Article: 'Support Vector Regression with SGD Training Using C#' in Microsoft Visual Studio Magazine explores kernel SVR demo with SSGD training. SVR predicts using RBF kernel function, removing irrelevant data during training to improve accuracy and scalability.

GeForce NOW expands with new RTX 5080 server in Toronto, enhancing cloud gaming performance. NTE: Neverness to Everness update introduces new gameplay, characters, outfits, and a revolutionary motorcycle vehicle.
MCP tools underperform due to poor design, causing bloat and confusion in LLMs. Practical context engineering is key to improving tool behavior and balancing bloat and confusion.
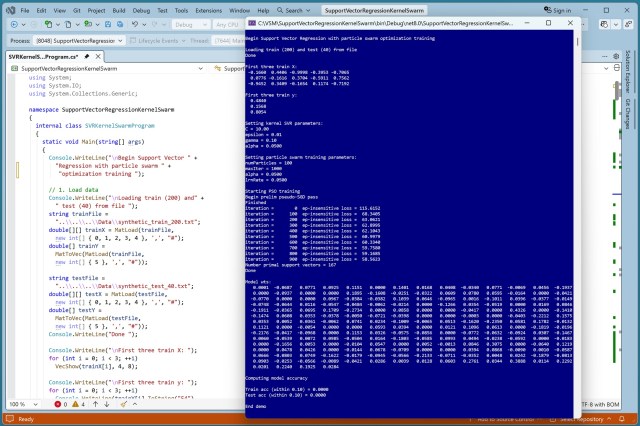
Failed attempt at training an SVR model using PSO yielded only 35% accuracy, compared to 95% using standard techniques. PSO's theoretical promise falls short in practical SVR training applications.
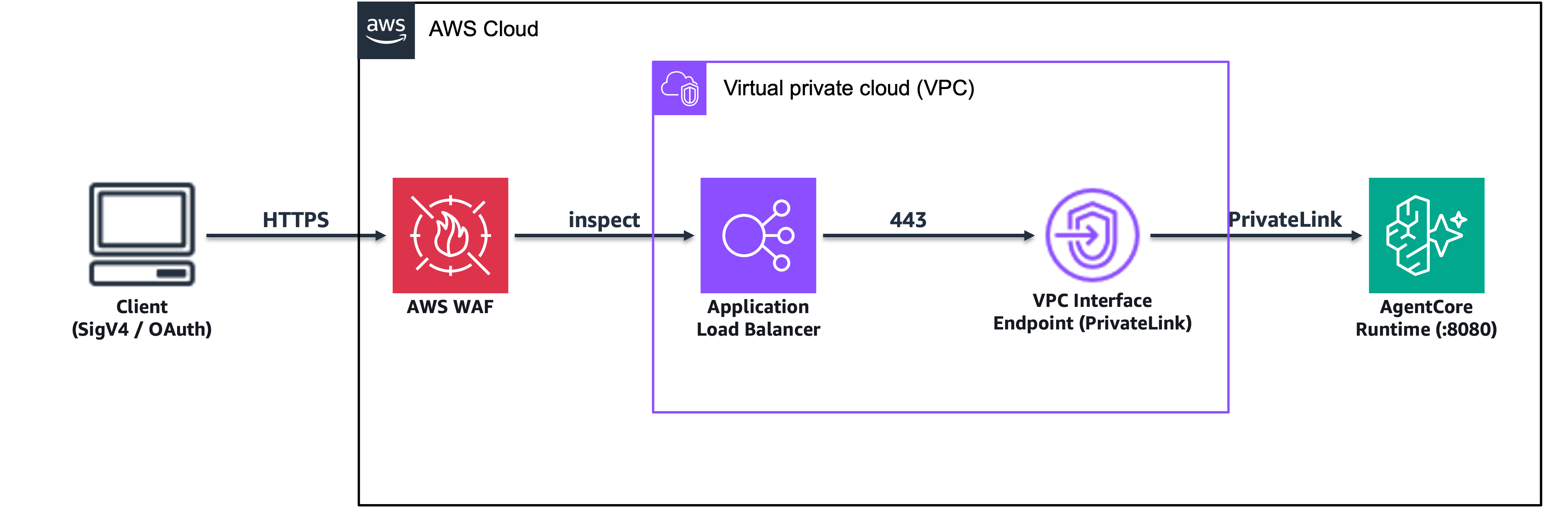
Deploy generative AI agents with Amazon Bedrock AgentCore as production API endpoints, integrating AWS WAF and ALB for secure traffic routing. Two architecture patterns address the challenge of authenticating health checks while passing production traffic to AgentCore.
