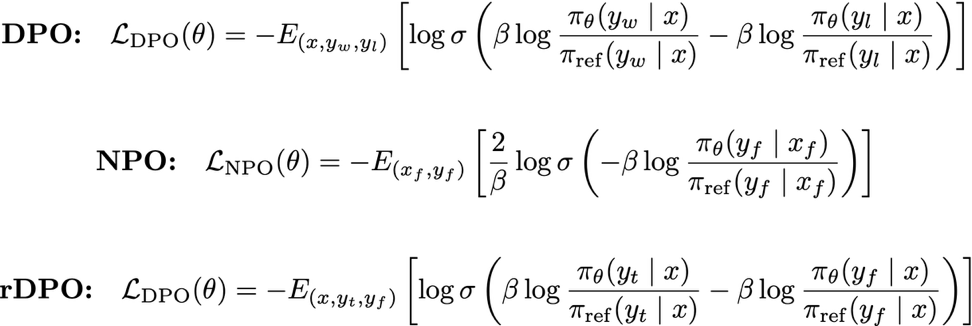
Organizations face challenges with model safeguards deflecting necessary content. Amazon Nova's rDPO technique reduces over-deflection while maintaining model quality, allowing for customizable content moderation settings.
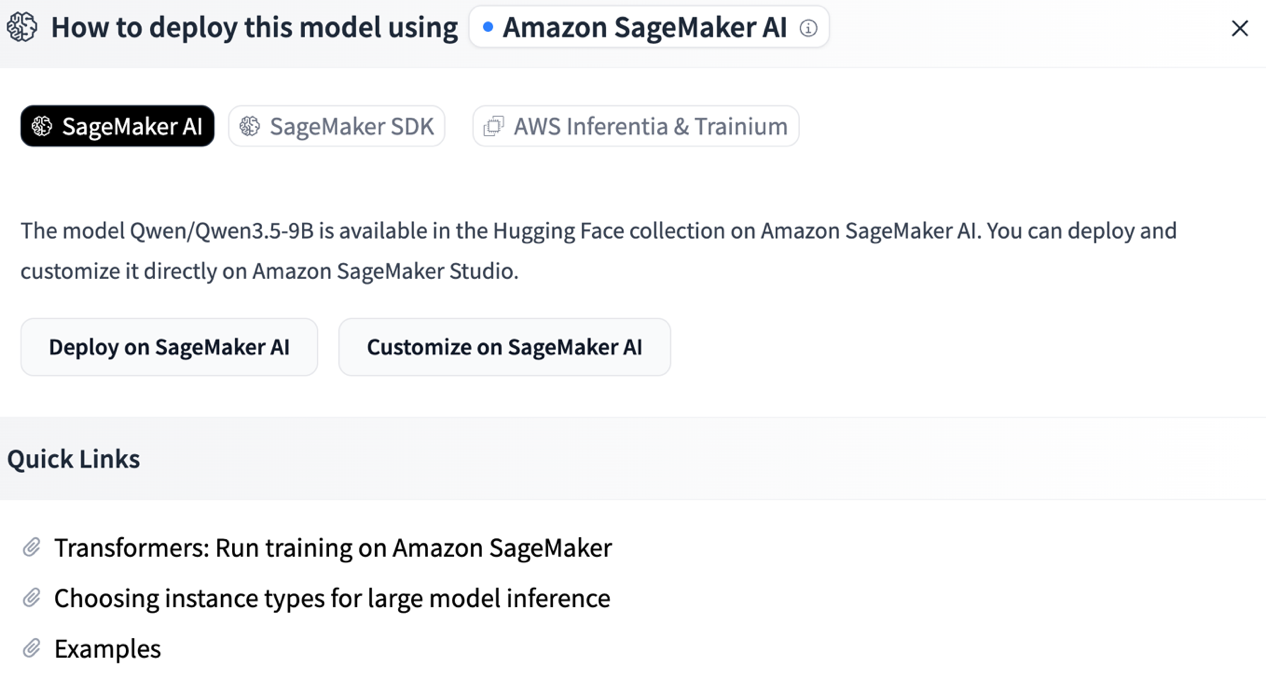
Hugging Face and Amazon SageMaker AI now offer a seamless one-click integration, streamlining model discovery to deployment process. Developers can easily fine-tune and deploy models in SageMaker Studio without the hassle of manual configurations, thanks to the deep-link integration.
