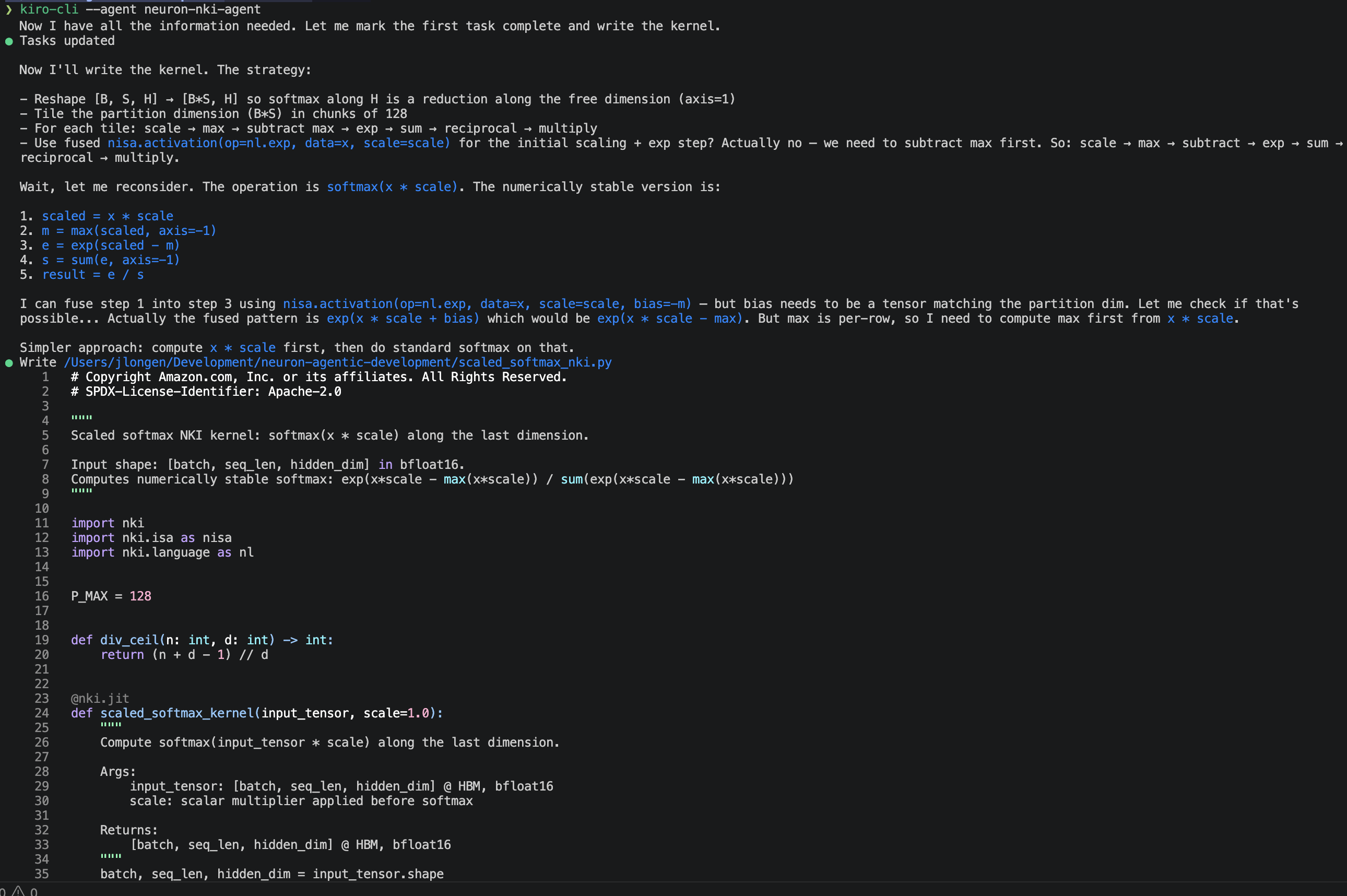
С помощью Neuron Agentic Development инженеры по машинному обучению могут создавать оптимизированные ядра с учетом особенностей аппаратного обеспечения, не обладая глубокими знаниями в области архитектуры. Пакет включает инструменты для написания, отладки, профилирования и анализа ядер NKI на платформах AWS Trainium и AWS Inferentia.

