
Meta's AI moderation software inundates US ICAC taskforce with low-quality reports, hindering child abuse investigations. New Mexico lawsuit alleges Meta prioritizes profits over child safety, while company defends changes made to platform protections.
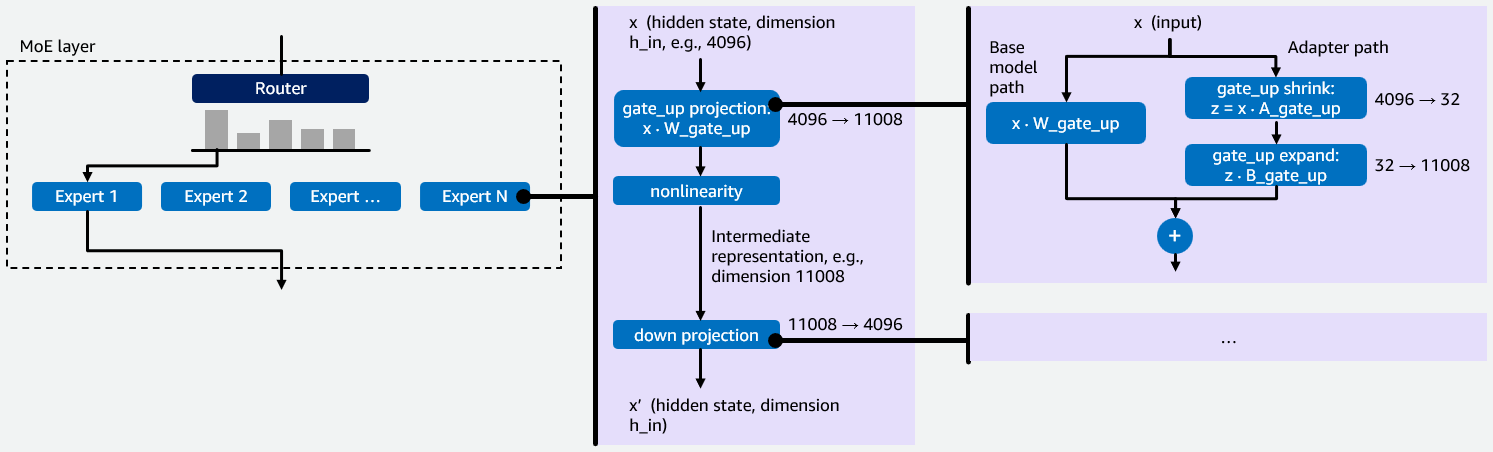