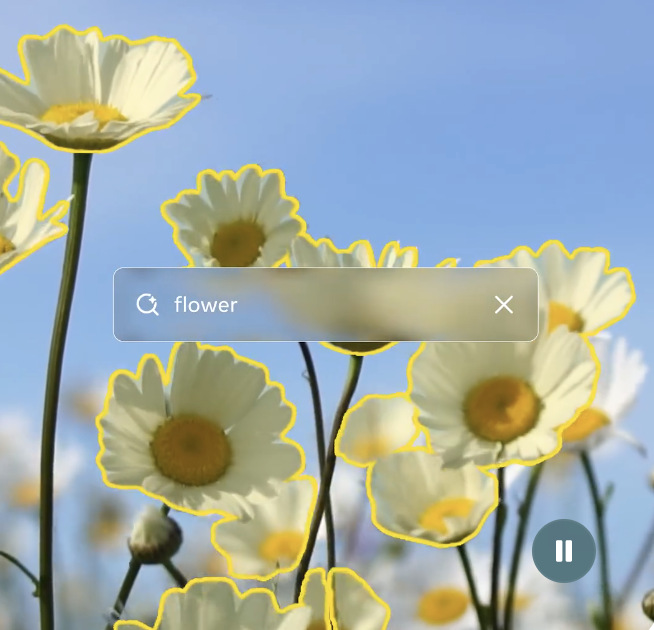
Sharing data containing PII poses legal risks. Amazon Nova coordinates tools for precise PII redaction in images.
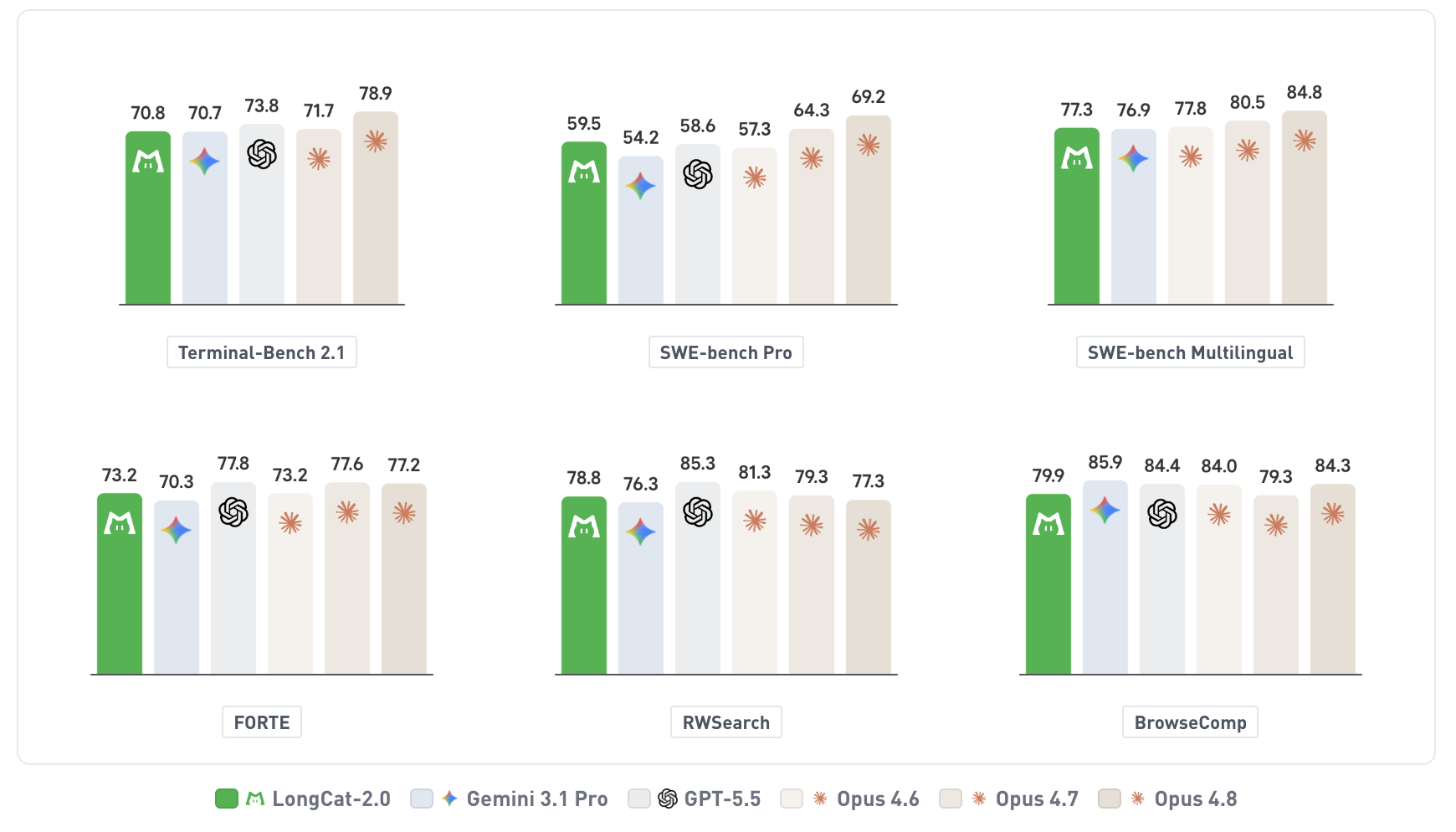
Meituan unveils LongCat-2.0, a trillion-parameter MoE language model for agentic coding. Featuring a 1-million-token context window and