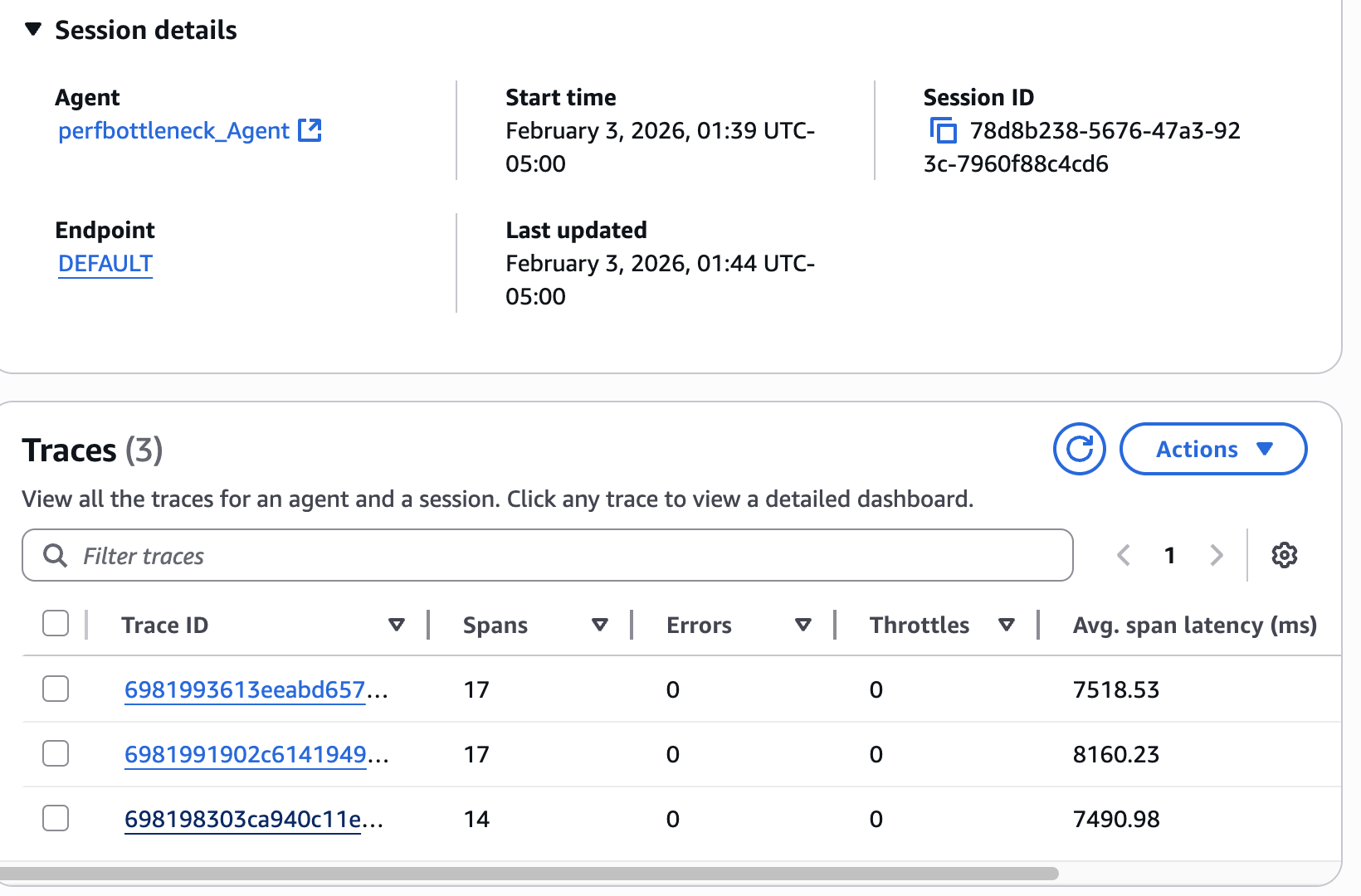
Агенты искусственного интеллекта, переходящие на производственную стадию, сталкиваются с новыми проблемами, связанными со скоростью и эффективностью. Узнайте, как Amazon Bedrock AgentCore помогает выявлять и устранять узкие места в производительности и проблемы с памятью в длительных сеансах.

