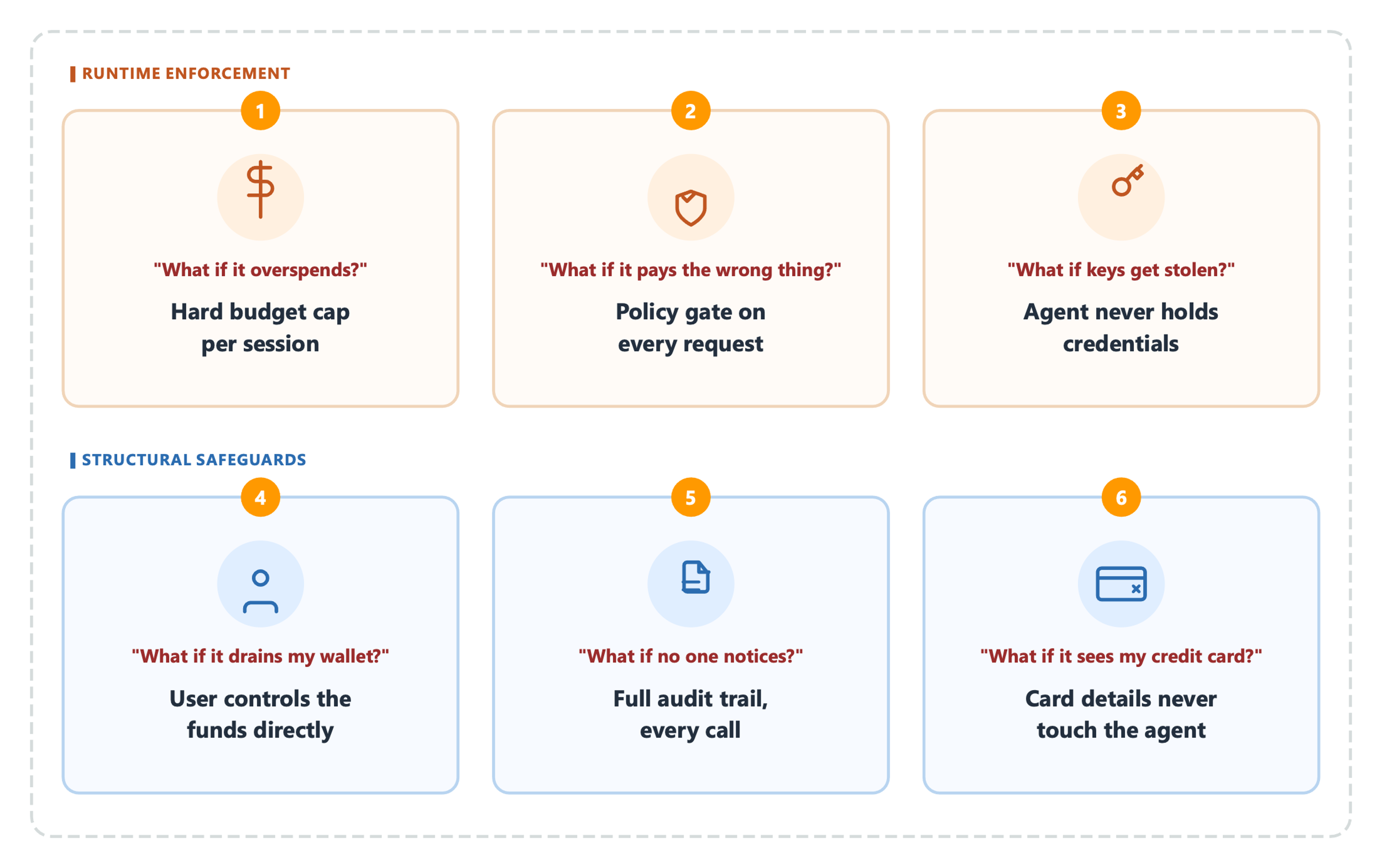
Amazon Bedrock AgentCore payments, in partnership with Coinbase and Stripe (Privy), allows agents to access paid resources on behalf of end users. AgentCore addresses risks like runaway spending and lack of end user consent in autonomous payment systems.

OpenAI's GPT-5.5, GPT-5.4, and Codex now available on Amazon Bedrock for advanced AI applications. High-performance inference engine for complex tasks.
