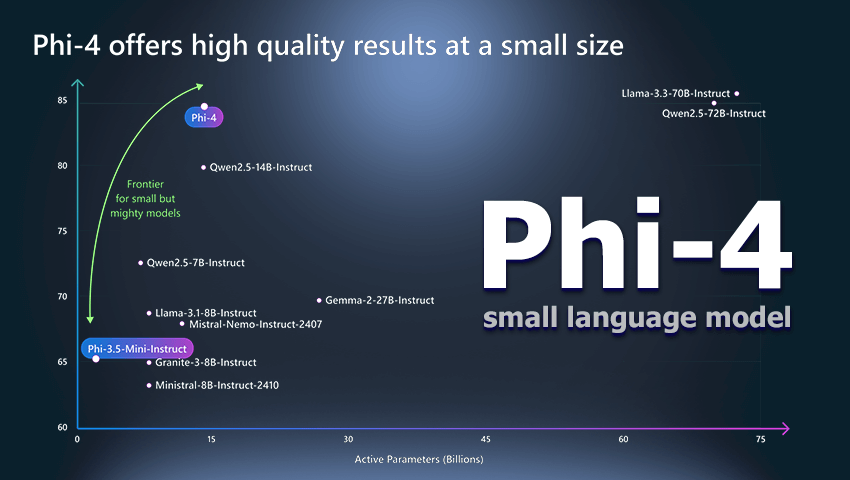
Microsoft випустила модель Phi-4 з відкритими вагами за ліцензією MIT, відкриваючи дослідникам та розробникам нові можливості у галузі ШІ. Завдяки 14 млрд параметрів Phi-4 перевершує аналоги у вирішенні математичних завдань та багатозадачності, забезпечуючи ефективну роботу при обмежених ресурсах.

Нова АІ модель від Alibaba, QwQ-32B-Preview, кидає виклик ChatGPT своїми вражаючими математичними та логічними здібностями, перевершуючи конкурентів у ключових тестах. Випущена під відкритою ліцензією, вона здатна проводити глибокі міркування, але має ще слабе розуміння здорового глузду.

Новий штучний інтелект від Anthropic – Claude 3.5 Sonnet тепер може керувати комп’ютером так само, як і людина. Модель використовує скріншоти екрана для навігації в додатках та виконання таких завдань, як натискання кнопок, введення тексту чи збір інформації.

Останній реліз від Stability AI, Stable Diffusion 3.5, презентував три нові моделі, які забезпечують підвищену якість і швидкість генерації зображень, та доступність для споживчого обладнання. Моделі безкоштовні для некомерційного використання та інтегрують сучасні функції безпеки.

Meta представила Movie Gen – AI інструмент, який створює відео високої чіткості з синхронізованим звуком, використовуючи прості текстові промпти. Модель пропонує розширені можливості для генерації та редагування відео, надаючи користувачам більше контролю над новим контентом.

Завдяки зниженню цін, збільшенню лімітів на запити і прискоренню роботи, нові моделі Gemini від Google роблять штучний інтелект доступнішим для розробників по всьому світу. Вони знижують витрати та покращують продуктивність для таких завдань, як обробка тексту, коду та мультимодальних додатків.

OpenAI o1 створено для виконання складних завдань з логічного мислення в таких сферах, як наука, програмування та математика. Імітуючи мислення людини, нова модель покращує точність відповідей і враховує питання безпеки, що сприяє більш надійному та відповідальному використанню ШІ.

Оновлена модель генерації зображень від Ideogram AI пропонує суттєві покращення, які можуть перевершити можливості таких ШІ генераторів, як MidJourney і Leonardo AI. Нові функції вже доступні, зокрема різноманітні стилі, підвищена реалістичність та розширені інструменти для текстових промптів.

Модель Gen-3 Alpha володіє потужними інструментами для створення високоякісного відео, пропонуючи користувачам безпрецедентний рівень контролю та реалістичності. Завдяки вдосконаленим функціям і винятковій якості, модель випереджає конкурентів і встановлює нові стандарти у створенні контенту за допомогою ШІ.

Компанія OpenAI презентувала GPT-4о – унікальну омнімодель, яка поєднує обробку тексту, звуку та зображень, що дозволяє їй працювати швидше та ефективніше, ніж будь-коли раніше.