Организации интегрируют аналитику на основе искусственного интеллекта с ответами, основанными на обработке естественного языка (Text2SQL), подчеркивая важность семантической информации, поступающей из каталогов данных в продукты искусственного интеллекта, такие как Amazon Quick. Задача заключается в преодолении разрыва между богатыми метаданными и предоставлением пользователям тщательно отобран...

Сервис GeForce NOW превращает обычные ноутбуки в мощные игровые системы, позволяя легко переключаться между учебой и играми. Добавление игры Halo: Campaign Evolved в библиотеку сервиса предлагает увлекательный игровой опыт для пользователей, демонстрируя универсальность и удобство платформы.

Студенты и постдоки Массачусетского технологического института выступают за федеральное финансирование научных исследований в Вашингтоне. Они проводят встречи с представителями 62 конгрессменов, чтобы обсудить вопросы научной политики. Эта программа, организованная совместно Одри Паркер и Иэном Робертсоном, помогает ученым участвовать в процессе формирования государственной политики.
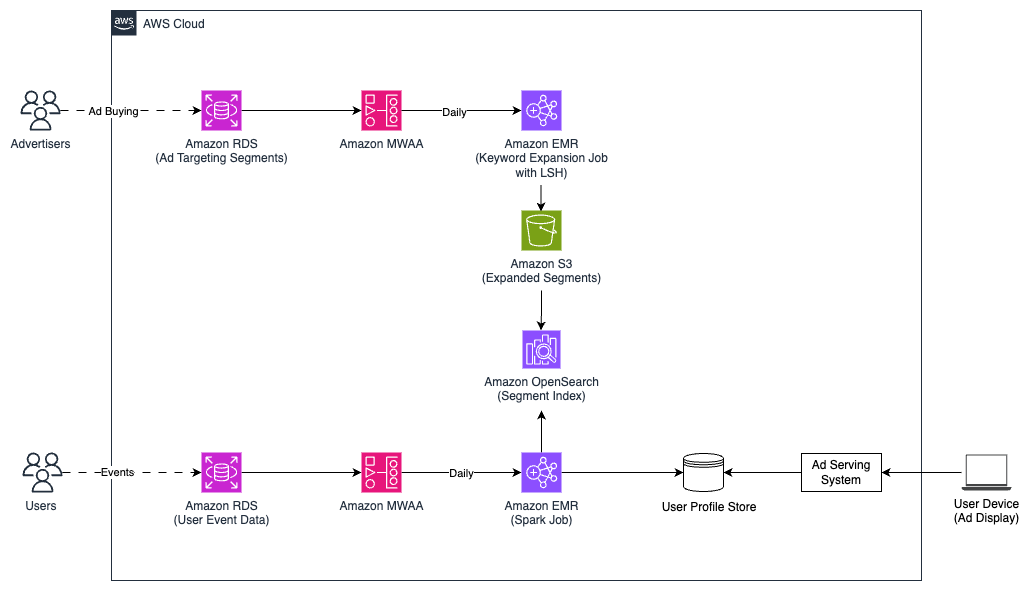
Платформа управления рекламными кампаниями (Demand-Side Platform, DSP) компании Yahoo, работающая по принципу омниканальности, решает задачи в сфере цифровой рекламы благодаря передовым технологиям и продвинутым возможностям таргетинга аудитории. Внедрение Amazon Bedrock позволяет компании Yahoo улучшить возможности ретаргетинга (Search Retargeting, SRT), позволяя охватывать пользователей на ос...