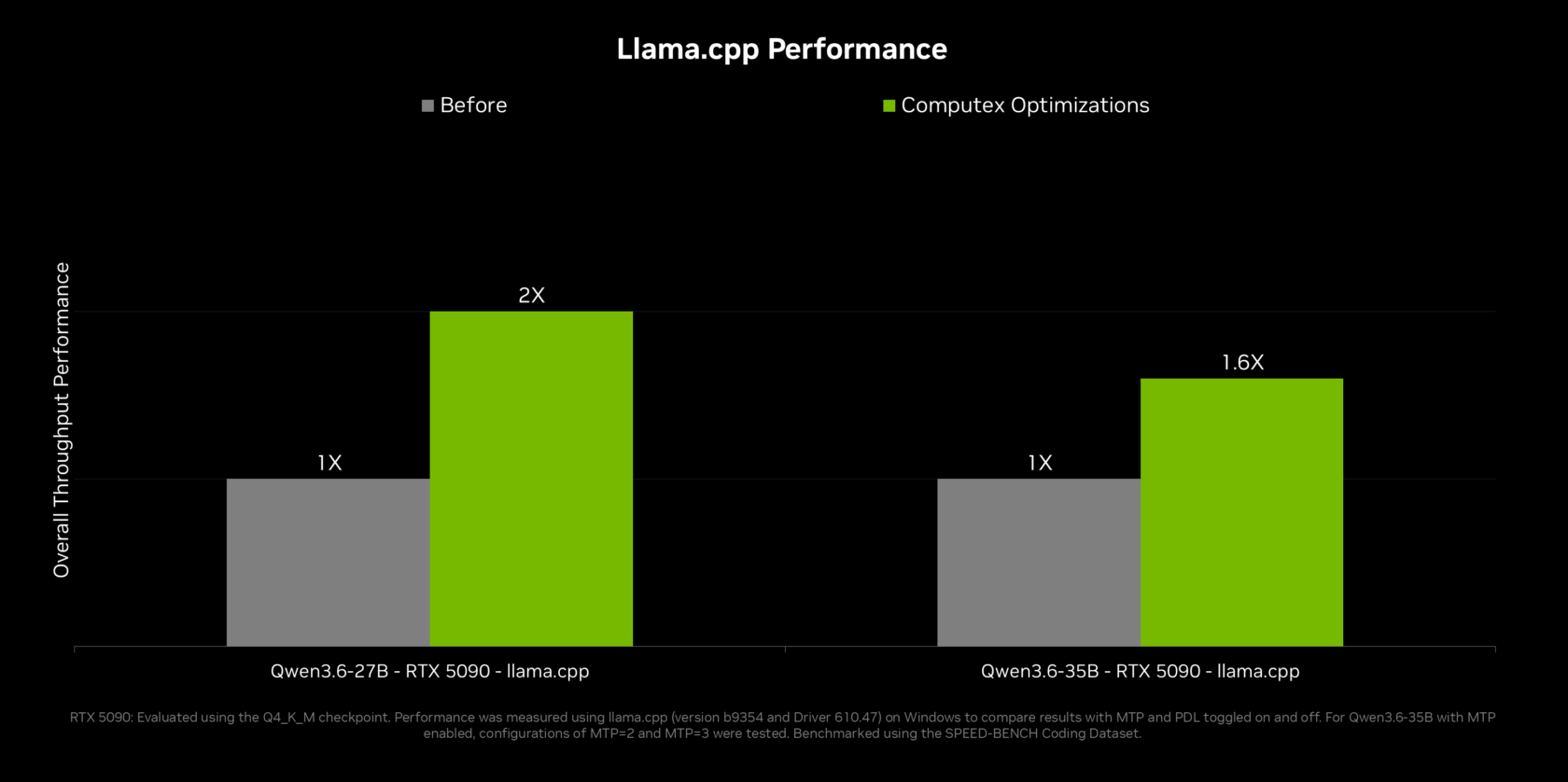
NVIDIA introduces RTX Spark PCs for personal agents at GTC Taipei, with new AI compute and memory capabilities. Partnership with Microsoft brings secure on-device agents to Windows, along with updates for Hermes Agent and OpenClaw.