SenseNova – остання модель штучного інтелекту від SenseTime Group викликала хвилю інтересу на ринку завдяки своїм вражаючим досягненням, включаючи вдосконалене опрацювання інформації, математичне мислення та лінгвістичні здібності.

Остання розробка від компанії Meta AI – Llama 3 може похвалитися неперевершеною обробкою мовлення, що підвищує її здатність виконувати складні задачі. Завдяки збільшеному словниковому запасу та розширеним функціям безпеки підвищено продуктивність і універсальність моделі.

DeepMind від Google розробив SAFE – новий метод фактології для великих мовних моделей, таких як ChatGPT. Перевірка фактів штучним інтелектом вже продемонструвала вражаючі результати, перевершуючи показники точності спеціалістів, які виконують фактчекінг.

Stability AI представила новий прорив у моделях ШІ для генерації зображень – Stable Diffusion 3. Її розширений діапазон параметрів та архітектура дифузійного трансформатора гарантують створення складних, високоякісних зображень та точний переклад тексту в візуальний контент.

Останнє творіння від OpenAI – Sora – створює захоплюючі відео, демонструючи неперевершену реалістичність візуальних композицій. Завдяки поєднанню обробки мови та генерації відео, модель може інтерпретувати текстові підказки, пристосовуватися до різних способів введення даних та імітувати динамічний рух камери.

Черпаючи натхнення від Gemini, Gemma сфокусована на відкритості та доступності, пропонуючи універсальні моделі, які підходять для різних пристроїв і фреймворків. Модель знаменує собою значний крок до демократизації ШІ, наголошуючи на прозорості та відповідальному розвитку технологій.

Новаторська модель Gemini AI має намір перевершити усі існуючі досягнення у сфері штучного інтелекту. Завдяки своїй мультимодальності, масштабованості в різних сферах і потенціалу інтегруватись в екосистему Google, Gemini AI робить значний стрибок для розвитку технологій ШІ.