Даниэла Рус из Массачусетского технологического института получила премию High-Tech Prize 2026 за новаторские работы в области робототехники и искусственного интеллекта, с акцентом на самоорганизующихся робототехнических системах и роботах нового поколения. Ее исследования в CSAIL определяют будущее физического искусственного интеллекта, находя применение в самых разных областях, от здравоохран...

Amazon Bedrock представляет технологию расширенной оптимизации запросов, которая упрощает процесс переноса и оптимизации запросов для приложений генеративного искусственного интеллекта. Этот инструмент автоматизирует рутинные задачи, позволяет сравнивать производительность различных моделей и устраняет узкие места в жизненном цикле разработки программного обеспечения.
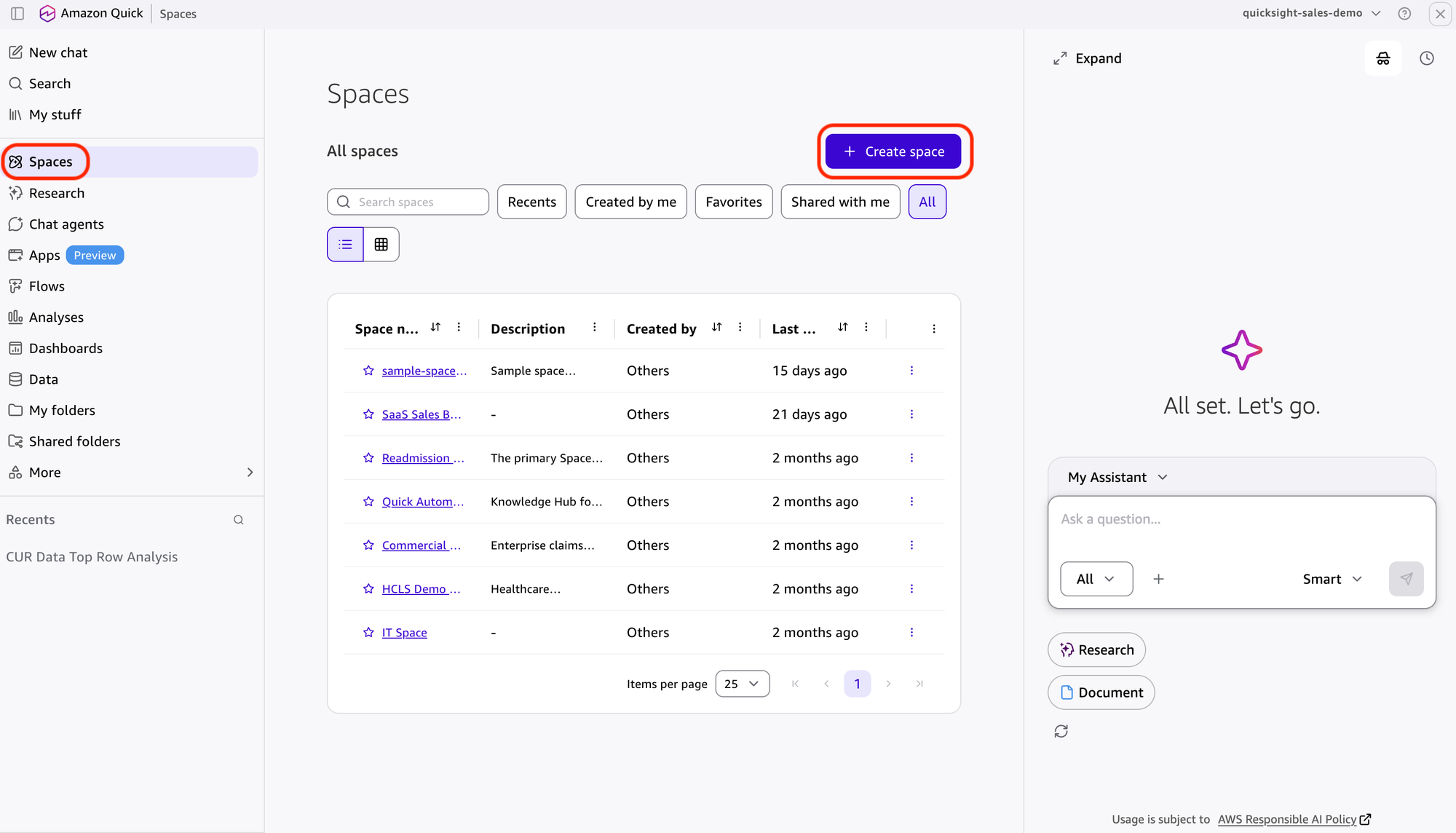
Автоматизация удержания клиентов в Amazon Quick сокращает время ответа с нескольких дней до нескольких минут. Эта система анализирует настроения клиентов, определяет приоритеты для удержания и эффективно генерирует персонализированные предложения.