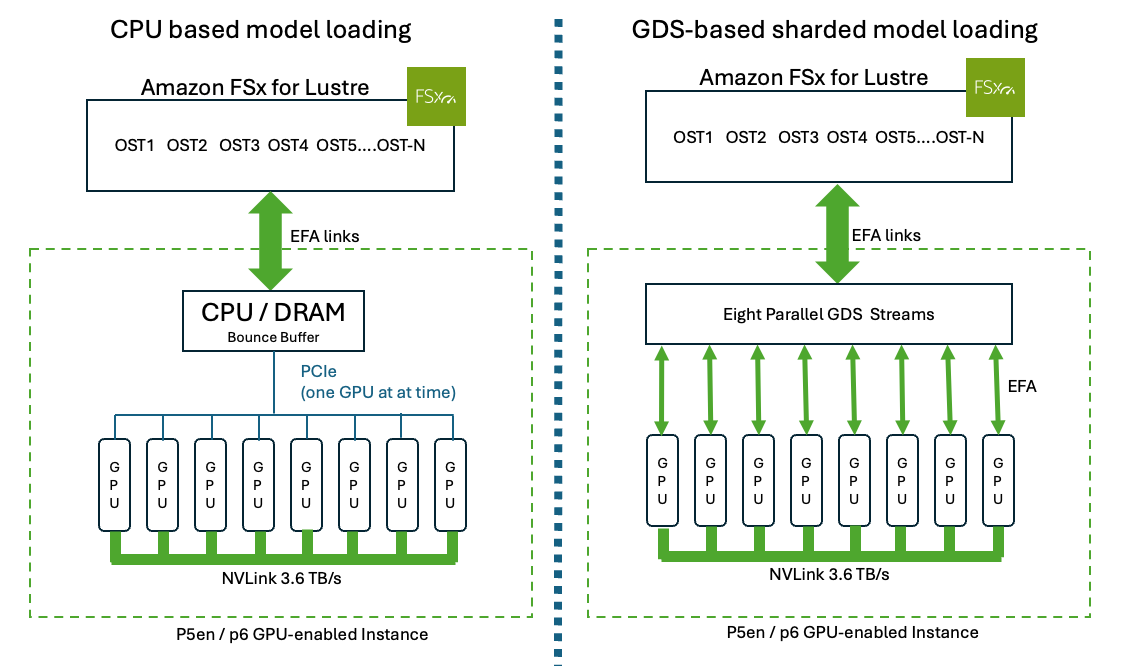
Large language models (LLMs) on AWS GPU instances face lengthy model load times. Amazon FSx for Lustre and NVIDIA GPUDirect Storage (GDS) drastically reduce load times, improving total time to first token (TTFT) from minutes to seconds for models like Llama 3.1 with 405B parameters on AWS P6e UltraServers.
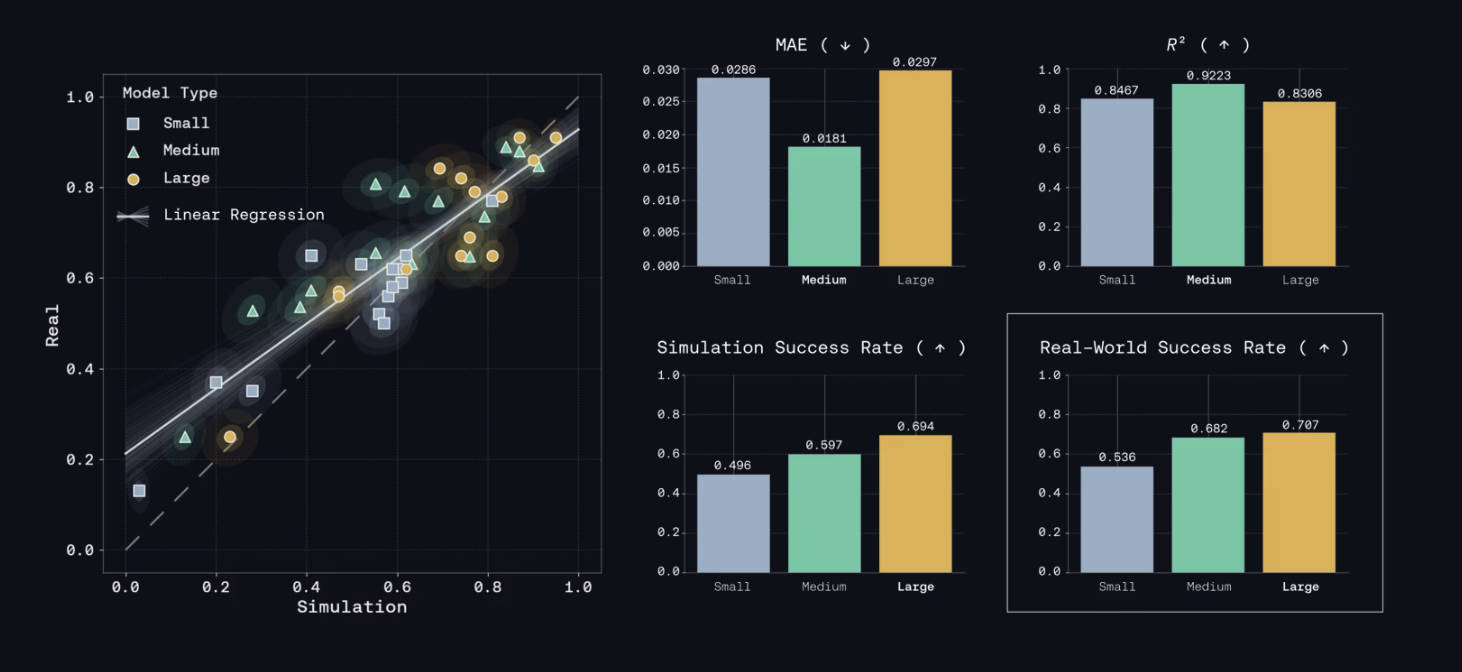
Genesis AI released Genesis World 1.0, featuring Nyx, Quadrants, and a simulation interface to accelerate robotics model development through simulation. Evaluation in under 0.5 hours yields bit-exact results, showing a correlation of 0.8996 between simulation and on-hardware rollouts.
