
Developers are ditching laptops for Amazon Bedrock AgentCore Runtime, offering isolated environments for coding agents to run efficiently. Say goodbye to security risks and collisions with a dedicated workspace, real shell, and seamless integration with tools like GitHub and Jira.
Amazon SageMaker AI now enables ML inference with fully homomorphic encryption (FHE), keeping data encrypted throughout the process. This approach allows for secure cloud-based ML applications in sensitive industries like healthcare, energy, and telecommunications.

NVIDIA introduces RTX Spark, a superchip for Windows PCs, offering enhanced gaming experience with AI and ray tracing technologies. Collaboration with top game developers in Korea, including KRAFTON and NC, to bring popular titles to RTX Spark-powered systems, igniting excitement in the gaming community.
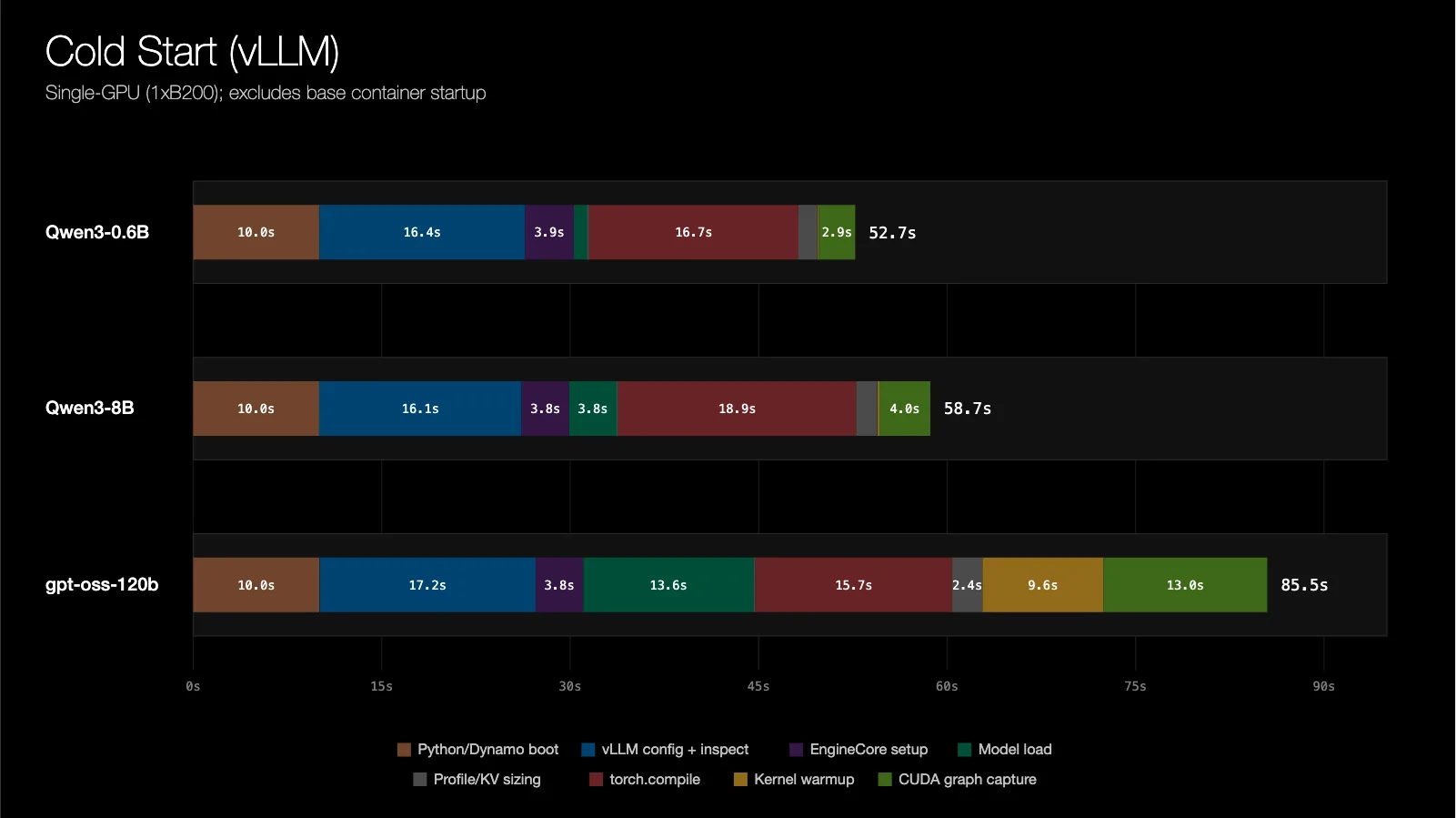
NVIDIA introduces Dynamo Snapshot for AI inference on Kubernetes, reducing cold-start latency and improving scalability during demand spikes. CRIU and cuda-checkpoint work together to checkpoint GPU and CPU states, allowing for seamless restoration and minimal downtime.