PhysioNet, основанная в 1999 году, совершила революцию в медицинских исследованиях, внедрив глобальный обмен сложными физиологическими данными. На сегодняшний день платформа содержит сотни баз данных, которые были упомянуты более чем в 15 000 публикациях за прошлый год.
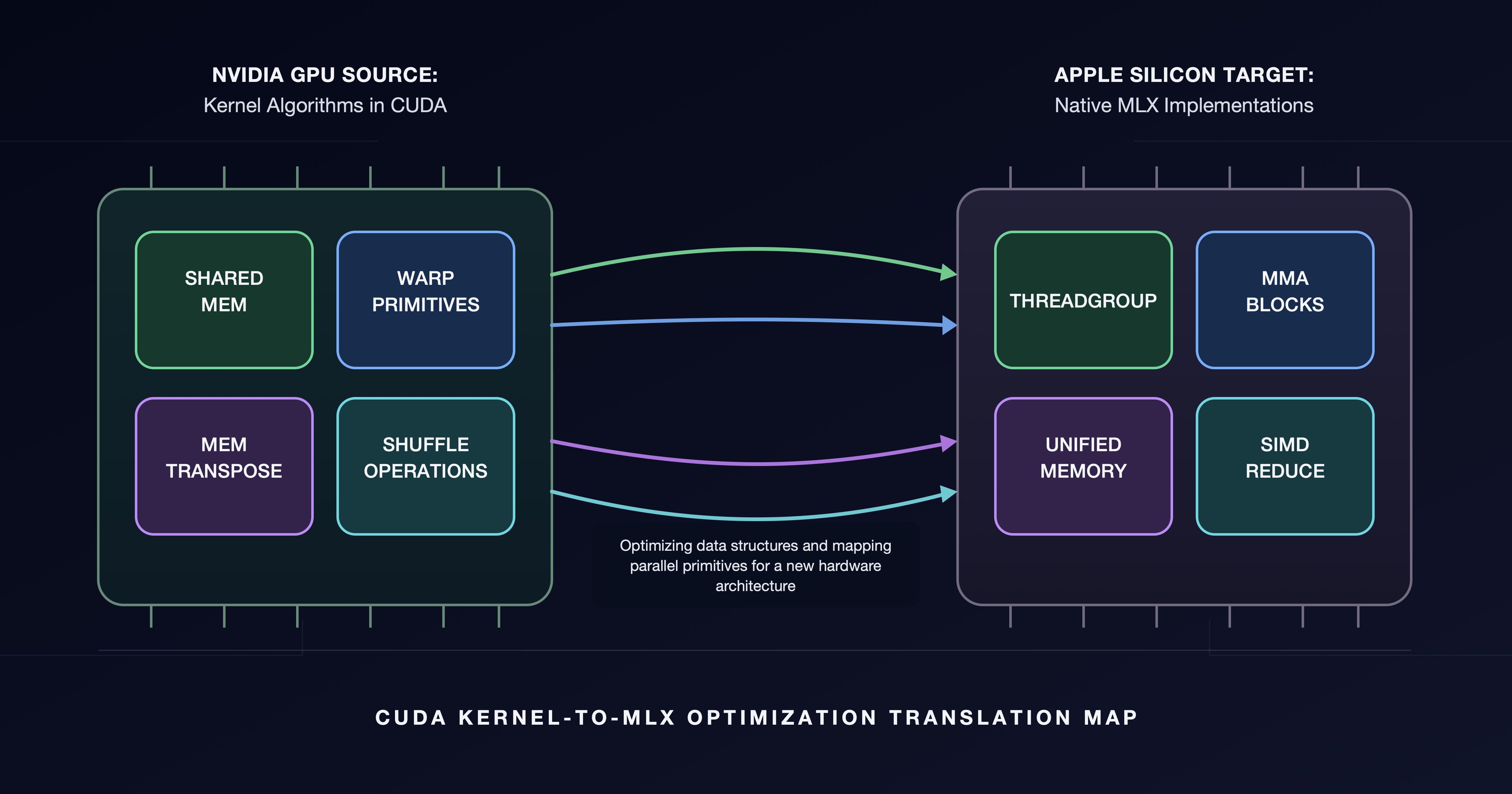
Новая технология преобразования кода CUDA в формат MLX повышает производительность MLX на устройствах с чипами Apple Silicon, устраняя