Efficiently share GPU capacity with Multi-LoRA for MoE models like GPT-OSS. Amazon optimizations improve performance for hosting dense models.
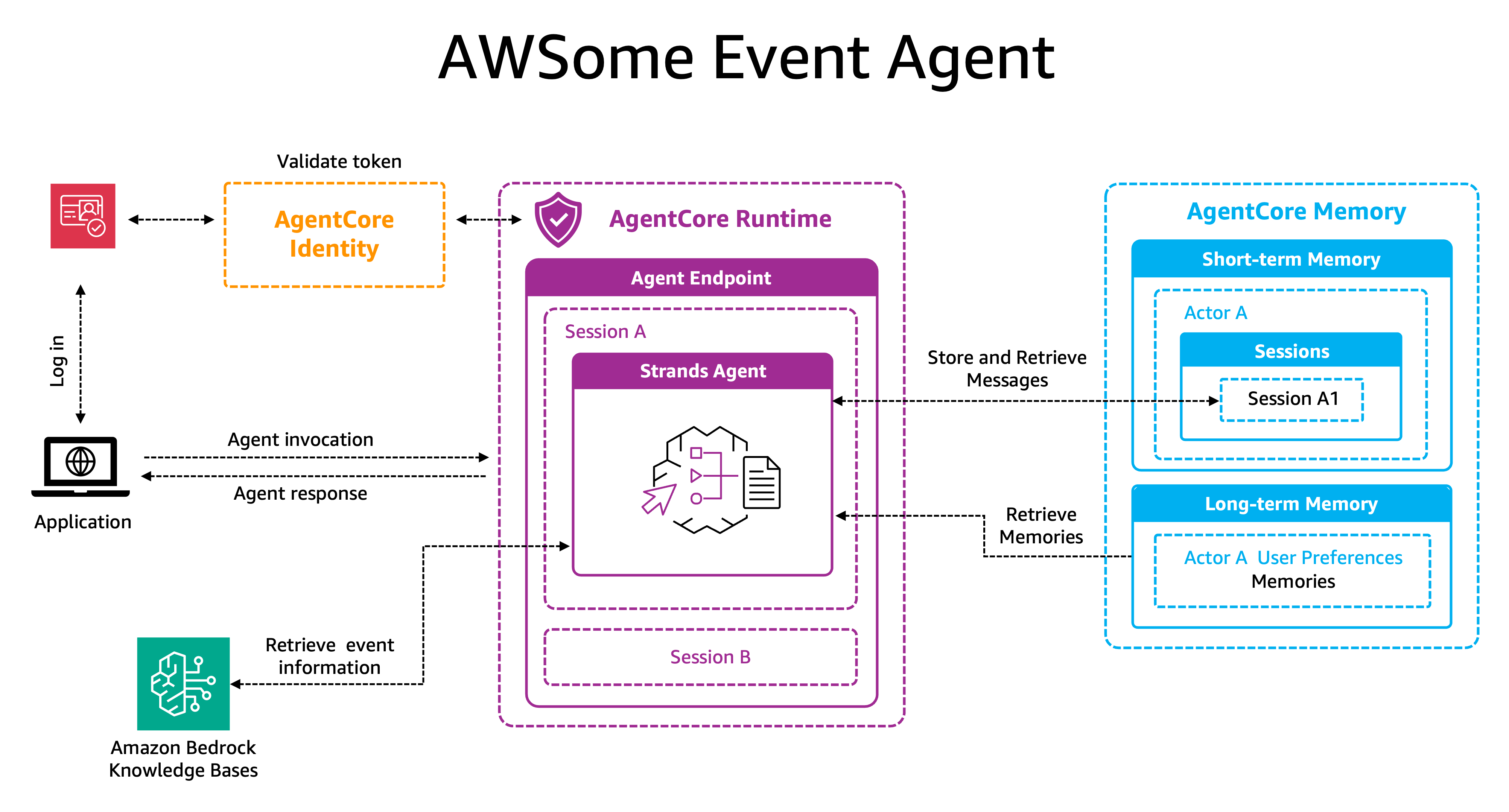
AI assistants at events lack personalized guidance. Amazon Bedrock AgentCore enables quick deployment of intelligent event assistants, enhancing attendee experiences.