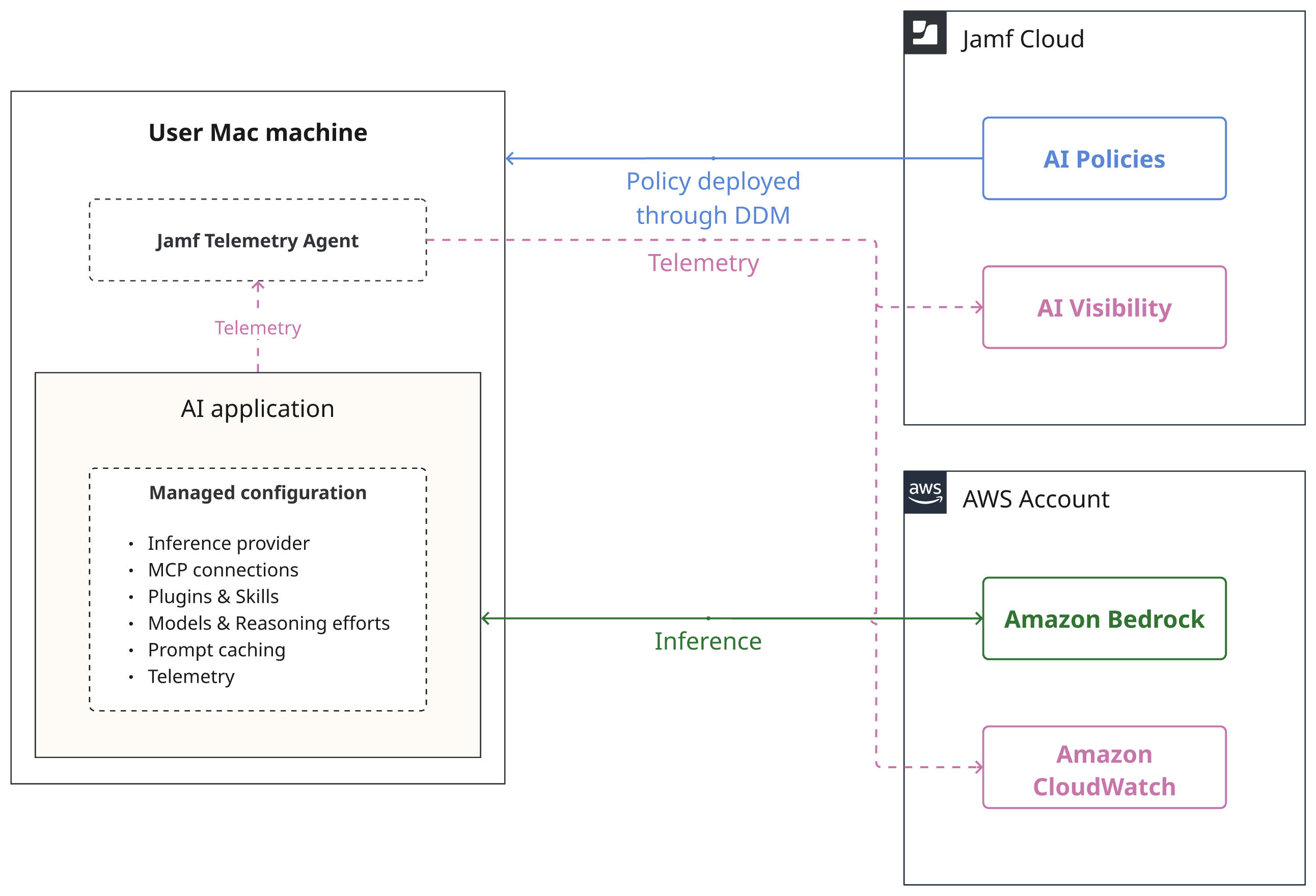
Jamf's AI Governance simplifies managing AI applications like Claude Code on Mac devices with Amazon Bedrock support, ensuring secure and efficient deployment. Users can easily access approved applications without manual setup, enhancing productivity and governance across the organization.