MIT's SERC symposium focused on AI's impact on society, featuring talks on air pollution forecasting and ethical AI deployment. Panel discussions highlighted challenges of aligning AI with human values and governance of AI systems.

GeForce NOW offers 18 new games this month, including the highly anticipated NTE: Neverness to Everness. Explore surreal worlds and classic remakes instantly via cloud streaming, with no downloads necessary.

MIT, Georgia State University, and partners launch PATH to provide industry-aligned AI training for community colleges, emphasizing hands-on learning and collaboration. Program aims to develop practical AI skills and mindsets for a workforce prepared for the future.
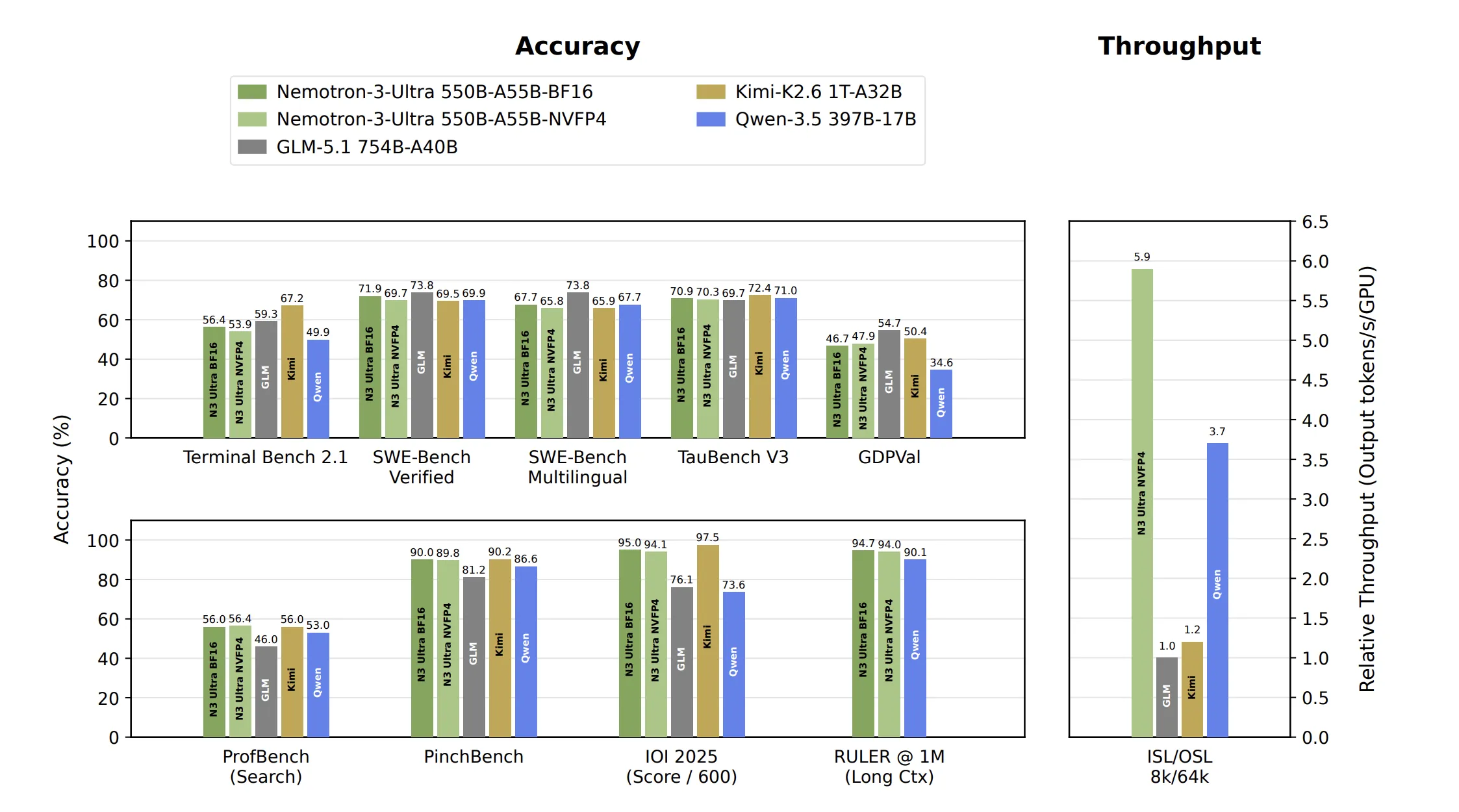
NVIDIA introduces Nemotron 3 Ultra, a 550 billion parameter model with hybrid Mamba-Attention architecture, offering 6x higher inference throughput. The model uses Multi-Token Prediction for faster generation and achieves stable, accurate training with NVFP4 datatype.
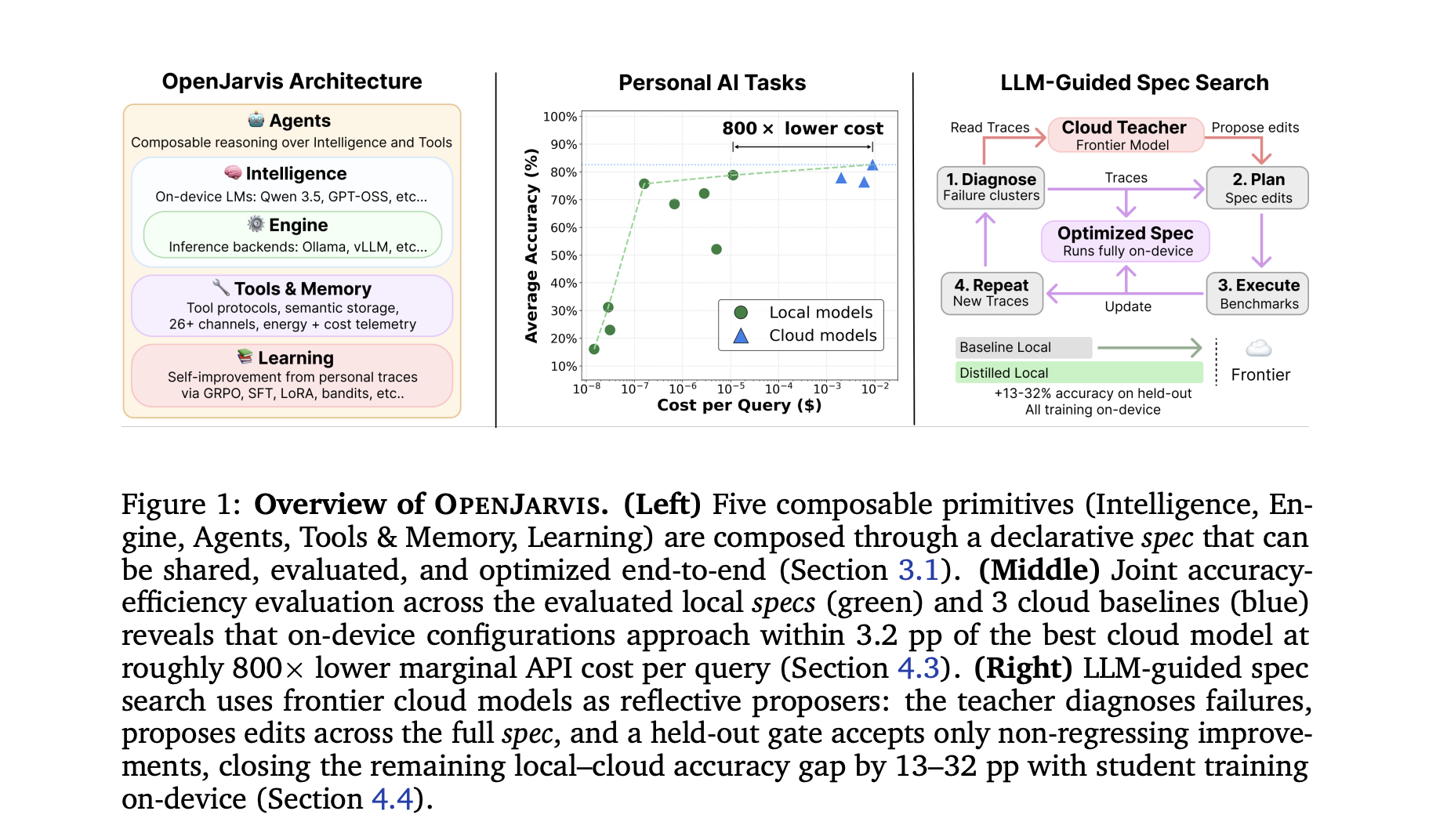