Tech equity campaigners criticize government for involving private tech companies in AI deployment. Ministers consult Tony Blair's thinktank and companies like IBM, Accenture, and former Google and Facebook executives.

Nvidia continues to exceed Wall Street's expectations with higher than expected revenues from its data center business, driven by AI infrastructure investments. The chipmaker's dominance in the market is highlighted by its 75% year-over-year growth and staggering $120bn total profit for the fiscal year.

GenAI models often lack understanding of physics, leading to impractical 3D designs. MIT's PhysiOpt system enhances designs by incorporating physics simulations for structurally sound objects, allowing users to create unique and functional items with ease.

MIT researchers developed a method to accelerate training of large language models by using idle processors. By training a smaller model to predict outputs of a larger model, they doubled training speed without sacrificing accuracy.
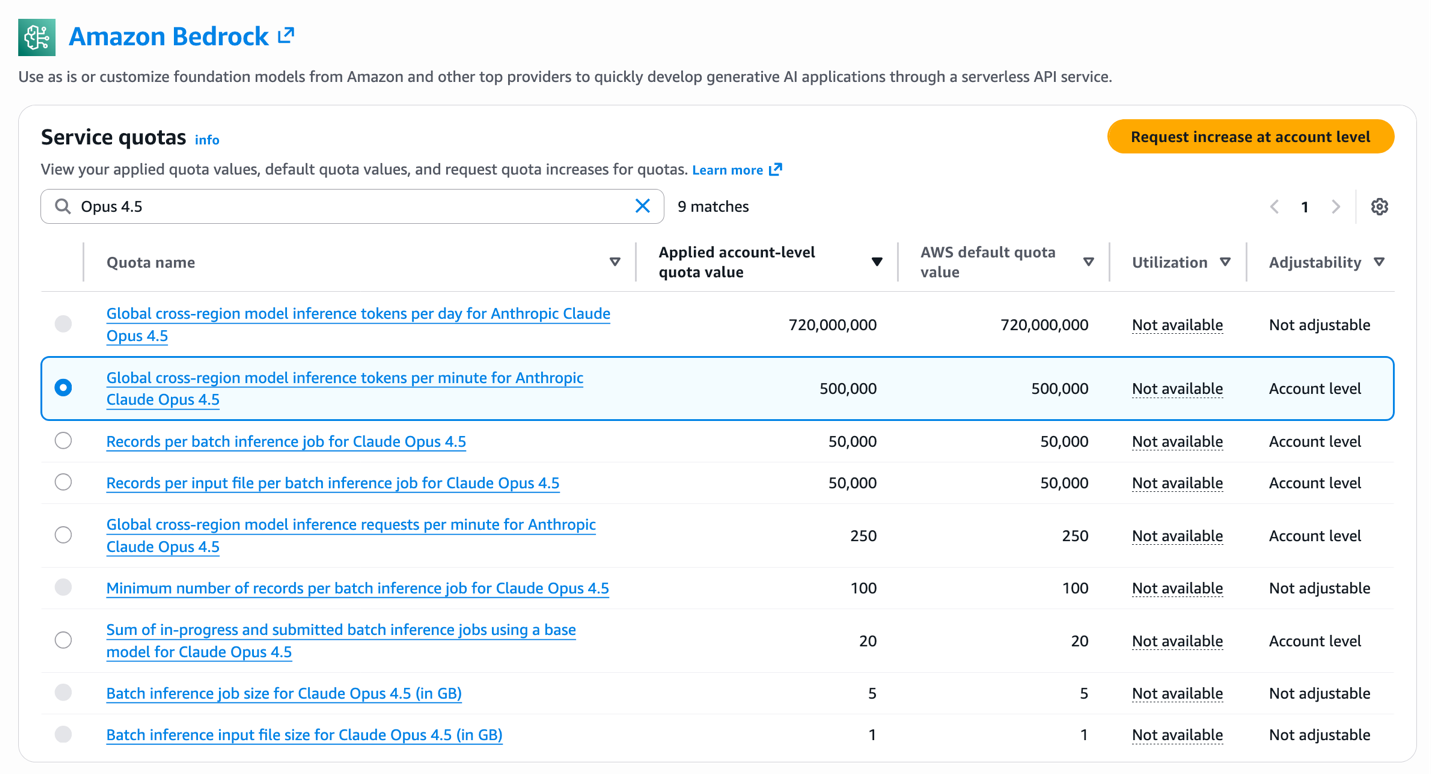
Organizations in Thailand, Malaysia, Singapore, Indonesia, and Taiwan can now access Anthropic's AI models through Global CRIS on Amazon Bedrock, offering higher quotas, cost efficiency, and intelligent request routing for AI use-cases like chatbots and financial analysis systems. Global CRIS enables seamless distribution of inference processing across AWS Regions, ensuring responsiveness and r...

Tech billionaires pour money into California midterms; India challenges US-China AI dominance at summit. AI anxiety sparks worker movement.