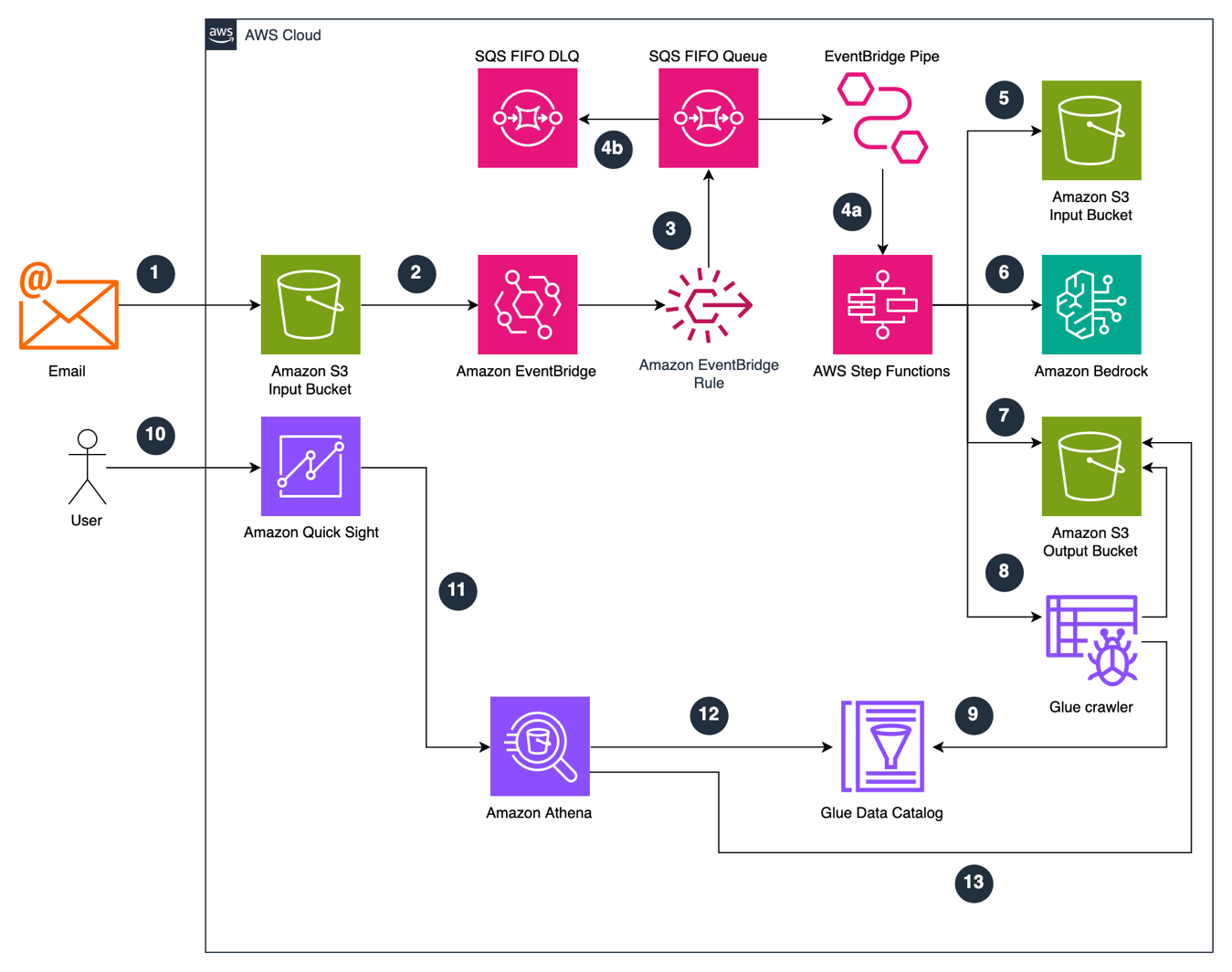
AI-powered email management automates email routing and prioritization for faster response times in the public sector. Amazon Bedrock solution categorizes and prioritizes emails, reducing manual workload and improving efficiency.