Stanford University and Lambda Labs researchers developed OpenJarvis, an on-device framework that rivals cloud models in efficiency and latency. OpenJarvis allows easy composition of models, agents, and memory, with a unique LLM-guided spec search for optimization.
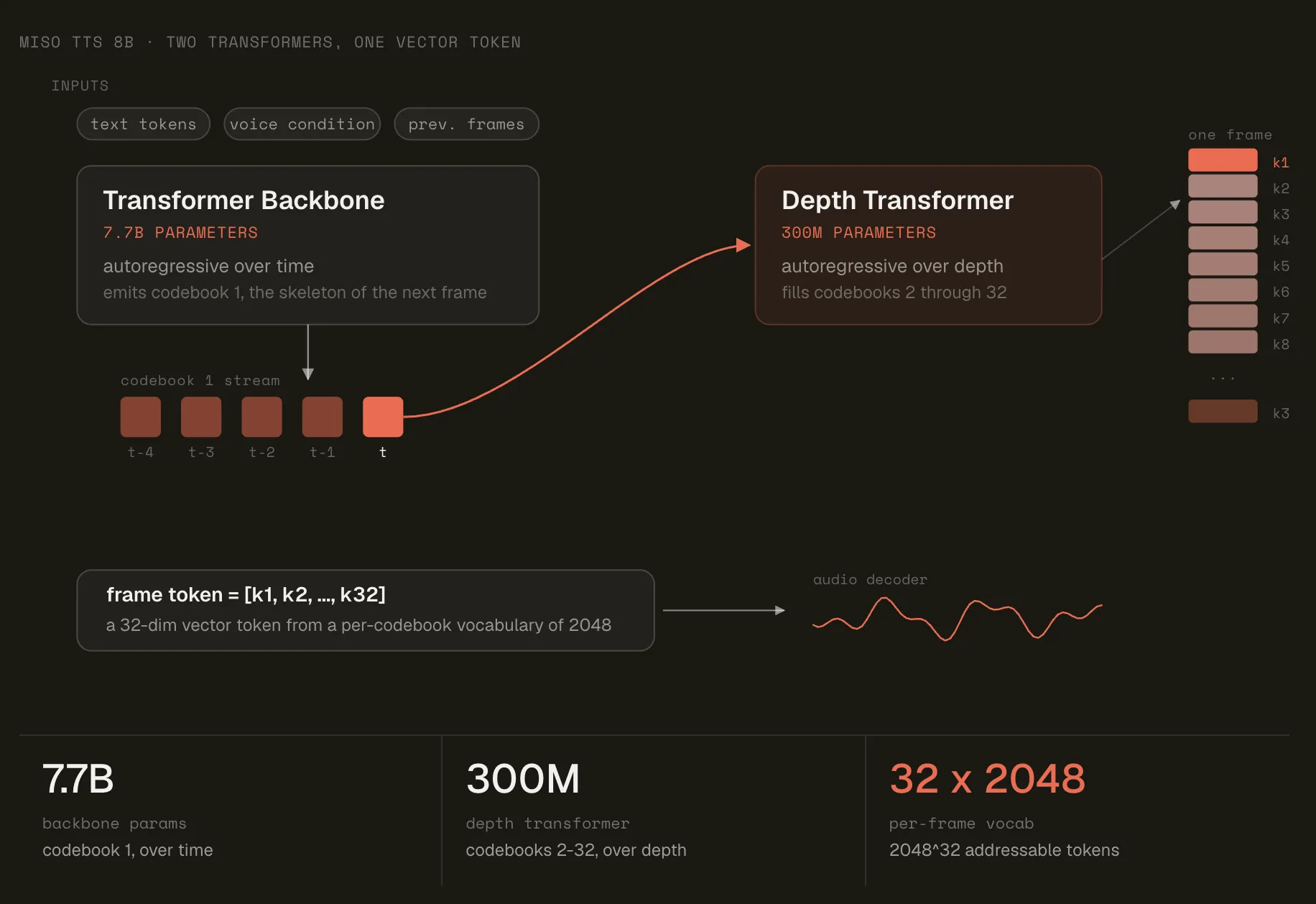
Miso Labs introduces MisoTTS, an 8-billion-parameter text-to-speech model with RVQ technology for expressive speech generation. It addresses the vocabulary size problem and interlocutor tone, achieving 110ms latency.
