
Curiosity-driven research fuels AI advancements rooted in physics and chemistry. MIT leads in AI+MPS integration for future breakthroughs.
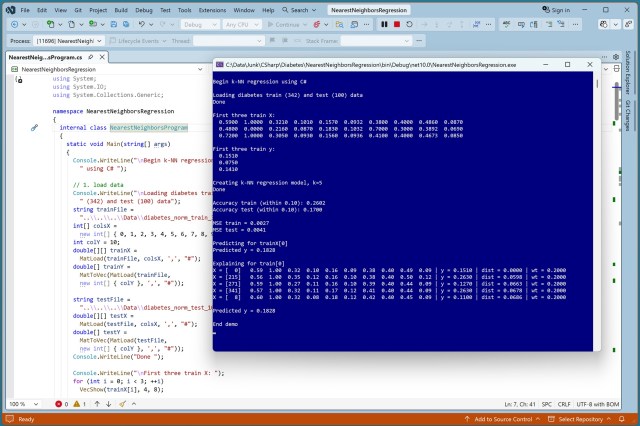
Nearest neighbors regression model applied to Diabetes Dataset for baseline comparison with advanced regression techniques. Simple yet interpretable C# implementation with detailed prediction explanations.

Malfunctioning car charger leads to frustration and deep contemplation during a long drive, highlighting the struggle of human spirit in the face of technology failures. The search for human assistance becomes a beacon of hope amidst the disappointment of modern conveniences.

MIT researchers developed an AI-driven system for long-term visual tasks, outperforming existing methods by 2x. The system combines vision-language models with formal planning for a 70% success rate, adaptable to new challenges.

AI accelerates without limits or safety measures, leading to a deadly collision in Bruce Holsinger's novel 'Culpability'. Peter Lewis, from Essential, delves into AI ethics on Per Capita's Burning Platforms podcast.
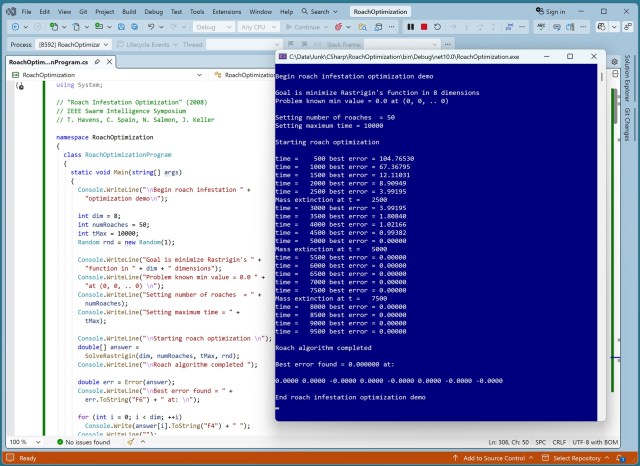
Summary: Roach Infestation Optimization (RIO) is a bio-inspired numerical optimization algorithm based on cockroach behavior. The demo program successfully minimizes the Rastrigin function in 8 dimensions, showcasing the algorithm's effectiveness.

Joseph Paradiso, a physicist turned tech innovator at MIT Media Lab, pioneers wearable sensing tech for diverse applications, from dance to sports medicine. Paradiso's groundbreaking work in sensor technology has paved the way for everyday devices tracking health and performance.

The Society of Authors launches scheme to identify human-authored books amidst AI flood at London Book Fair. Authors can register and display "Human Authored" logo on their books.

Elon Musk's xAI gets approval to double methane gas turbines at 'Colossus 2' in Mississippi, boosting power for AI supercomputers and Grok tool.

Historian Rutger Bregman urges consumers to boycott OpenAI's ChatGPT due to Pentagon deal. Bregman reveals ChatGPT's ties to Trump administration's authoritarian infrastructure.

Cells in cancerous tumors evolve and adapt like Darwin's finches. Matthew G. Jones at MIT uses AI to decode tumor evolution, focusing on extrachromosomal DNA amplifications.

AI is transforming education, raising concerns for the future of humanities. Stanford professor Lea Pao aims to engage students offline to prevent reliance on AI.

AI success hinges on understanding it as a skill, not a shortcut. Training reveals a professional divide: reliance vs avoidance.

Teen's violent plans shared with ChatGPT lead to tragic mass shooting in Canada. OpenAI faces lawsuit for failure to prevent attack.
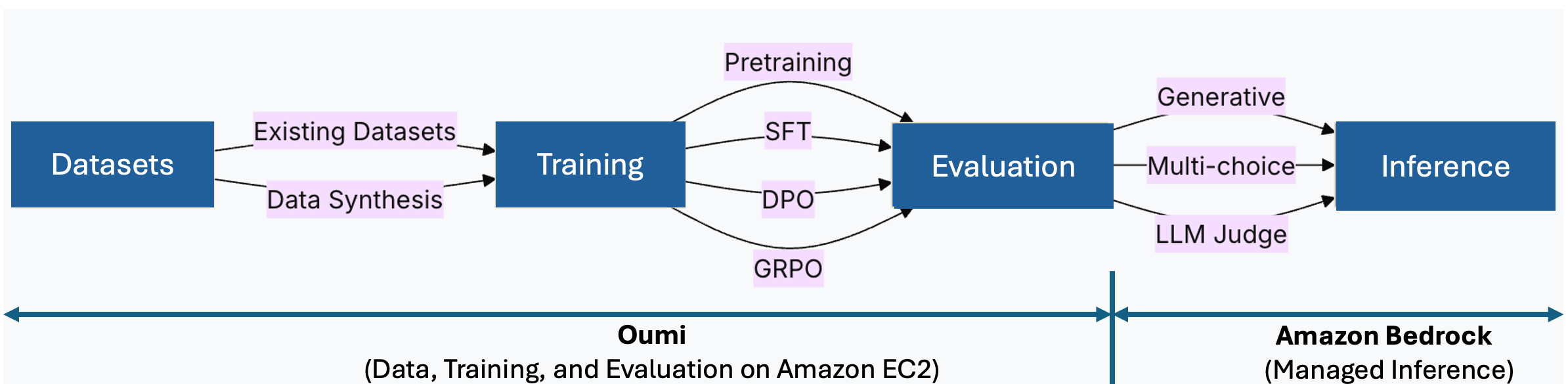
Oumi simplifies LLM fine-tuning on Amazon EC2, integrating data synthesis, training, and evaluation. Amazon Bedrock streamlines managed inference post-fine-tuning, eliminating the need for manual infrastructure management.