Дослідники зі Стенфордського університету розробили новий підхід для оптимізації попереднього навчання ВММ. Завдяки двом ключовим методам їм вдалося значно знизити витрати, зробивши процес доступнішим для невеликих компаній та наукових груп.
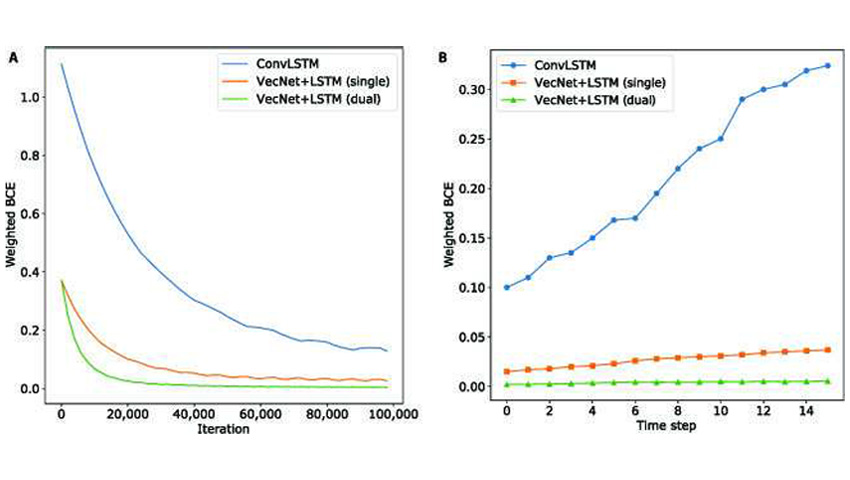
Вчені розробили новий підхід до моделювання руху, використовуючи відносну зміну положення. Вони оцінили здатність архітектур глибинних нейронних мереж моделювати рух за допомогою задач розпізнавання та прогнозування руху.
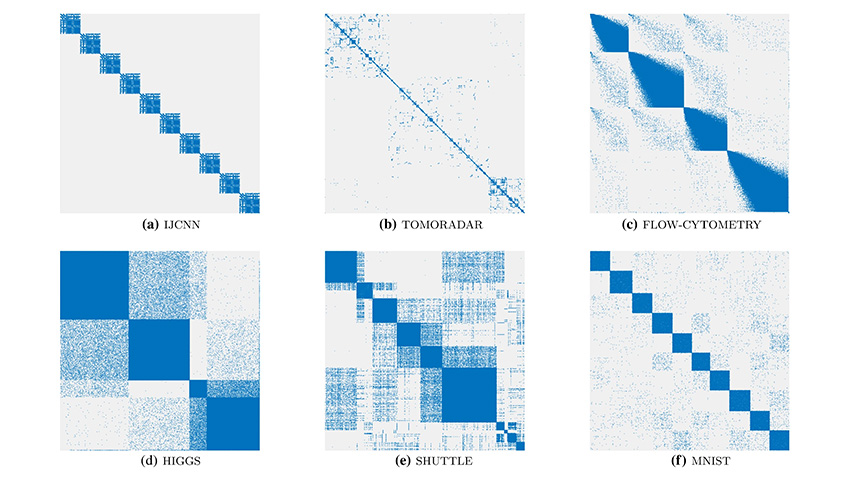
Дослідники розробили новий алгоритм ШІ, спрямований на візуалізацію кластерів даних та інших макроскопічних ознак так, щоб вони були максимально чіткими, легкими для спостереження та зрозумілими людині.
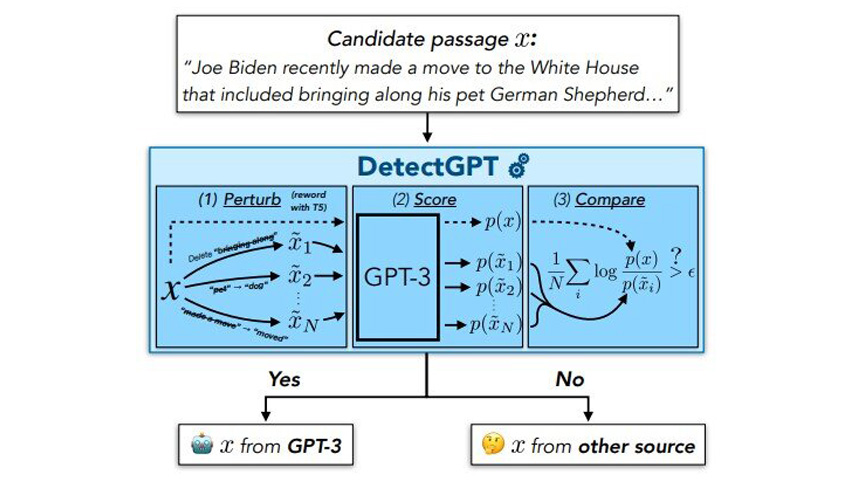
Вчені розробили модель DetectGPT, яка у 95% випадків може відрізнити текст, написаний людиною, від тексту, згенерованого за допомогою популярних мовних моделей з відкритим вихідним кодом.