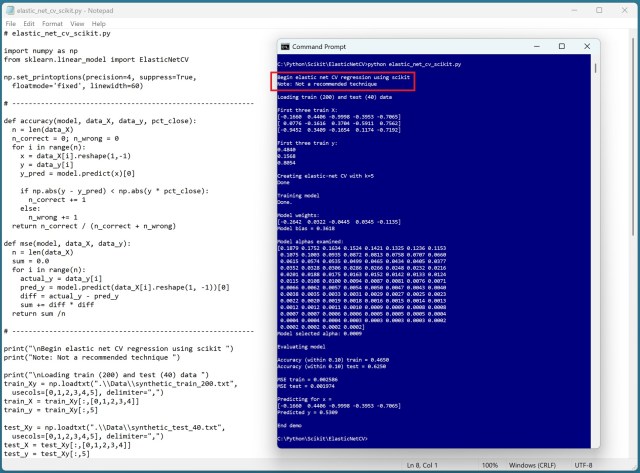
Cross-validation in machine learning is deemed ineffective by a seasoned expert due to numerous flaws in both k-fold and leave-one-out techniques. The lack of generalizability and unreliable hyperparameter tuning make cross-validation a questionable practice in real-world scenarios.

The NSF has renewed funding for MIT's IAIFI, focusing on AI advancing physics and physics improving AI. Collaborative research across physics and AI is leading to groundbreaking discoveries and innovative scientific approaches.