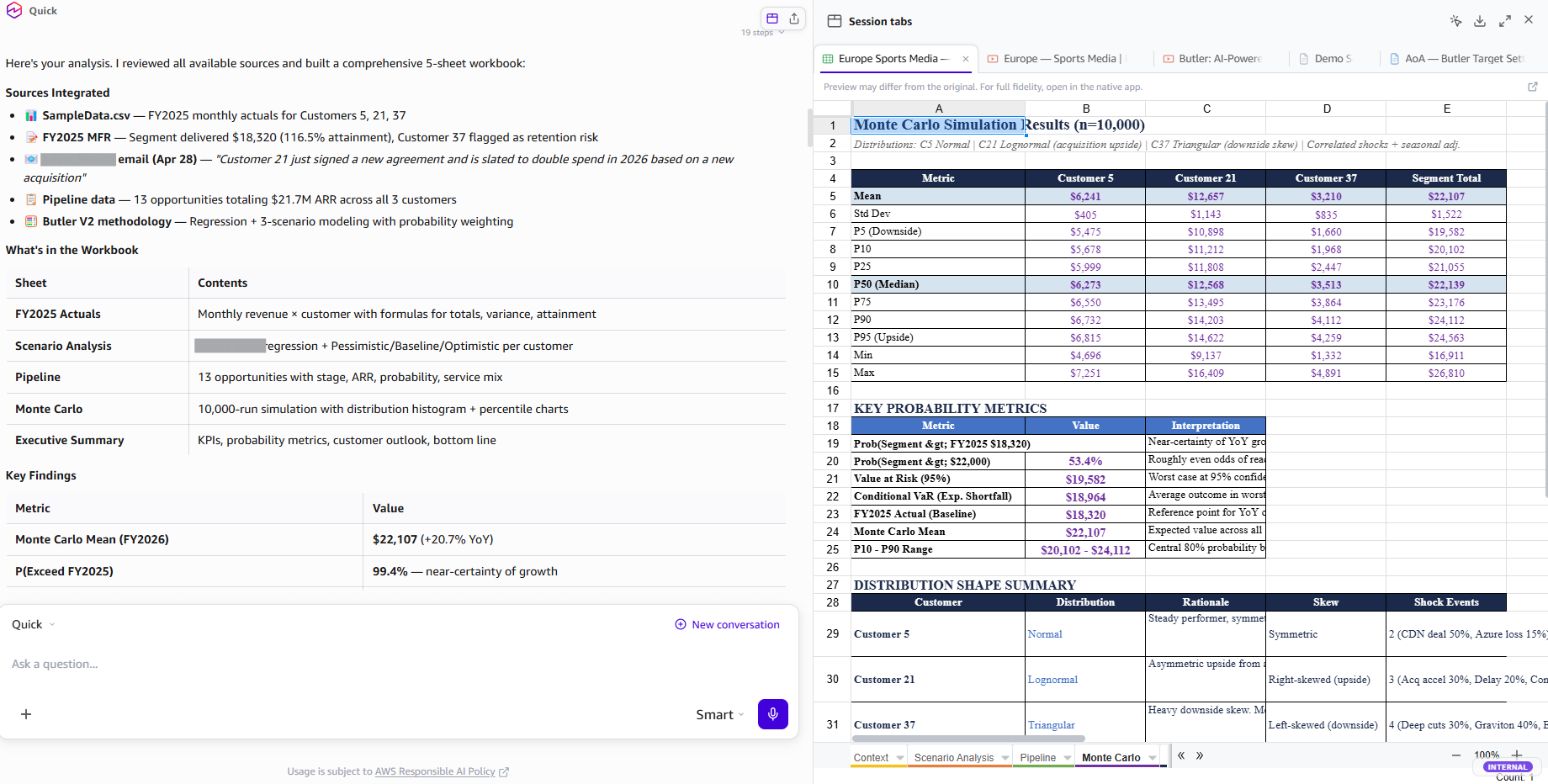
Amazon Quick, a generative AI assistant, transformed AWS Finance's time-consuming data preparation tasks, enabling teams to focus on analysis and strategy. Quick's chat agents and Flows streamlined scenario modeling and risk analysis, allowing the team to cover their entire customer portfolio with greater depth in just 10 minutes per customer.