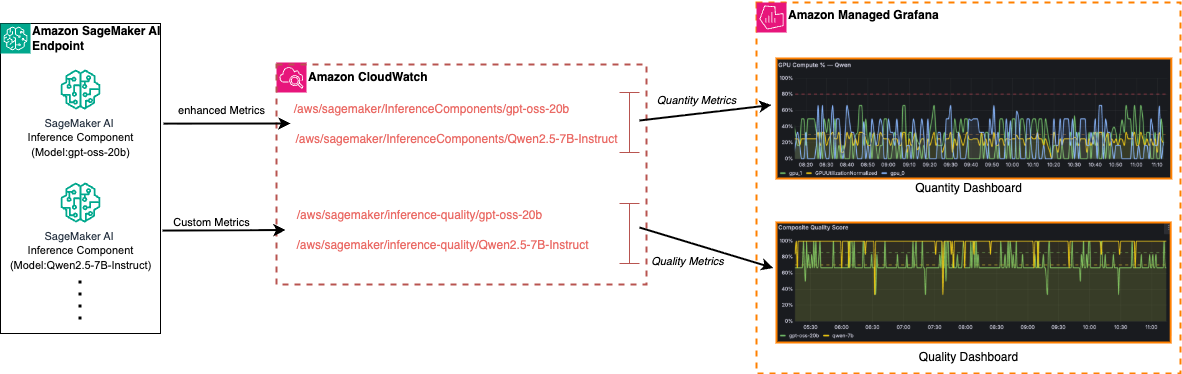
Deploying large language models (LLMs) on Amazon SageMaker AI Inference requires comprehensive observability for monitoring both infrastructure quantity and LLM quality. Monitoring metrics like latency, errors, and response accuracy is crucial for optimizing cost, performance, and output quality over time.
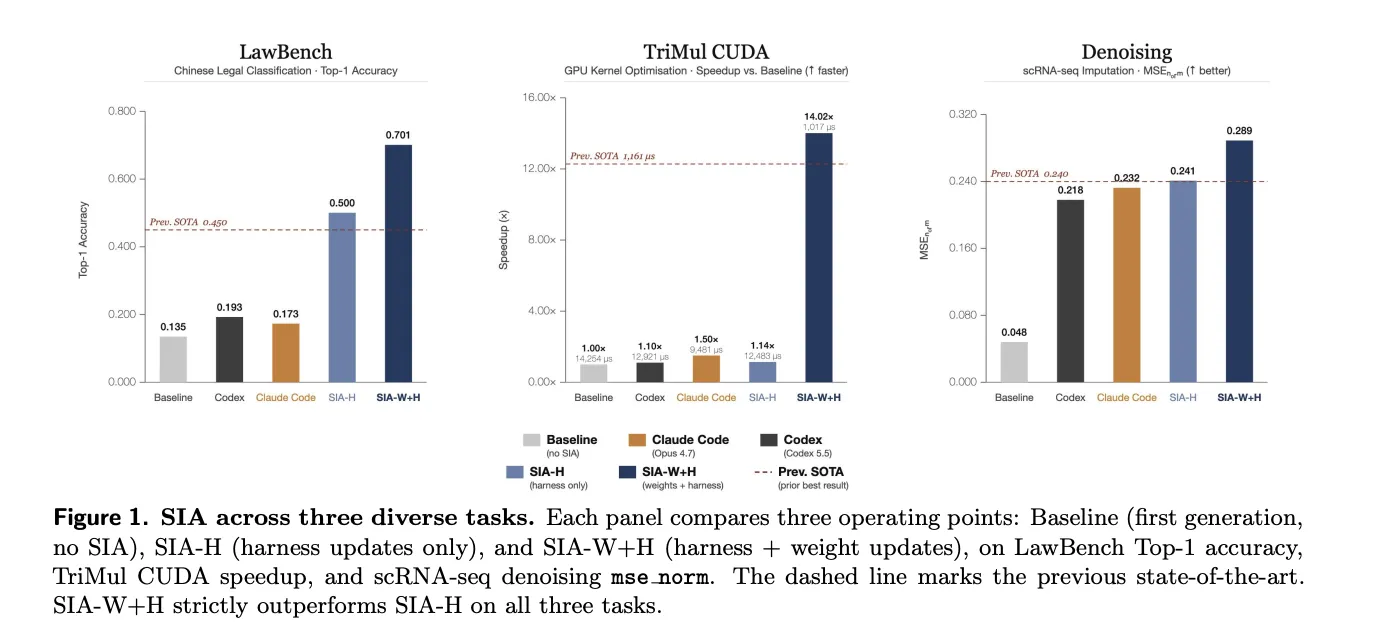
Hexo Labs released SIA (Self-Improving AI), an open-source framework that edits both the