running on domestic AI ASIC superpods, it promises efficient coding with stability and cost reduction.
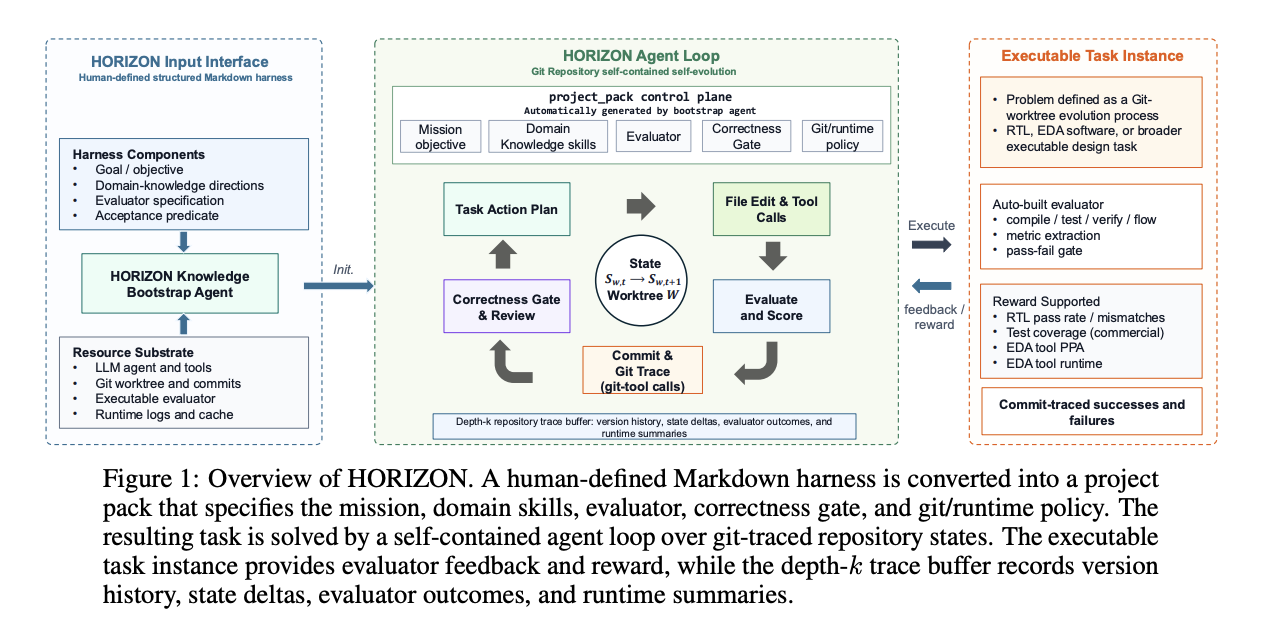
NVIDIA Research unveils HORIZON, a hands-free agent framework for hardware design. It uses a structured Markdown harness and git worktrees to achieve 100% completion across RTL benchmarks.