AI costs dropping rapidly: GPT-4-class capabilities go from $30 to under $1 per million tokens. Near-free intelligence era approaching.

AI chatbots like ChatGPT and Claude are now used for tasks like coding and app development. U.S. Air Force cadet Joshua Lynch created a military application using AI chatbots without prior coding experience.
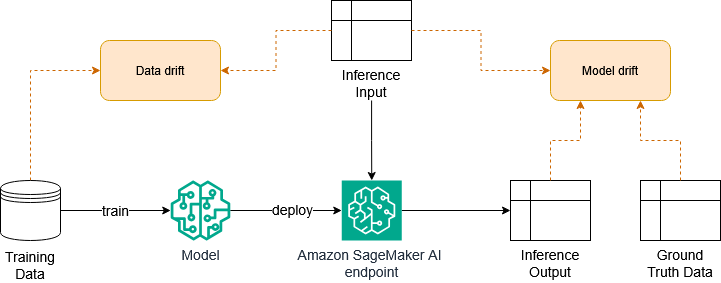
Machine learning models' accuracy decreases post-training due to factors like data drift and model drift. Monitoring models in production can prevent accuracy issues. SageMaker AI and Evidently Python library can help track data and model drift for effective model monitoring.

Amazon Quick Sight's Multi-Dataset Topics allow analytics teams to bring multiple datasets into a single Topic using AI-generated SQL, enabling complex queries without pre-defined relationships. The post provides best practices, examples, and techniques for handling various data patterns, offering a decision framework for choosing between defined relationships and semantic-only guidance.

Jesse Thaler named director of MIT Laboratory for Nuclear Science, bringing AI and machine learning to fundamental physics research. Thaler's leadership at IAIFI and focus on AI-driven discovery set to propel LNS into new era of scientific breakthroughs.
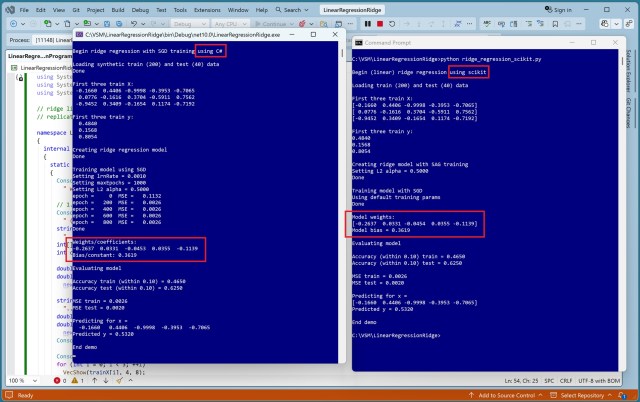
Ridge regression uses L2 regularization to prevent overfitting by penalizing squared model weights. Implementation details differ between scikit-learn and C# demos, despite producing identical results.