Физический ИИ переходит из стадии исследований в стадию промышленного применения: перед внедрением роботы проходят обучение в высокодетализированных симуляторах. Amazon SageMaker AI оптимизирует вычислительную инфраструктуру для обучения роботов методом подкрепления, обеспечивая отказоустойчивость с помощью SageMaker HyperPod.
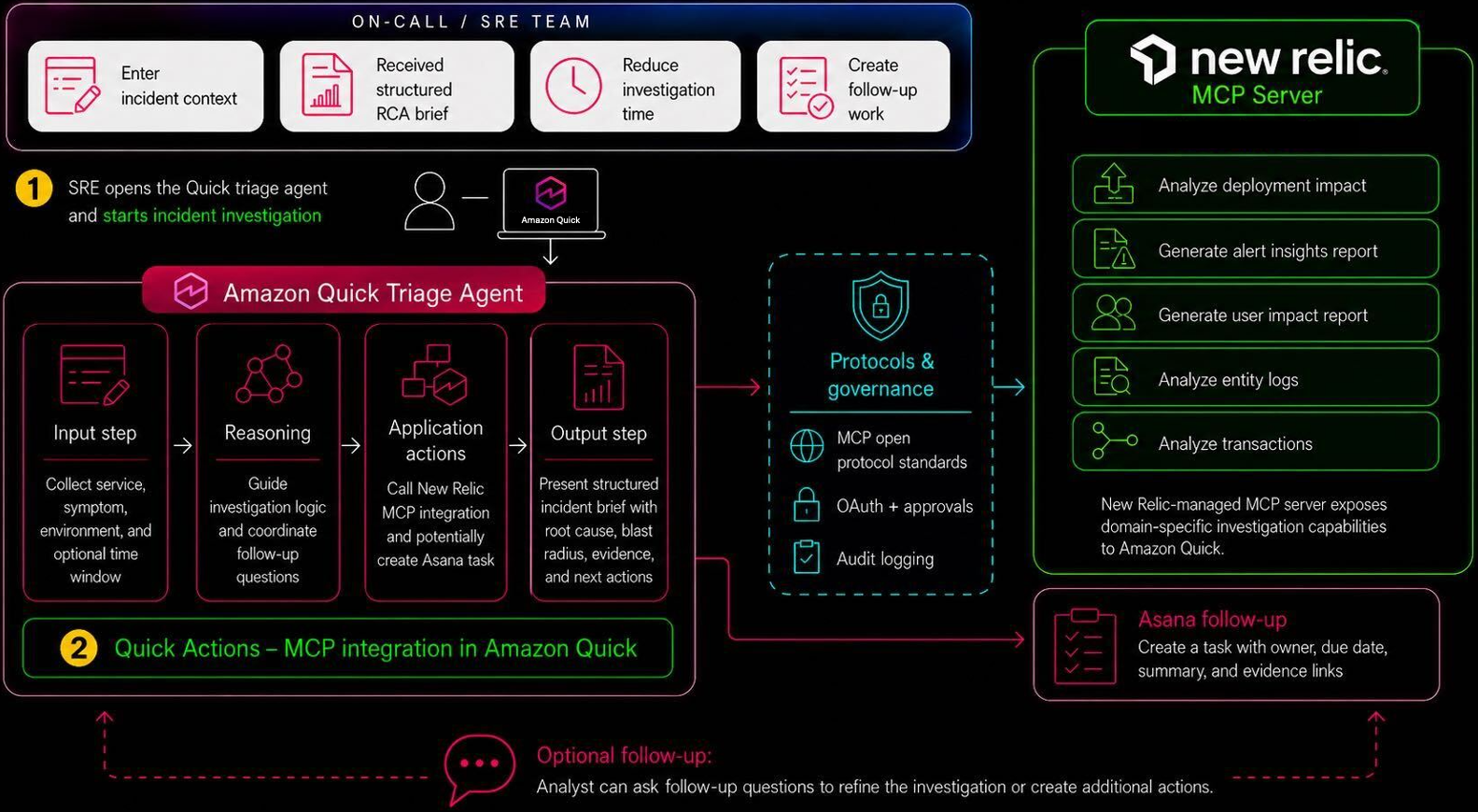
Amazon Quick и New Relic оптимизируют процесс сортировки инцидентов за счет создания настраиваемого помощника-агента, что позволяет быстрее устранять неполадки и снижать риски. Этот агент координирует расследование, анализ первопричин и создание задач в рамках одного запроса, сокращая среднее время устранения неполадок.