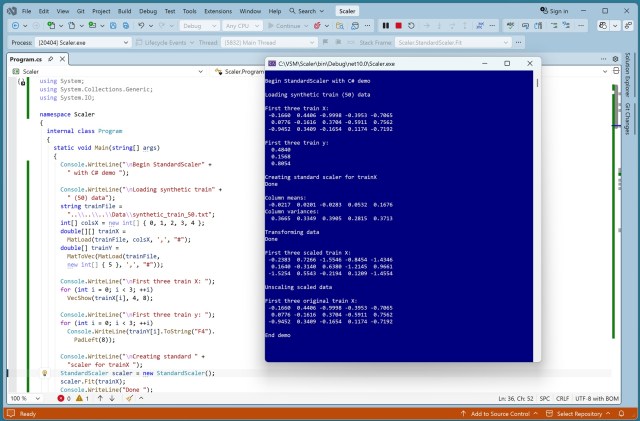
Rarely using L2 and never using L1 regularization for linear regression, a C# StandardScaler was implemented for equal weight treatment. The StandardScaler demo showcased data transformation for uniform model weight reduction.
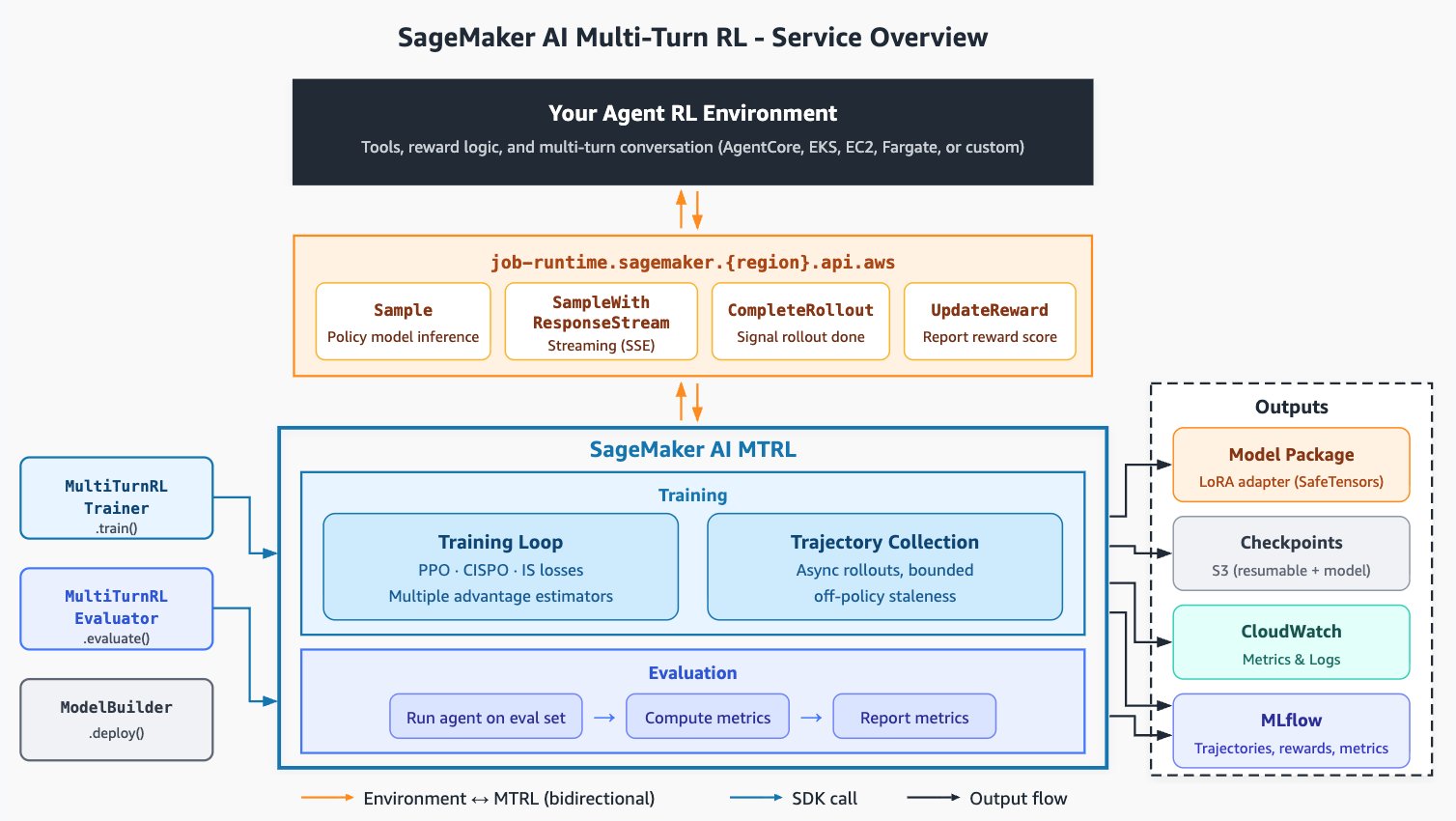
Amazon SageMaker AI offers multi-turn reinforcement learning for complex tasks like resolving support tickets. The platform provides modular interfaces, custom rewards, and serverless execution for efficient training and deployment.