разрыв в работе критически важных графических ядер. Фреймворк MLX оптимизирует работу моделей искусственного интеллекта на устройствах Apple, улучшая производительность для моделей среднего размера.
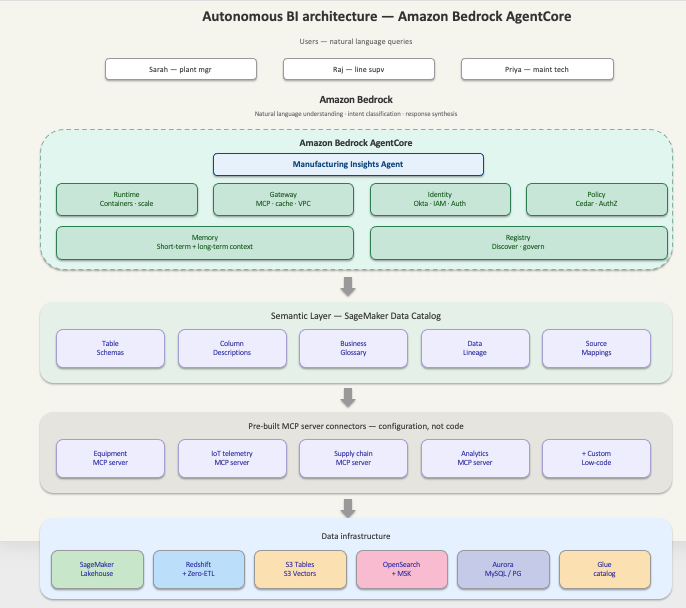
Сара Чен столкнулась с серьезными проблемами интеграции данных при управлении производственными линиями. Различные системы снижают эффективность, приводя к задержкам и необходимости выполнения ручной работы.