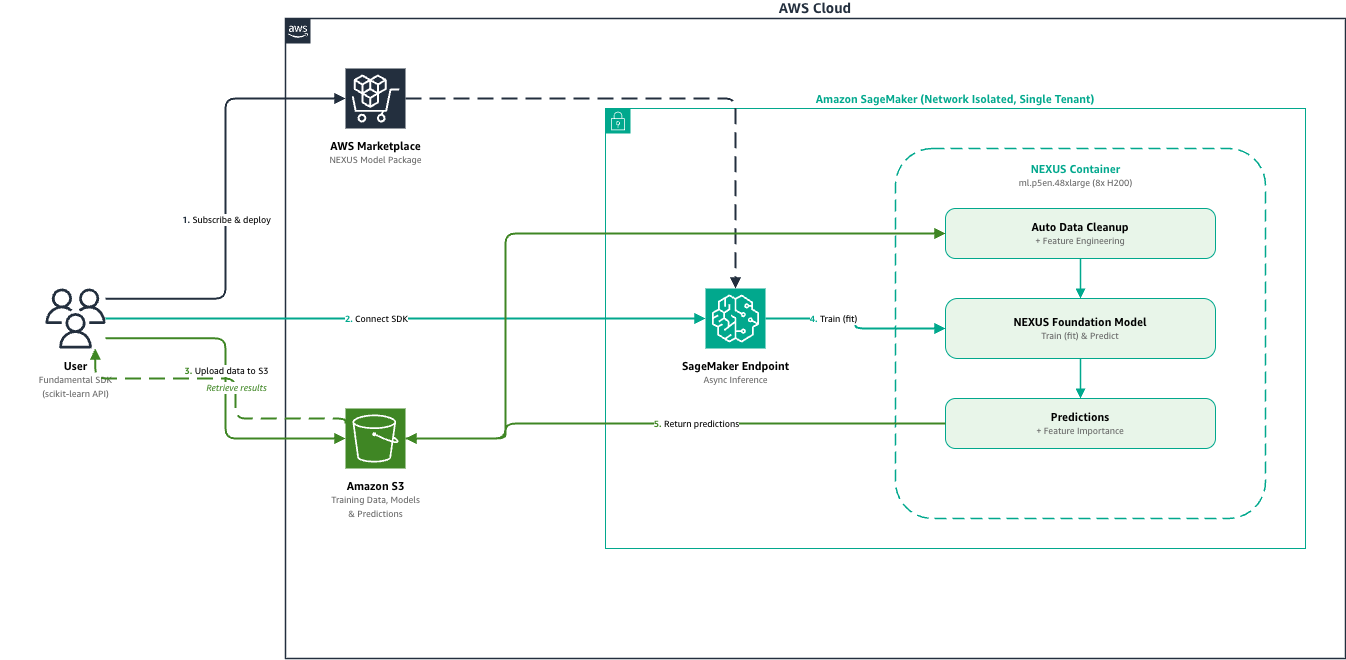
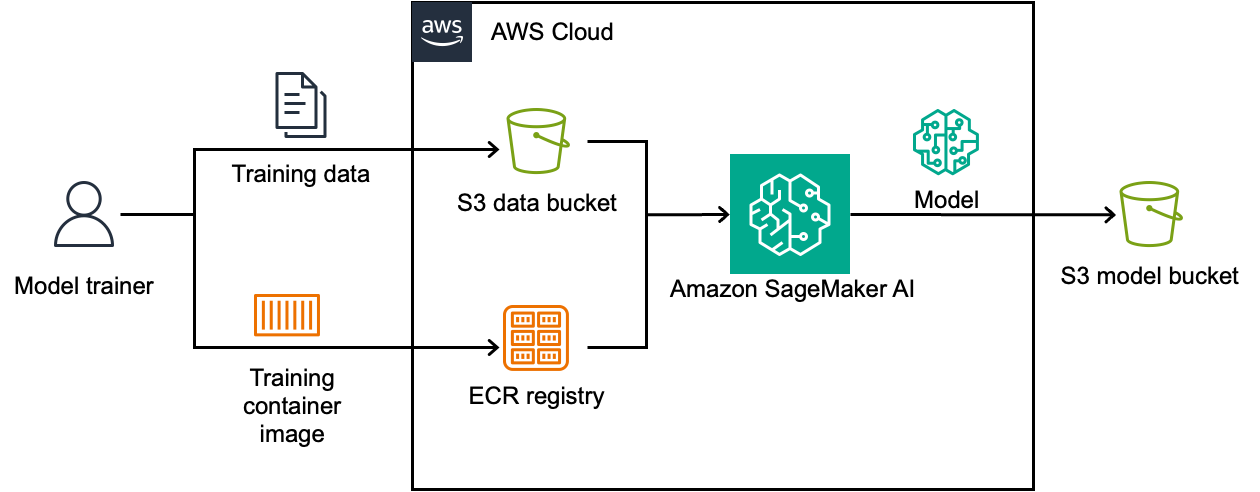
Amazon SageMaker AI now supports Fundamental's NEXUS model for accurate tabular data predictions in days. NEXUS offers deterministic results, native tabular understanding, and non-sequential reasoning for structured data analysis.