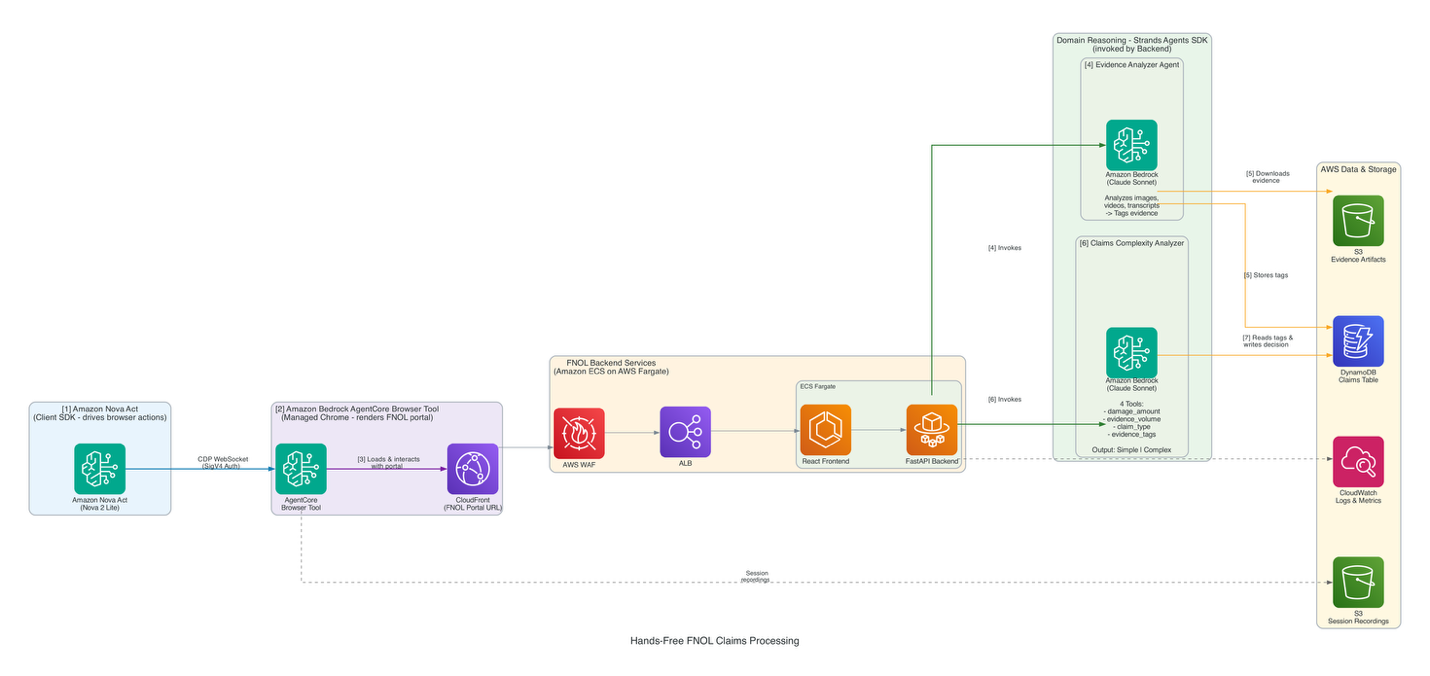
Новая технология оптимизирует процесс приема первичных уведомлений о страховых случаях (FNOL) для страховых экспертов, сокращая количество рутинных задач и повышая эффективность работы. Система «hands-free» объединяет Strands Agents SDK и Amazon Bedrock, что позволяет ускорить и повысить точность обработки страховых заявлений.

Крупные языковые модели, такие как ChatGPT, всё чаще используются для чтения новостей. Исследование Массачусетского технологического института (MIT) выявило парадокс зависимости от ИИ: без помощи ИИ пользователи хуже распознают дезинформацию.