Дослідники створили нову нейроморфну обчислювальну систему, що підтримує генеративний та графічний клас моделей глибинного навчання та можливість роботи з нейронними моделями глибинного навчання.

Група вчених розробила новий спосіб прогнозування викидів амінів на заводах з уловлювання вуглецю, використовуючи машинне навчання та експериментальні дані стрес-тесту, проведеного на заводі в Німеччині.
Вчені розробили перший штучний біореалістичний нейрон, який може ефективно взаємодіяти зі справжніми біологічними нейронами.

Вчені розробили біонічний палець, який може створювати 3D-карти внутрішньої структури матеріалів, торкаючись їх зовнішньої поверхні.
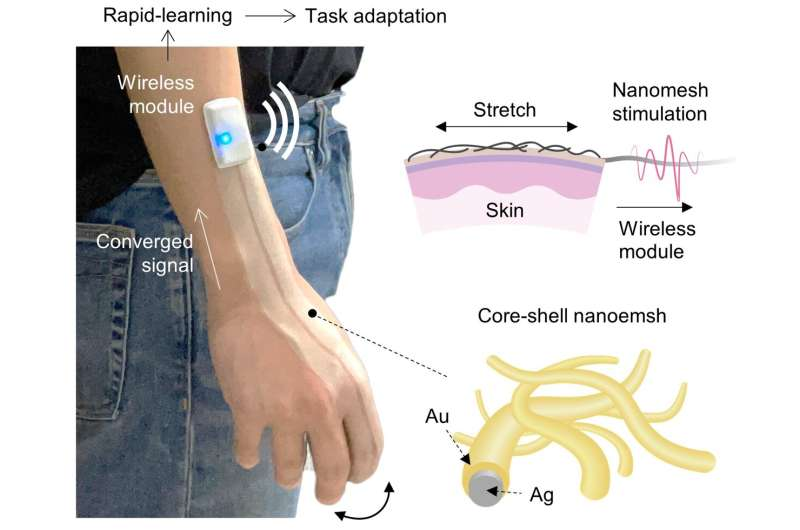
Бездротова м'яка електронна шкіра може як виявляти, так і передавати відчуття дотику, а також формувати сенсорну мережу, що відкриває великі можливості для покращення інтерактивного сенсорного спілкування.