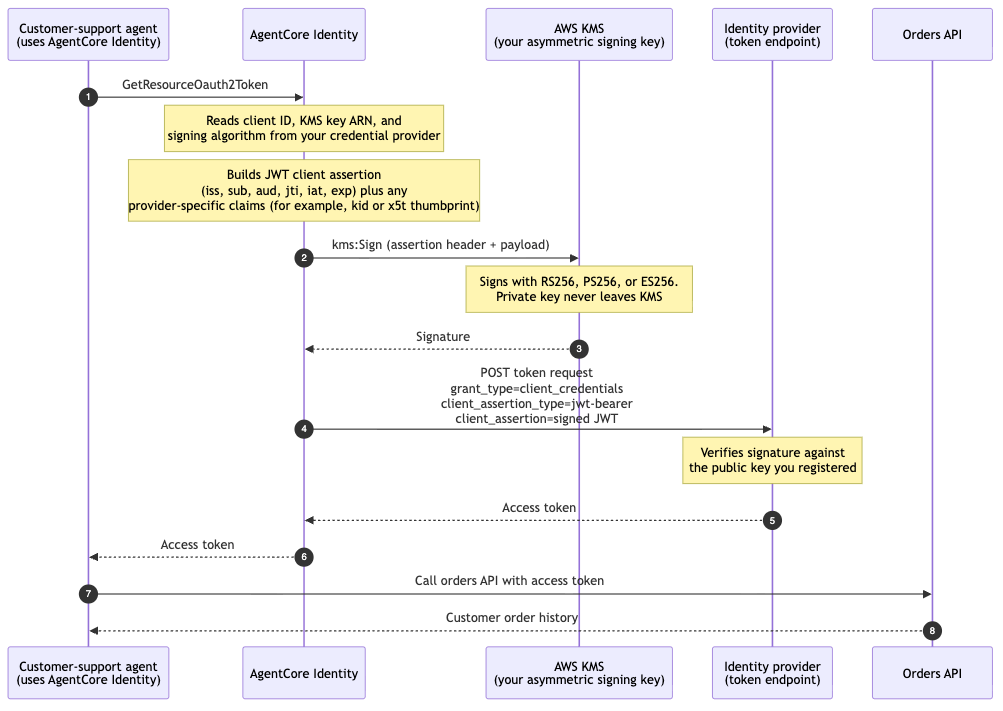
Теперь Amazon Bedrock AgentCore Identity поддерживает аутентификацию клиентов с использованием закрытых ключей JWT для агентов, что повышает уровень безопасности. Закрытые ключи хранятся в сервисе AWS KMS, обеспечивая безопасную аутентификацию без необходимости обмена секретами.
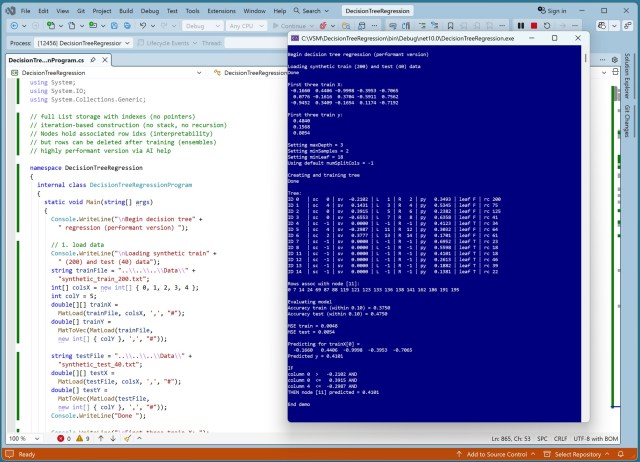
Искусственный интеллект выявил особые случаи в коде регрессии на основе деревьев решений, повысил производительность и увеличил эффективность обучения с использованием синтетического набора данных. Обновленная демонстрация показала оптимизированную версию с улучшенной точностью и возможностями прогнозирования.

Протокол контекста модели (Model Context Protocol, MCP) получил крупное обновление и перешел к протоколу без сохранения состояния, который масштабируется на стандартной инфраструктуре HTTP. Новая версия включает улучшения в управлении, усиливает авторизацию и предоставляет гарантии жизненного цикла, не затрагивая существующие клиенты.