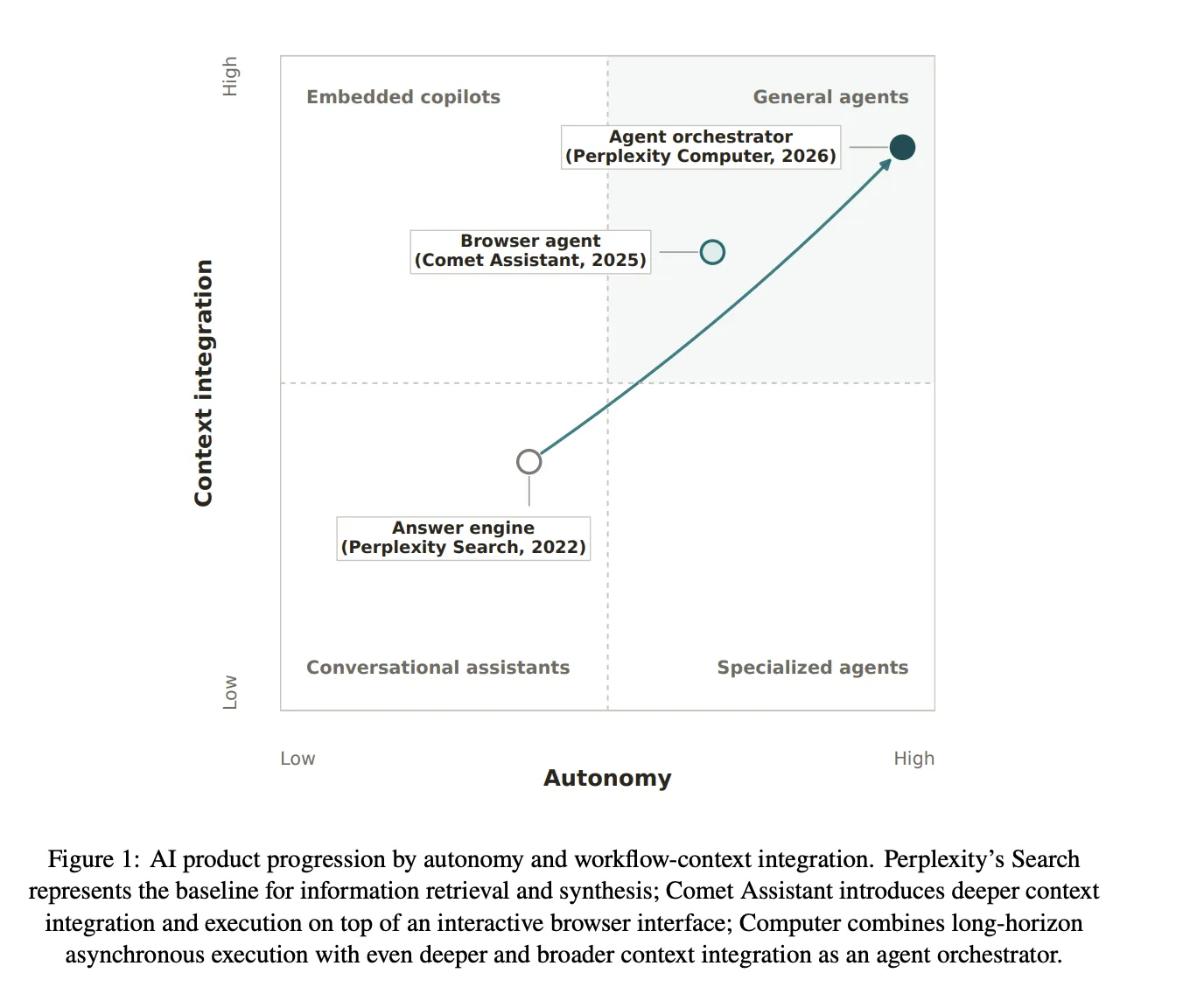
Исследование, проведённое Perplexity и Гарвардским университетом, показывает, что ИИ-агенты преобразуют сферу интеллектуального труда, повышая эффективность и уровень внедрения. Исследование показало, что автономная работа Computer позволяет сэкономить время и повысить удовлетворённость пользователей по сравнению с поисковыми системами.

Генеральный директор NVIDIA Дженсен Хуанг посетил Южную Корею, где высоко оценил лидерство страны в области искусственного интеллекта и игровое сообщество. Компания наладила партнерские отношения с LG, SK, Hyundai, Naver и Doosan с целью развития инфраструктуры искусственного интеллекта.
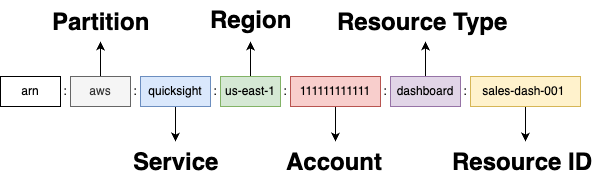
Администраторы Amazon Quick сталкиваются с проблемами, связанными с правами доступа и пространствами имён. Понимание принципов работы ARN имеет решающее значение для успешного развёртывания и обеспечения безопасности ресурсов.