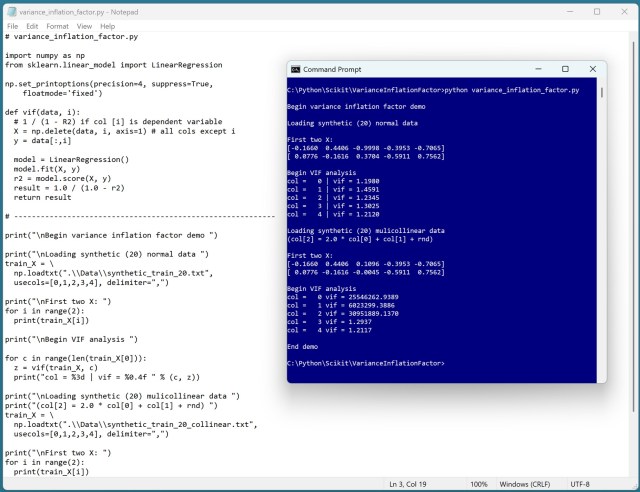
Multicollinearity can impact machine learning models. VIF analysis can reveal correlations in training data columns.
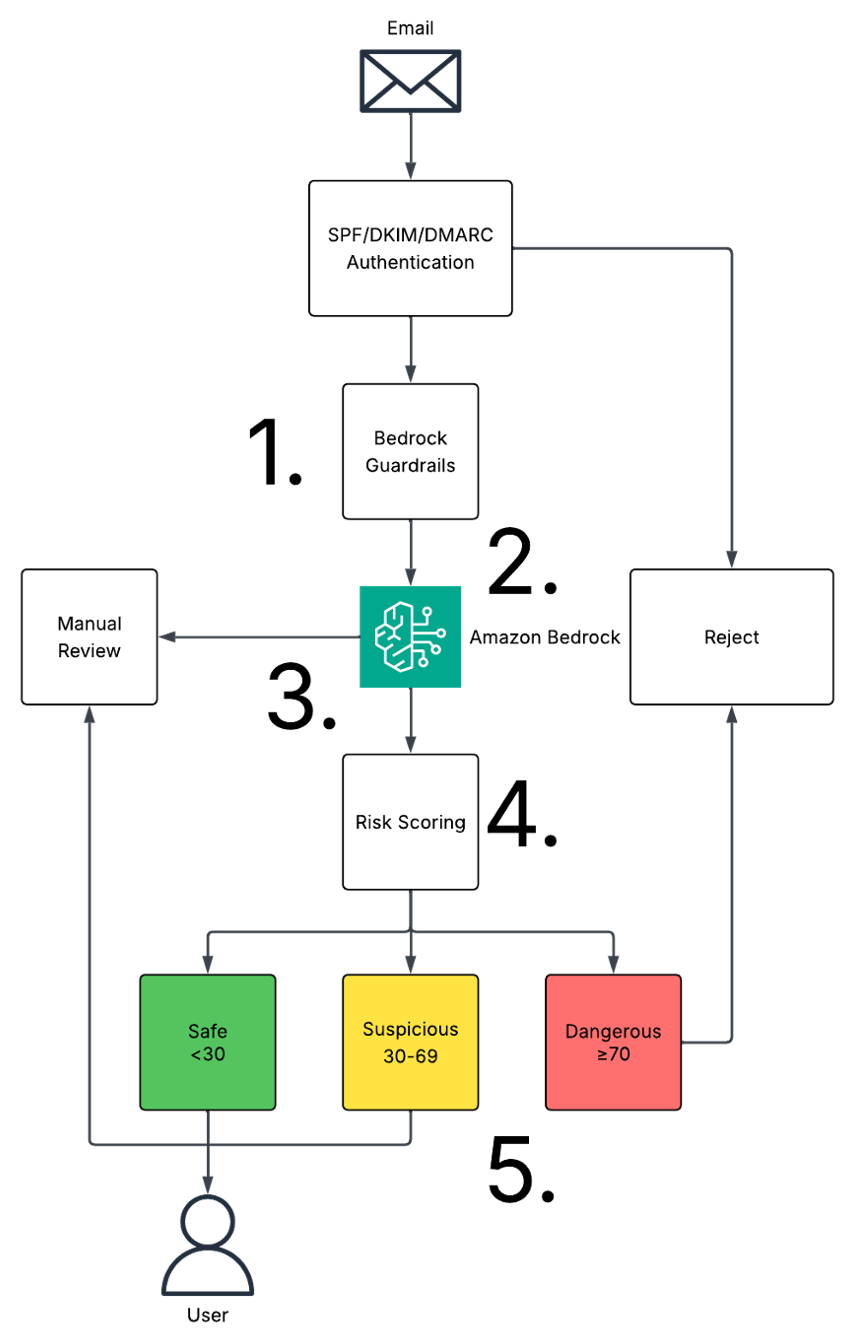
AI-generated phishing emails are now more sophisticated, posing a new challenge for security teams. Amazon Bedrock uses AI to detect phishing attempts based on behavioral patterns, not grammar.