Meta AI запустила LLaMA, серію базових мовних моделей, які можуть конкурувати або навіть перевершити найкращі моделі з існуючих, такі як GPT-3, Chinchilla та PaLM.

MusicLM – це штучний інтелект нового покоління, який створює високоякісну музику на основі текстових описів подібно до того, як DALL-E створює зображення з текстів.

Вчені з Мічиганського університету дослідили стратегії поведінки роботів для відновлення довіри між ботом і людиною. Чи зможуть такі стратегії повністю відновити довіру і наскільки вони ефективні після повторних помилок ботів?

Група дослідників створила Байєсівську машину з використанням мемристорів. Вона є більш енергоефективною, ніж існуючі апаратні рішення, і може використовуватися для критичних з точки зору безпеки додатків.

Завдяки досягненням у сфері штучного інтелекту інженери з Колорадського Університету в Боулдері працюють над новим типом тростини для сліпих або людей із вадами зору.

Дослідники Тель-Авівського університету досягли технологічного прориву: новий біологічний датчик фіксує наявність запаху та надсилає інформацію про нього роботу для інтерпретації результатів
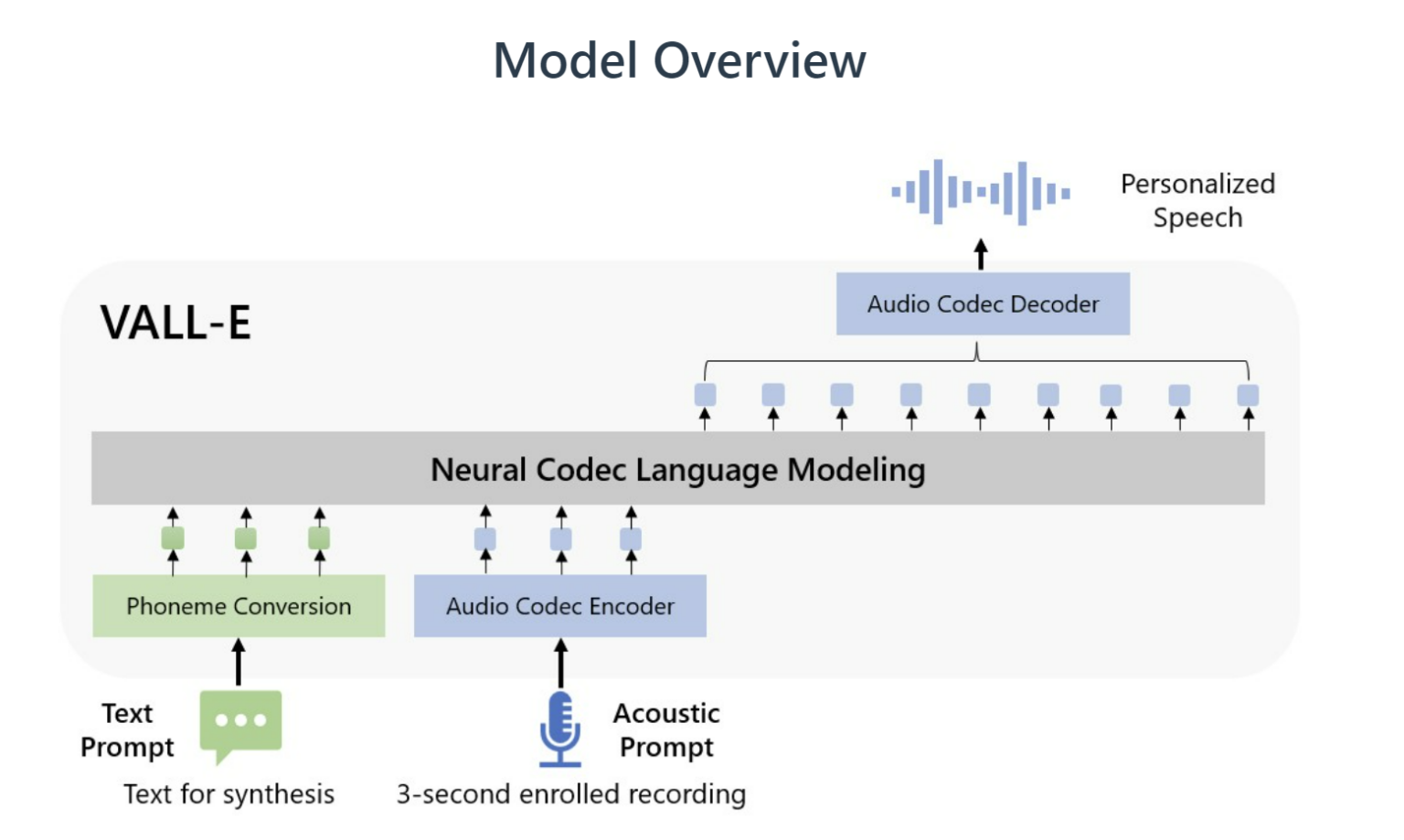
Моделі синтезу мови зазвичай потребують тривалих зразків аудіофайлів для опрацювання, тоді як VALL-E імітує голос усього за декілька секунд звукозапису.
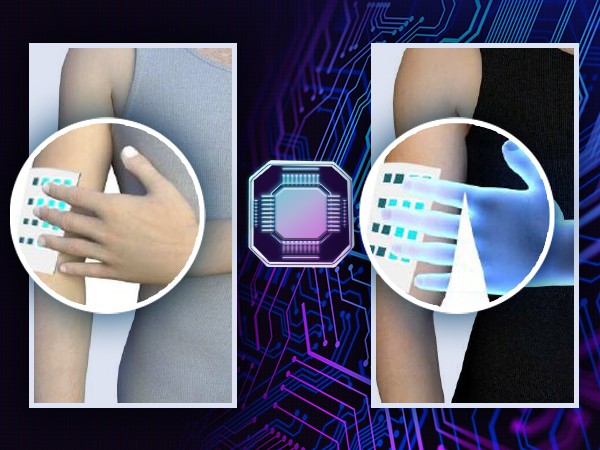
Дослідники зі Стенфордського університету розробили новий тип еластичного біосумісного матеріалу, який розпилюється на зовнішню сторону рук та може розпізнавати їх рухи.

Point E – це нова система текстового синтезу 3D-зображень, яка спочатку формує штучне уявлення про об'єкт, а потім на його основі створює кольорові хмари точок.

Безпілотні автомобілі вже давно вважаються видом транспорту нового покоління. Для забезпечення автономної навігації таких транспортних засобів необхідно впровадити багато різноманітних технологій.
Нове дослідження Тихоокеанської північно-західної національної лабораторії передбачає використання машинного навчання, аналізу даних та штучного інтелекту для виявлення потенційних ядерних загроз.