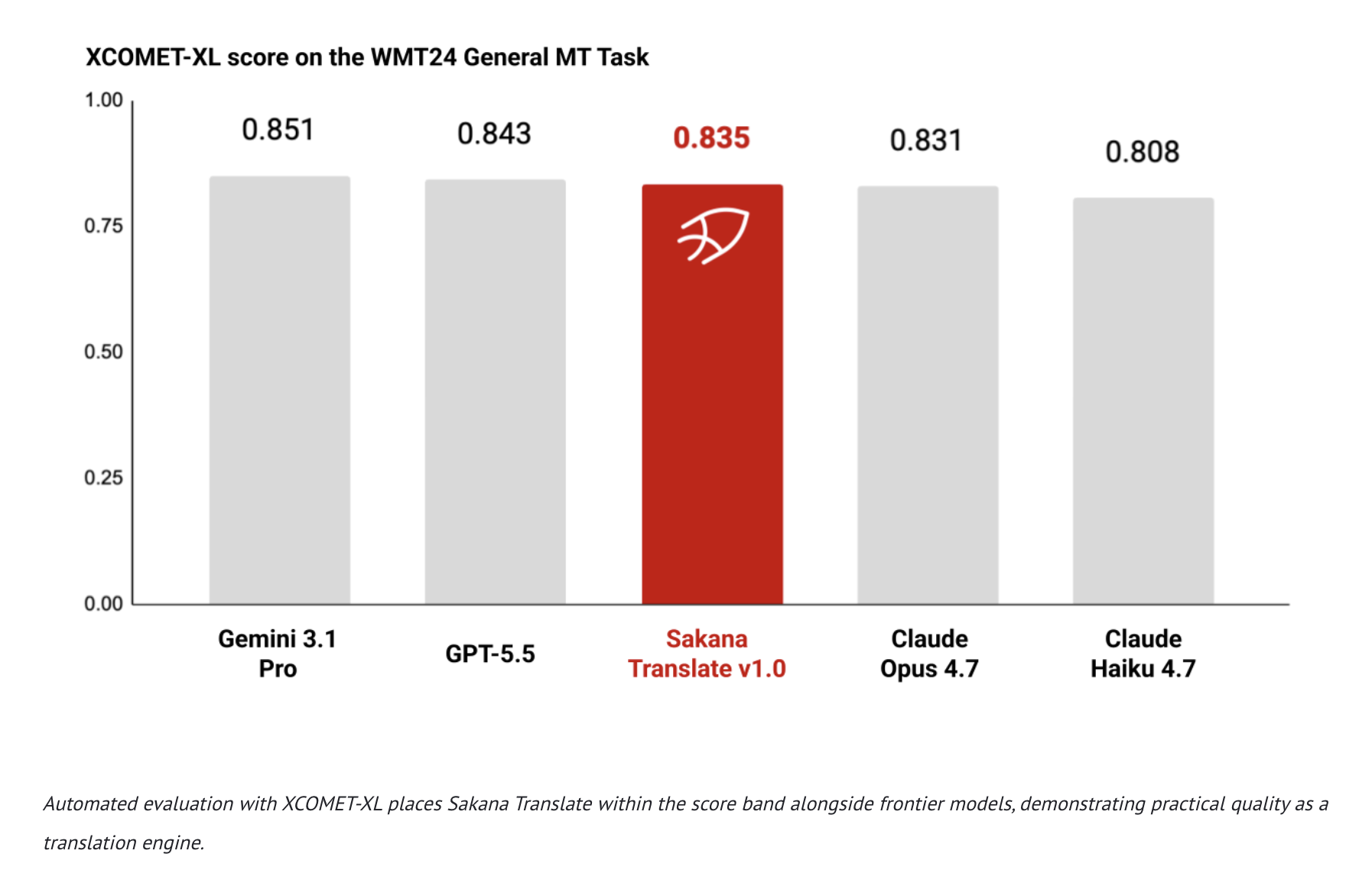
Sakana AI introduces Sakana Translate, powered by Namazu, for seamless bidirectional translation in Japanese, English, and Chinese. The tool aims to bridge cultural and linguistic gaps often missed by general translation services.