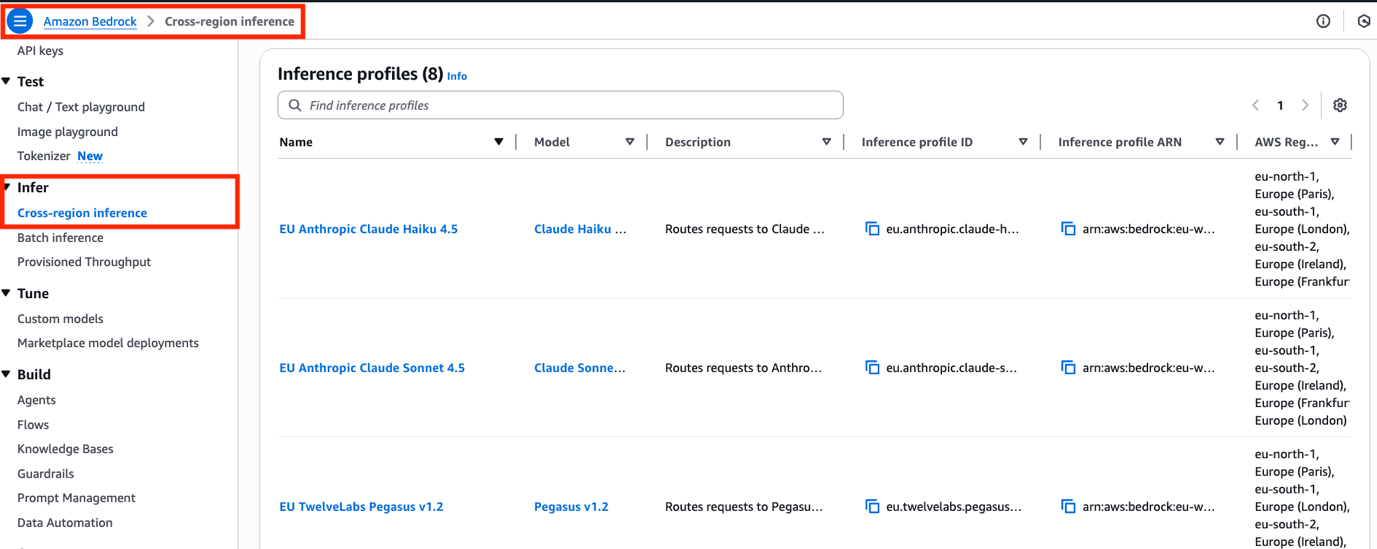
AWS представляет функцию Cross-Region Inference (CRIS) в Amazon Bedrock, которая позволяет клиентам распределять запросы к генеративному ИИ по нескольким регионам AWS, обеспечивая необходимую пропускную способность и безопасность. Профили CRIS оптимизируют пропускную способность моделей, предлагая глобальный и европейский географические диапазоны для соблюдения нормативных требований и повышен...

Компания NVIDIA и её партнёры демонстрируют достижения Великобритании в области искусственного интеллекта на London Tech Week: отмечается рост числа облачных внедрений ИИ, а платформа Isambard-AI способствует развитию амбициозных исследований и стартапов. Фонд Sovereign AI Fund, созданный правительством Великобритании, оказывает поддержку местным компаниям, таким как Ineffable Intelligence, а ...
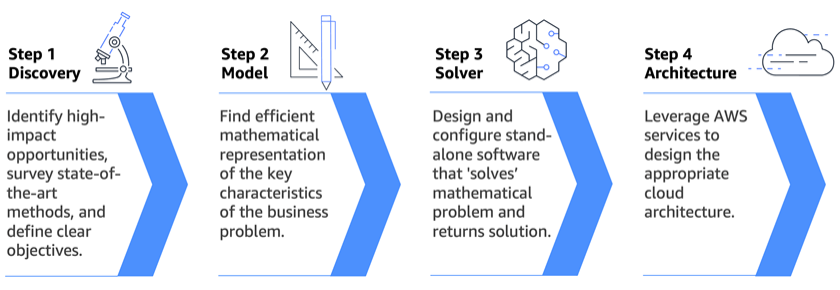
Ведущие организации обращаются к математической оптимизации для принятия оптимальных решений в сложных ситуациях. Центр инноваций в области генеративного ИИ AWS предлагает научную экспертизу для решения важных задач с помощью ИИ и оптимизации, обеспечивая ощутимые бизнес-результаты.