agent's scaffold and model weights simultaneously. SIA outperformed traditional methods in three domains, showcasing significant improvements in accuracy and speed.
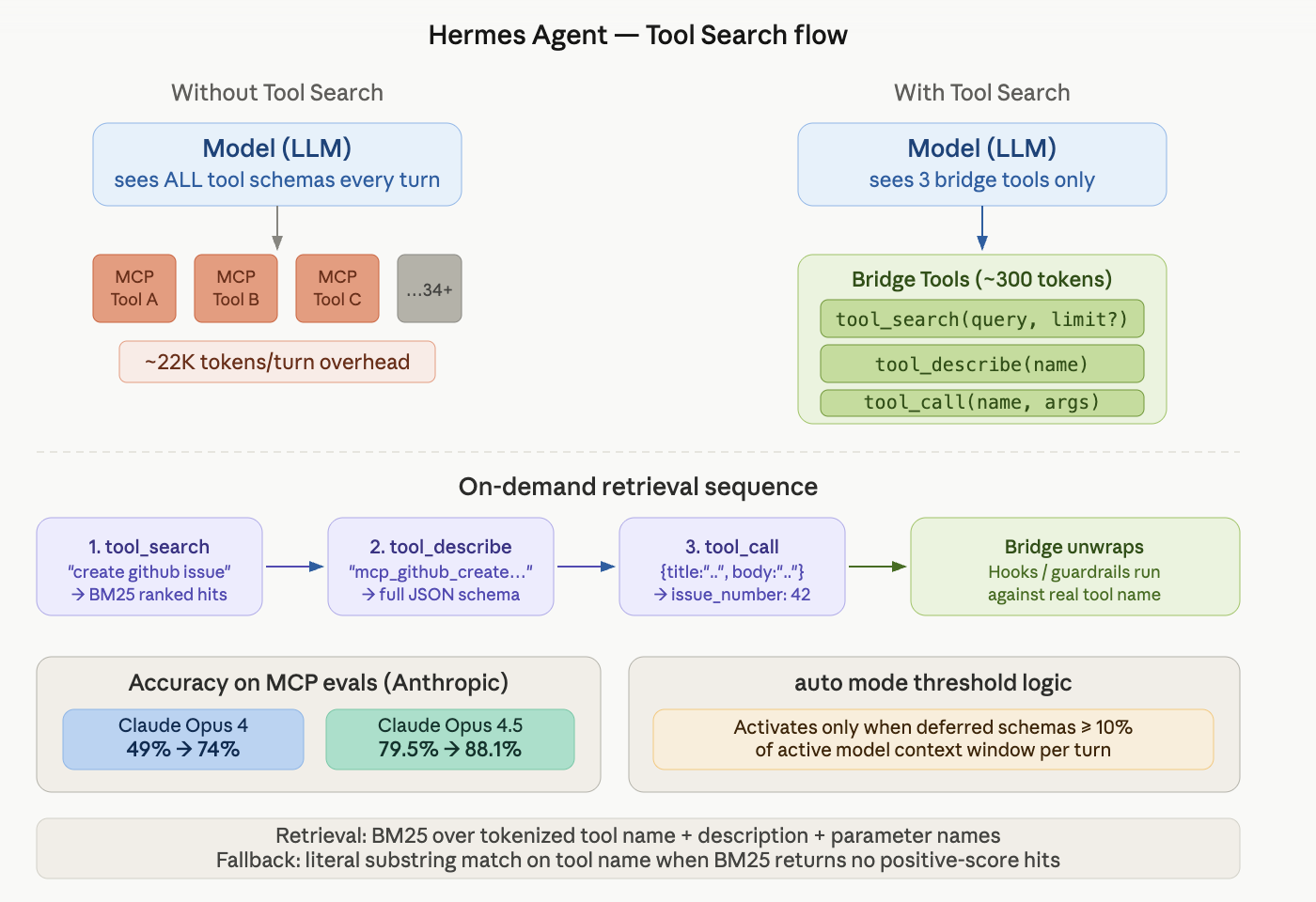
Nous Research's Hermes Agent introduces Tool Search to address AI agent system bottlenecks caused by excessive MCP tools. Tool Search optimizes tool loading, improving accuracy and reducing costs, with significant accuracy improvements shown in internal evaluations by Anthropic.