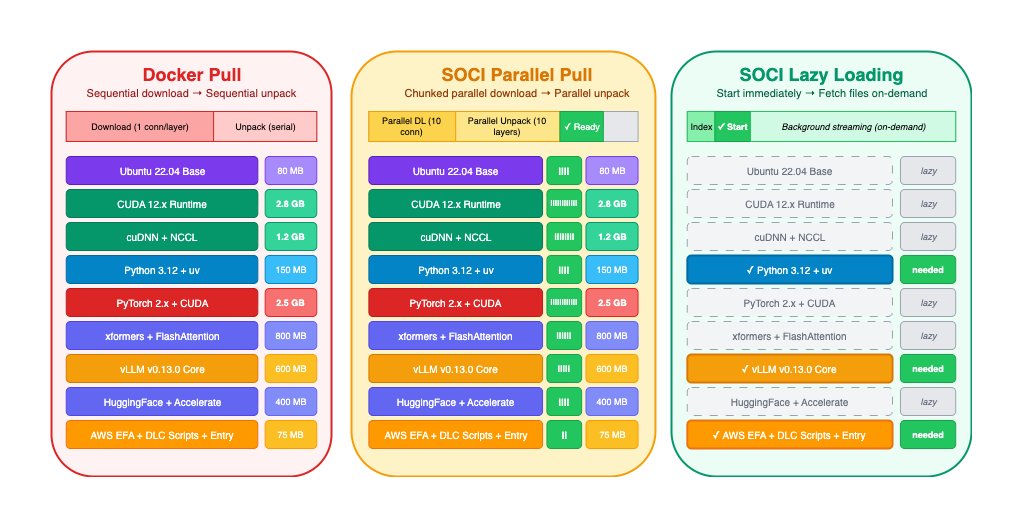
Deep Learning AMI and AWS Deep Learning Containers now support SOCI snapshotter and index for efficient container image management. SOCI's lazy loading reduces network bandwidth usage and improves container startup times, benefiting organizations managing large container images in cloud environments.
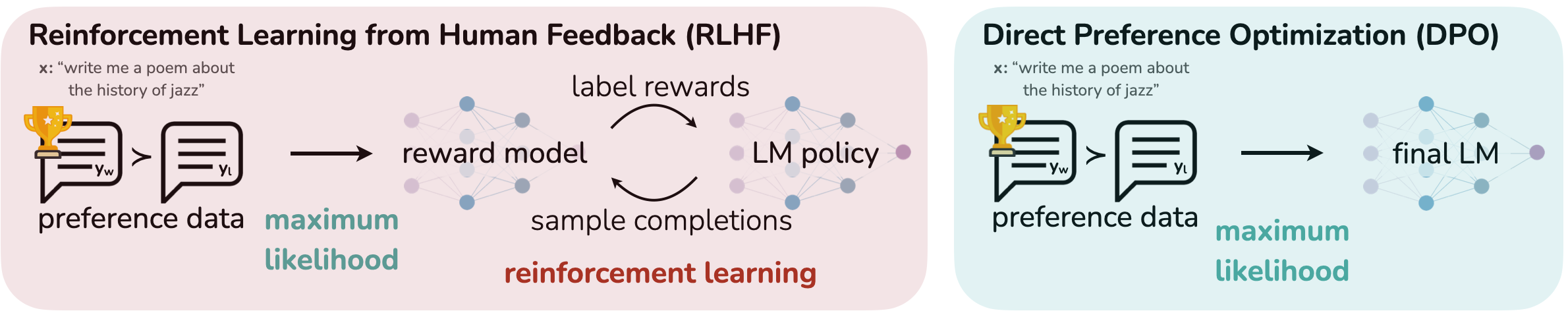
AI agents must select the right tools for tasks to avoid errors and delays. Learn how SFT and DPO improve tool-calling accuracy in language models for reliable automation.