Sammy Azdoufal stumbled upon global robot vacuum data, revealing mind-boggling implications for tech. Age is irrelevant - his accidental hack is the focus.
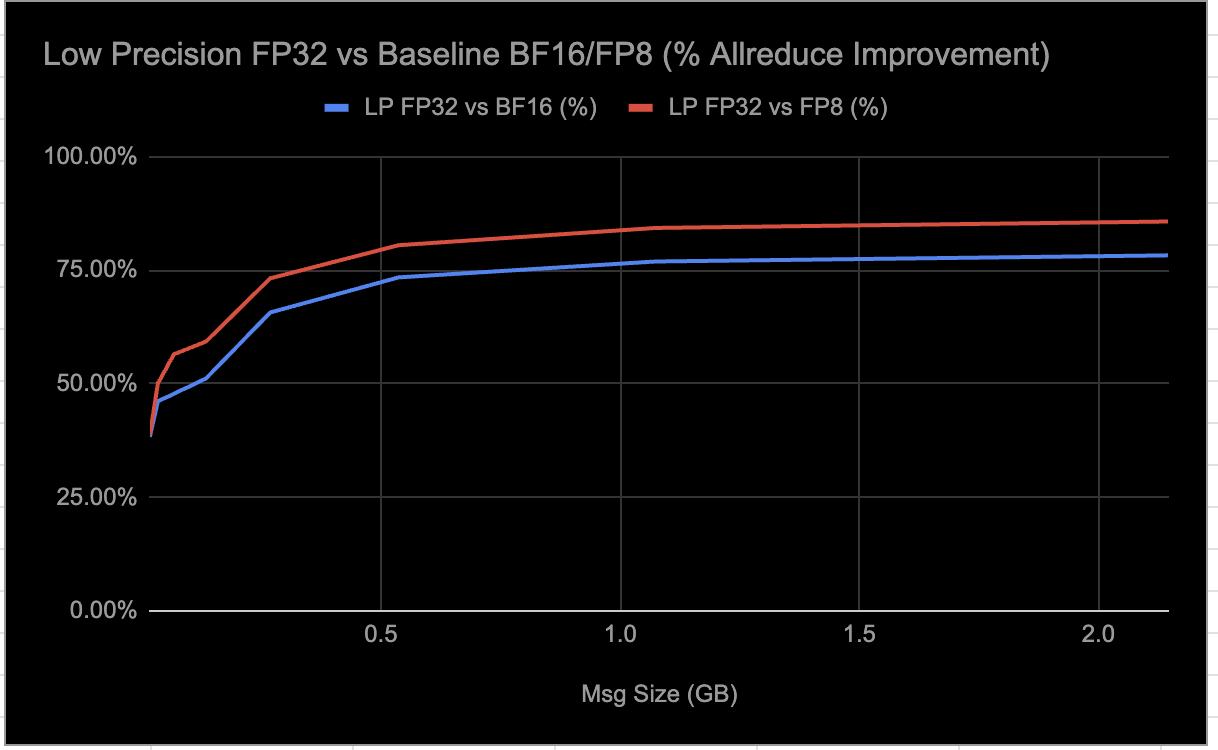
Meta open-sources RCCLX, integrating CTran for AMD platforms, enhancing AllToAllvDynamic. DDA and Low Precision Collectives boost AMD performance significantly, reducing latency by up to 30%.

Meta's owner buys $60bn AI chips from AMD, part of $660bn US tech AI spending trend, a 'big bet' on artificial intelligence. Analyst suggests it may signal a pivot in Meta's AI strategy.

US struggles with delays and cancellations of new datacenters amid AI boom due to supply chain issues, energy shortages, and local opposition. Investors cautious of AI bubble potential impacting infrastructure expansion.

Anthropic faces Pentagon penalties over AI model dispute. Defense officials clash on military use of Anthropic's powerful AI model, Claude.
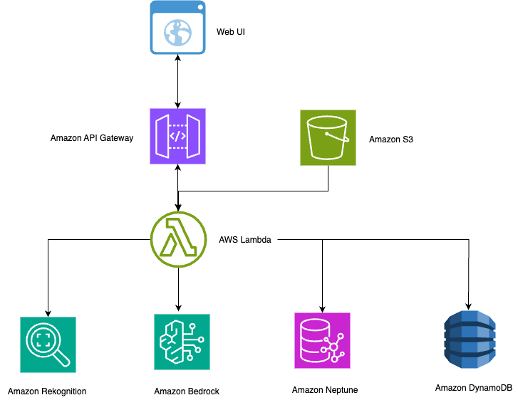
Intelligent photo search systems use computer vision and natural language processing to revolutionize photo organization. Amazon Rekognition, Neptune, and Bedrock enable personalized search with complex relationship mapping for thousands of images.