President Sally Kornbluth warns of innovation pipeline drying up without federal support for curiosity-driven research. She emphasizes the importance of teaching foundational skills for leading in an AI-enabled world.
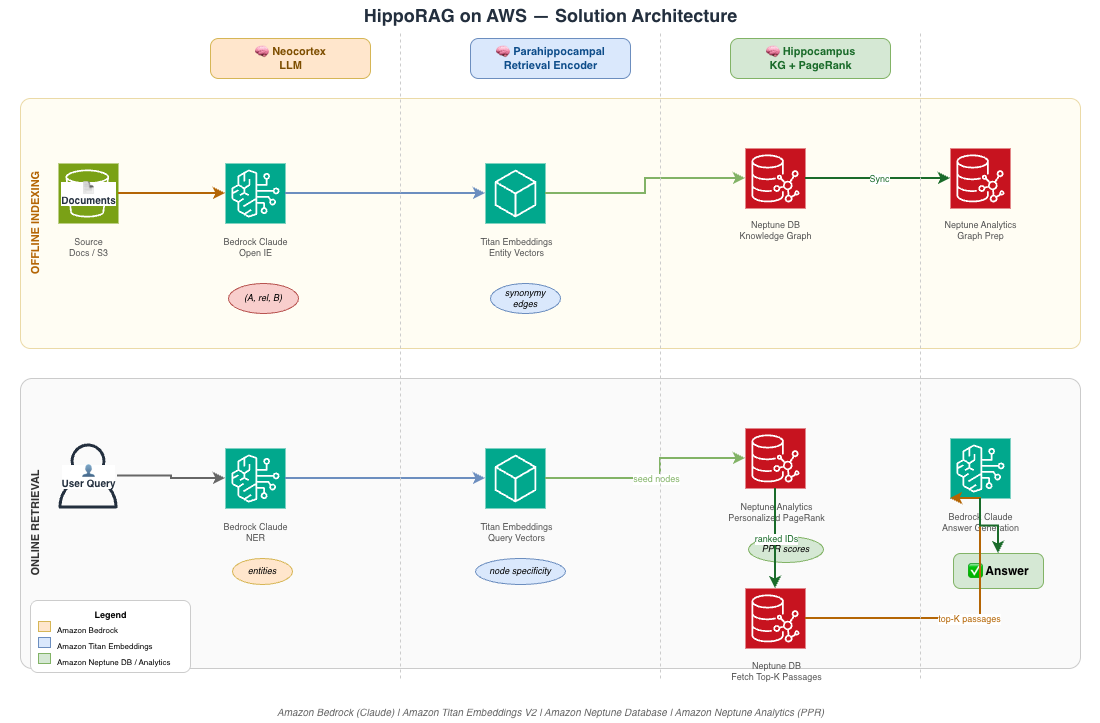
HippoRAG improves multi-hop reasoning by integrating knowledge across sources with a neurobiologically-inspired framework. AWS implementation includes Amazon Bedrock, Neptune, Neptune Analytics, and Titan Embeddings for enterprise-scale applications.