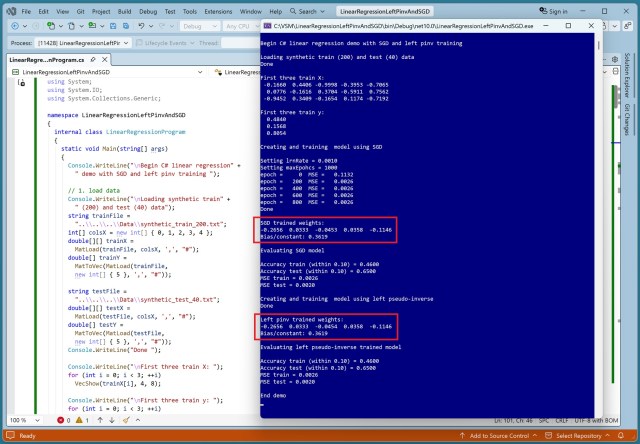
Linear regression predicts values using weights and bias. Techniques like SGD and L-BFGS vary in handling data complexities.
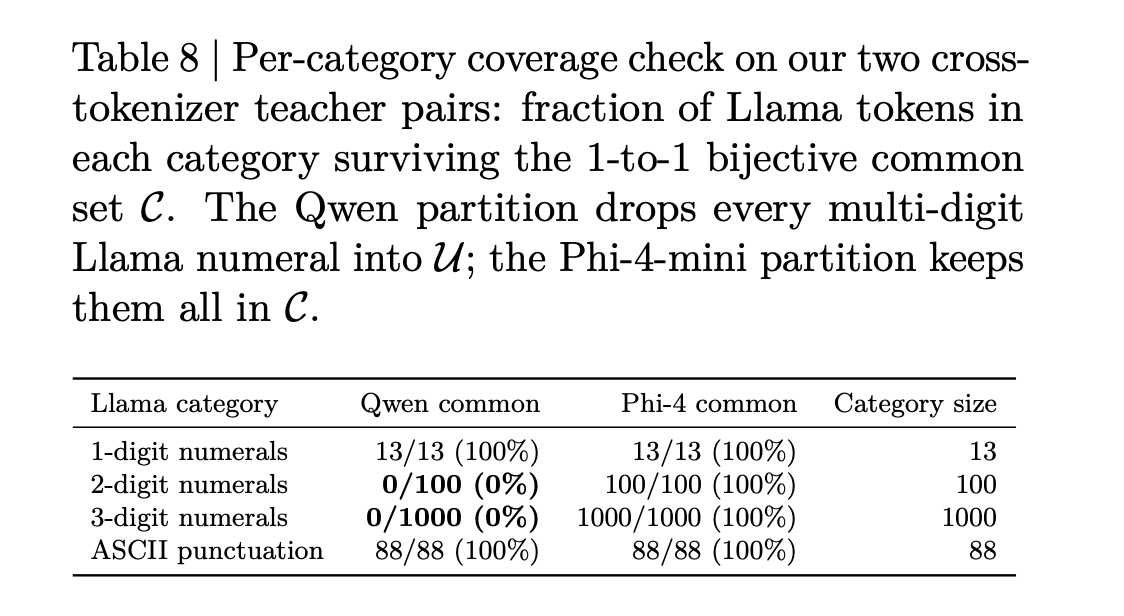
Knowledge distillation transfers "dark knowledge" from a large teacher model to a smaller student, overcoming vocabulary misalignment issues. NVIDIA's X-Token method addresses failures in current cross-tokenizer KD approaches, improving accuracy and alignment in distillation processes.