Дослідники запропонували нові способи використання ШІ разом із відеоспостереженням для роздрібної торгівлі, щоб краще розуміти поведінку споживачів та адаптувати планування магазинів для збільшення продажів.
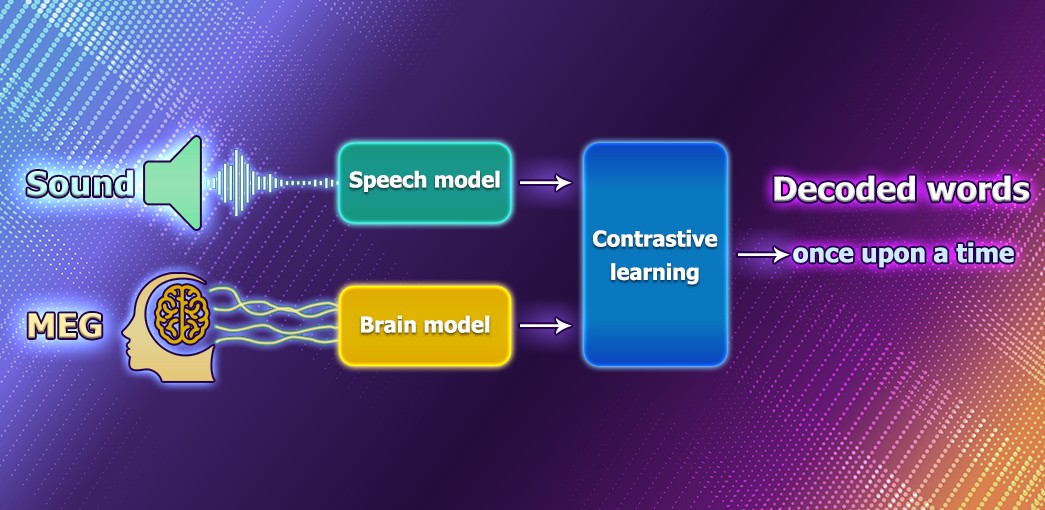
Декодування мовлення на основі активності головного мозку було давньою метою неврологів і клініцистів. Наразі, компанія Meta представили результати дослідження моделі ШІ, яка може декодувати мову, використовуючи неінвазивні методи дослідження.

Додаток Look to Speak від Google здатний допомогти людям з порушеннями моторики та проблемами мовлення легше спілкуватися. Використовуючи лише очі, програма дозволяє вибирати заздалегідь підготовлені фрази і озвучувати їх.

Дослідники з Массачусетського технологічного інституту розробили техніку машинного навчання, яка точно фіксує та моделює основну акустику місцевості лише з невеликої кількості звукових записів.

До 2050 року людству доведеться майже вдвічі збільшити світові запаси продовольства, щоб забезпечити кожного жителя планети достатньою кількістю їжі. Оскільки зміна клімату відбувається дедалі швидше, водні ресурси скорочуються, а орні землі руйнуються, гарантувати сталий розвиток стане серйозним викликом.

За останнє десятиліття різке зростання вартості виробництва відеоігор класу ААА стало однією з найбільш серйозних проблем в ігровій індустрії. Студії завжди шукають технології, які б могли допомогти знизити вартість розробки ігор. Останні досягнення в нейронних моделях генерації зображень вселяють надію, що реалізація цієї мрії може бути не такою вже далекою.

Чи можуть комп’ютери мислити? Чи можуть моделі штучного інтелекту (ШІ) бути свідомими? Ці та подібні запитання часто виникають під час обговорення нещодавнього прогресу ШІ, досягнутого за допомогою моделей природної мови GPT-3, LAMDA та інших перетворювачів. Тим не менш, вони все ще суперечливі і знаходяться на межі парадоксу, тому що зазвичай існує безліч прихованих припущень і помилкових уявлень про те, як працює мозок і що означає мислення. Немає іншого шляху, окрім як точно обґрунтувати ці припущення, а потім дослідити, як саме обробка інформації людиною може бути відтворена машинами.

Зараз вже нікого не здивувати фільтрами, які покращують якість фотографій. Але реставрація старих портретів поки що залишає бажати кращого. Старі фотографії бувають надто розмитими, тому звичайні методи підвищення чіткості зображень на них не працюють.

Компанія Facebook виклала у відкритий доступ проєкт NLLB (No Language Left Behind). Головною особливістю цієї розробки є охоплення понад двохсот мов, у тому числі рідкісних мов африканських та австралійських народів. Крім того, Facebook застосував новий підхід до моделі машинного навчання, де переклад здійснюється безпосередньо з однієї мови на іншу, без перехідного перекладу англійською мовою.