Amazon Bedrock AgentCore Memory is a managed memory service that improves AI agents' ability to recall information accurately. Metadata filtering enhances retrieval precision, boosting overall question-answering accuracy from 40% to 64%, with significant gains in contextual questions.
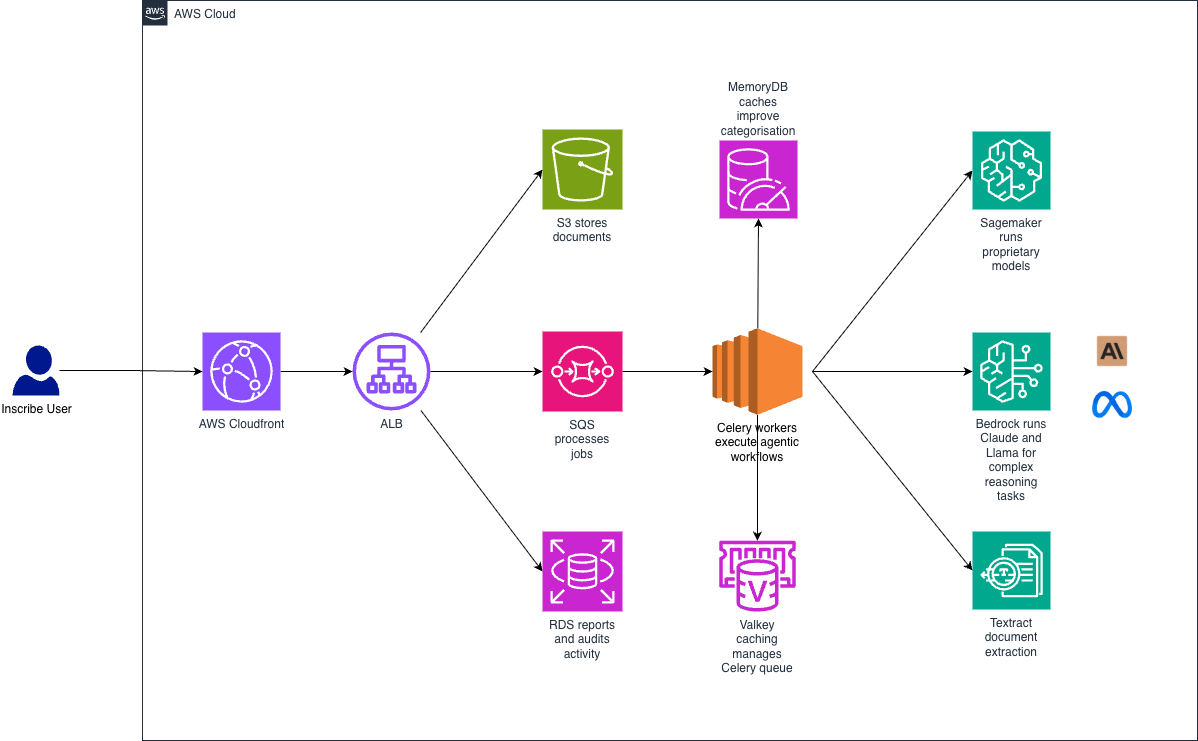
Fraud rates are rising, with AI-generated forgeries growing 5x. Inscribe's agentic AI system detects financial document fraud in under 90 seconds.