Machine learning models predict values like income from sex, age, state, and politics. Imputing missing data for predictions can lead to misleading results in machine learning.
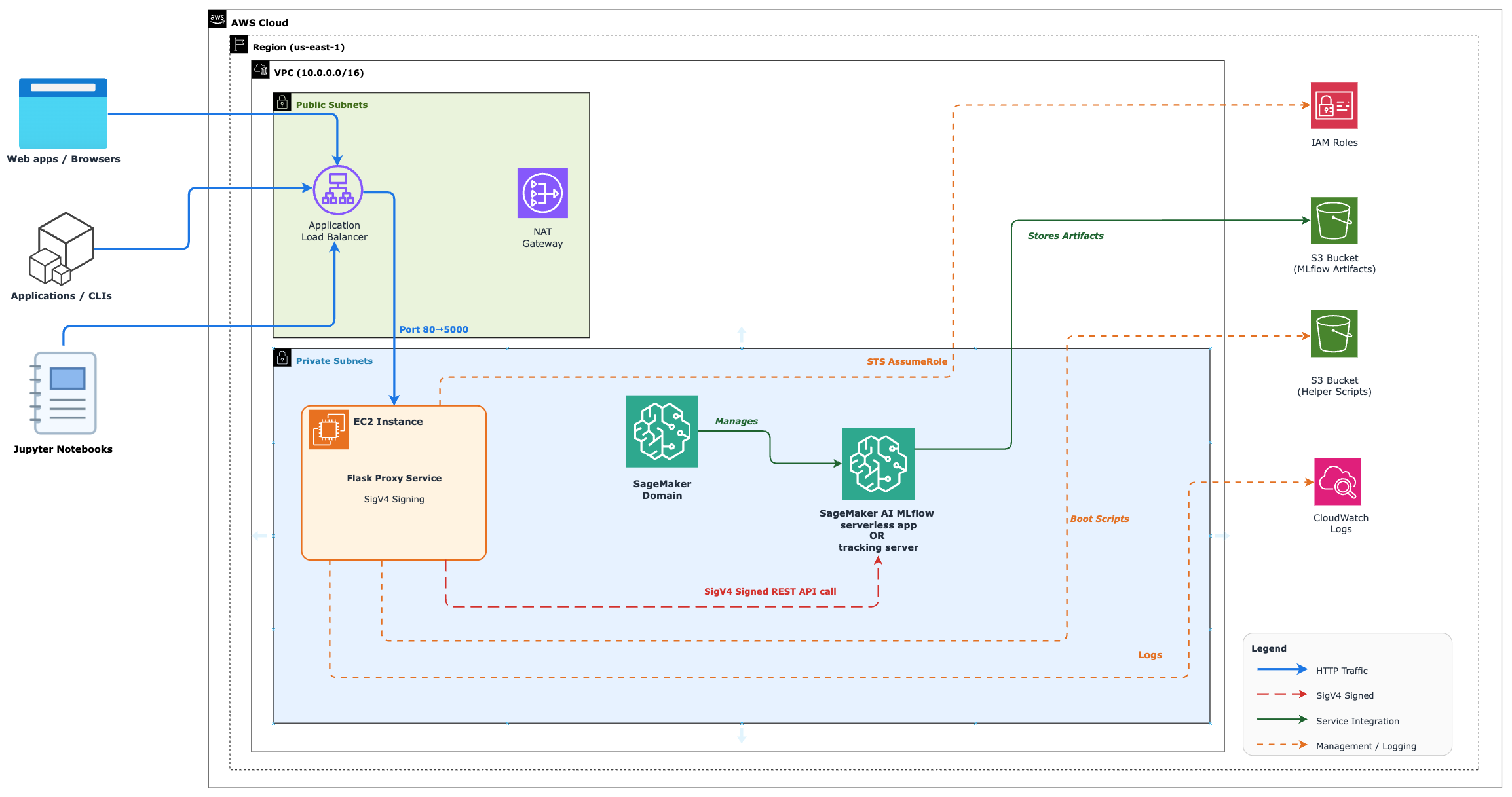
Amazon SageMaker MLflow offers comprehensive ML experiment tracking and model management capabilities. Enterprises can securely integrate MLflow with existing systems using a Flask-based proxy service, ensuring compliance and reducing complexity.