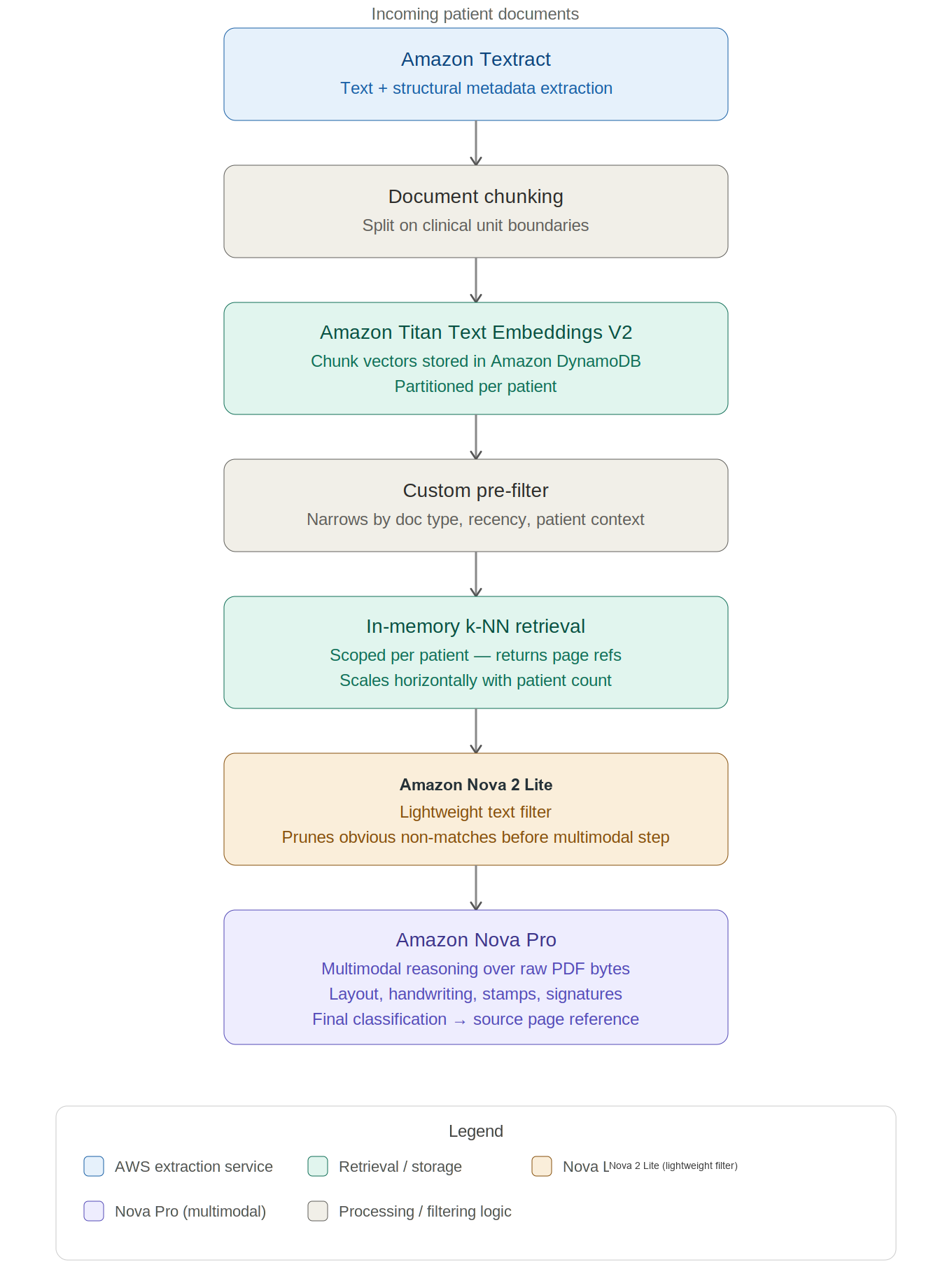
Компания Guardoc Health использует модели Amazon Nova для революционного преобразования клинической документации, снижая количество ошибок на 46% и экономя 400 тысяч долларов в год. Они решают задачу обработки разнообразных медицинских документов с высокой точностью, обеспечивая безопасность пациентов и соблюдение нормативных требований.