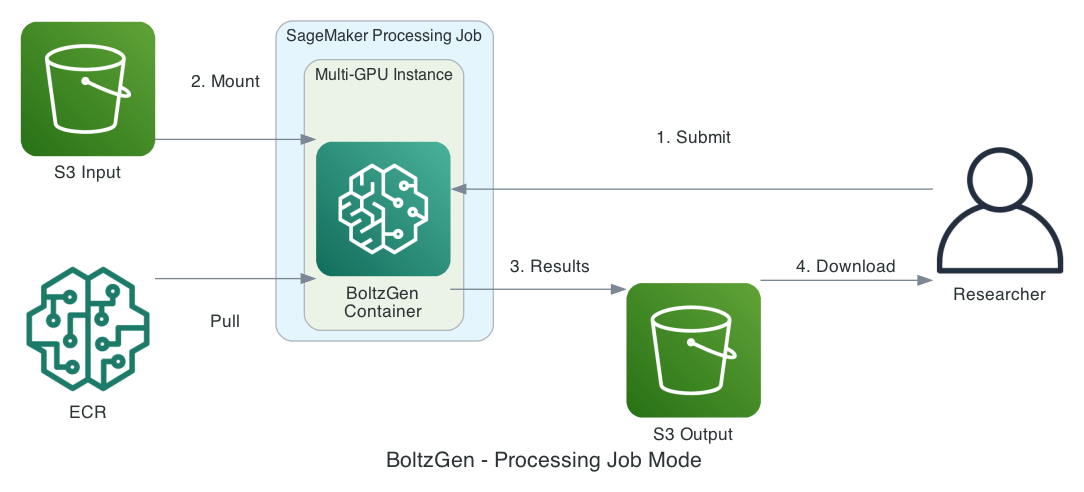
BoltzGen on Amazon SageMaker AI streamlines protein binder design, managing GPU infrastructure. SageMaker AI handles compute lifecycle, reducing operational overhead for design iteration.
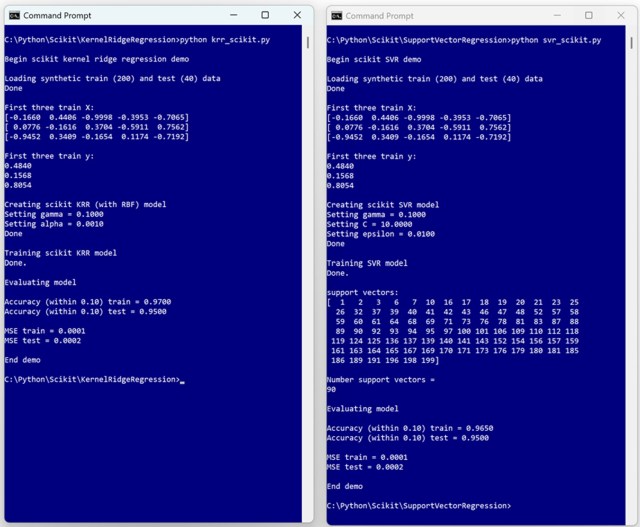
Kernel ridge regression (KRR) and support vector regression (SVR) yield similar results, with KRR being simpler and more efficient than SVR due to fewer hyperparameters. While KRR stores all training items, SVR only stores a subset, making it slightly faster in predictions.