MIT and Massachusetts will establish the Quantum Systems Laboratory (QSL) to advance quantum research and innovation. The QSL will be a cutting-edge facility supporting transformative quantum technologies in various practical domains.
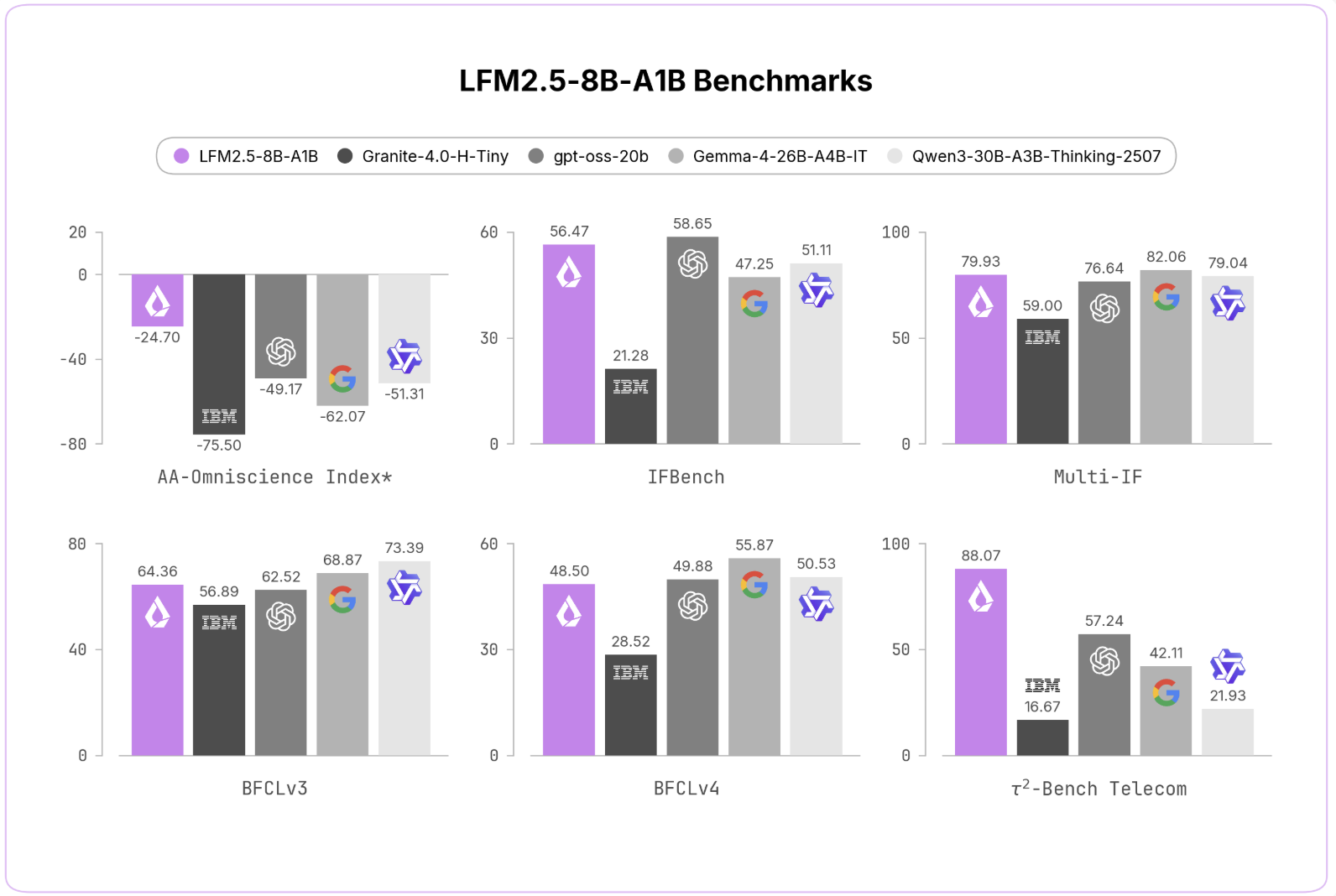
Liquid AI released LFM2. 5-8B-A1B, a sparse MoE model for tool calling. The reasoning-only model boasts improved performance across various benchmarks.

Robotics is evolving with NVIDIA Research showcasing simulation-to-real transfer for robots to adapt and operate reliably in dynamic environments. Innovations include multi-arm coordination with ScheduleStream and COMPASS policy framework for diverse robot embodiments, achieving significant improvements in success rates.