Анімовані аватари вже давно стали частиною нашого життя. А ось реалістичне моделювання анімації одягу досі залишалося невирішеним завданням.
З одного боку, сучасні методи фізичного моделювання можуть генерувати реалістичну геометрію одягу з інтерактивною швидкістю. З іншого, моделювання фотореалістичного зовнішнього вигляду зазвичай потребує фізичного рендерингу, який занадто дорогий для інтерактивних програм.
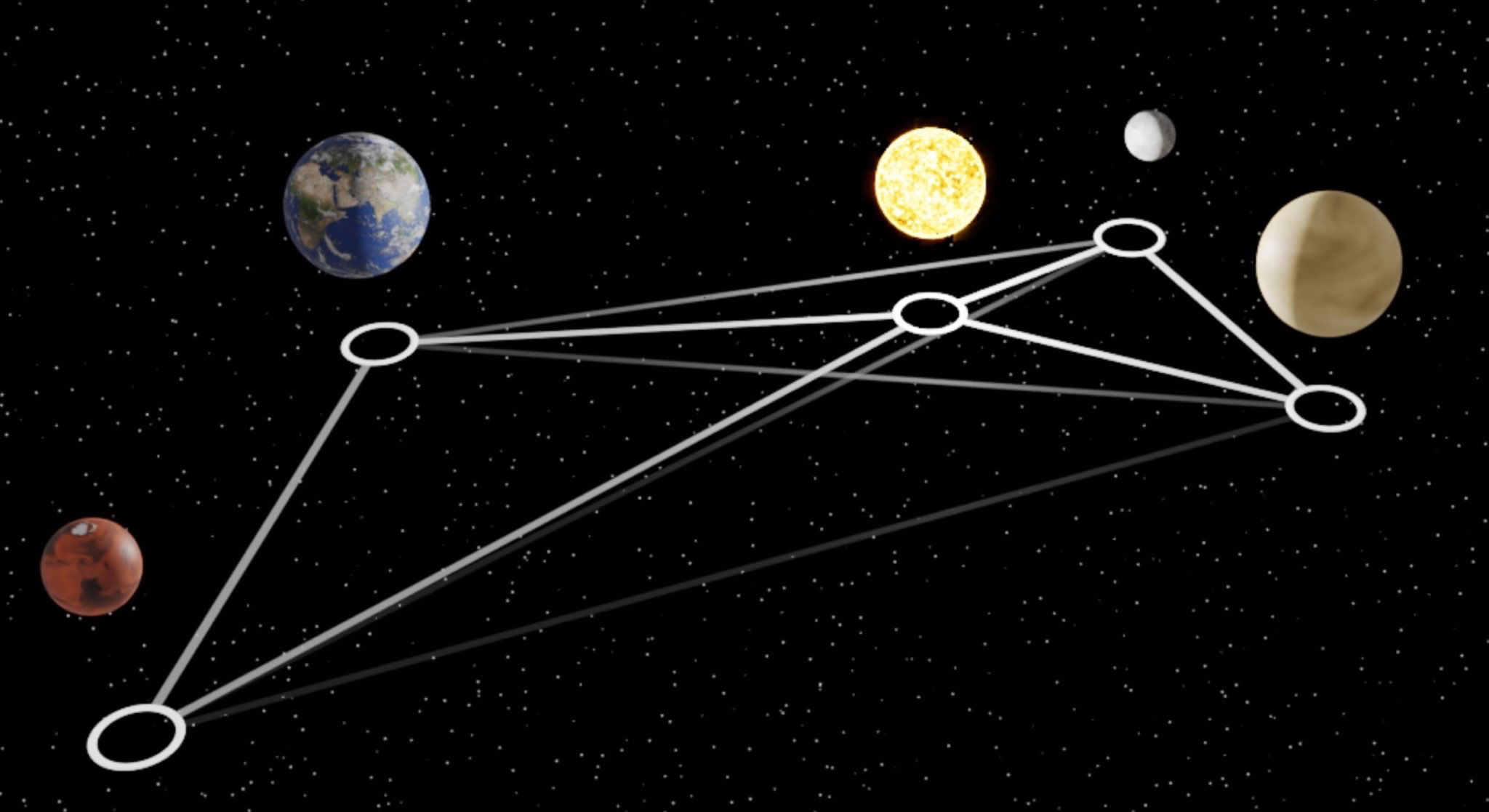
Група вчених, що використовують машинне навчання, «заново відкрила» закон Всесвітнього тяжіння.
Для цього вони навчили «графічну нейронну мережу» моделювати динаміку Сонця, планет і великих планет Сонячної системи з 30 років спостережень. Потім вони використали символічну регресію, щоб виявити аналітичне вираження закону сили, неявно вивченого нейронною мережею.