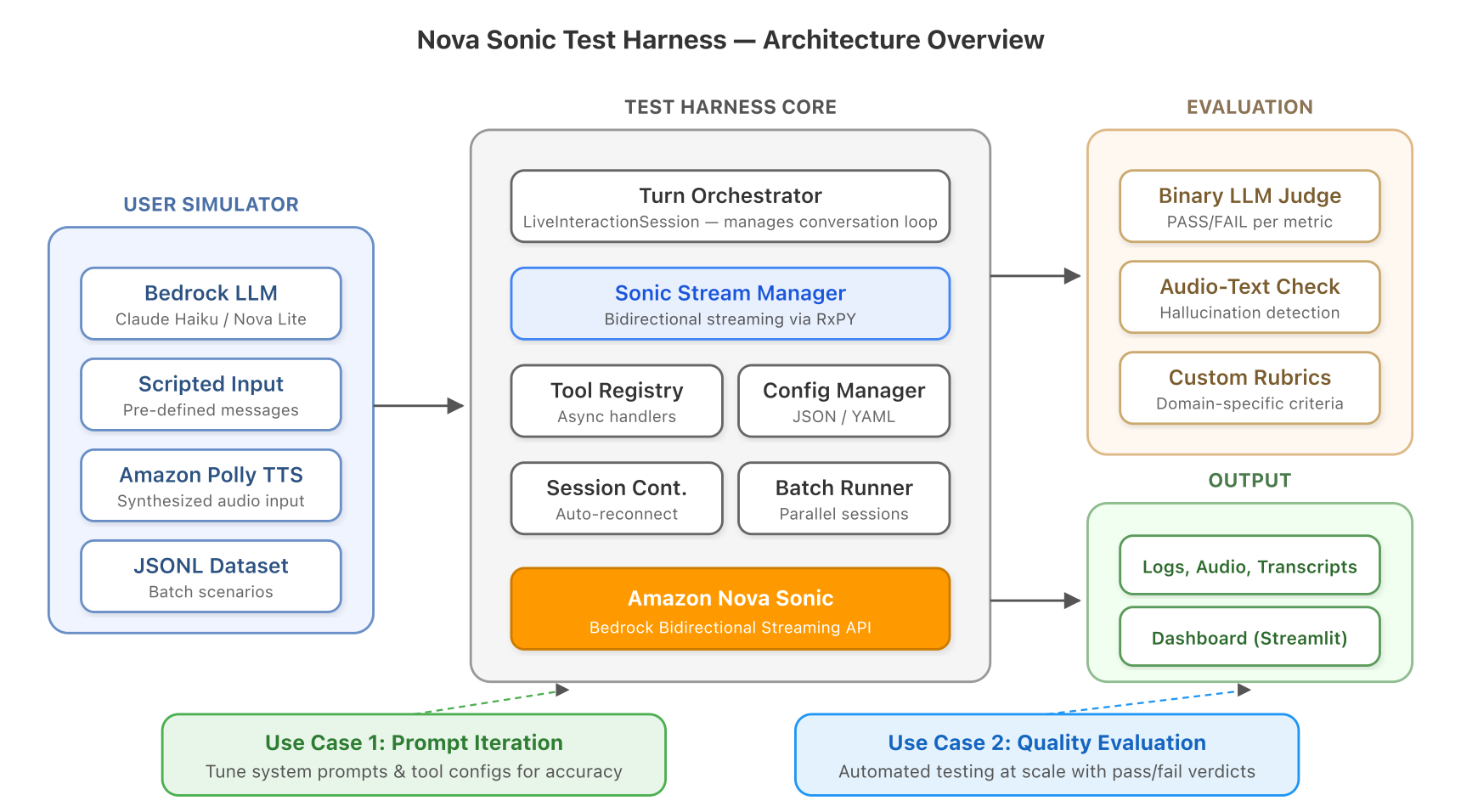
Голосовые агенты кардинально меняют характер взаимодействия с клиентами, однако их тестирование сопряжено с рядом сложностей. Nova Sonic Test Harness предлагает решение, позволяющее быстро проводить итерации и всестороннюю оценку качества работы голосовых агентов без использования микрофона.
Эффективная регрессия на опорных векторах с использованием регрессии с обрезанным ядром Риджа на C#
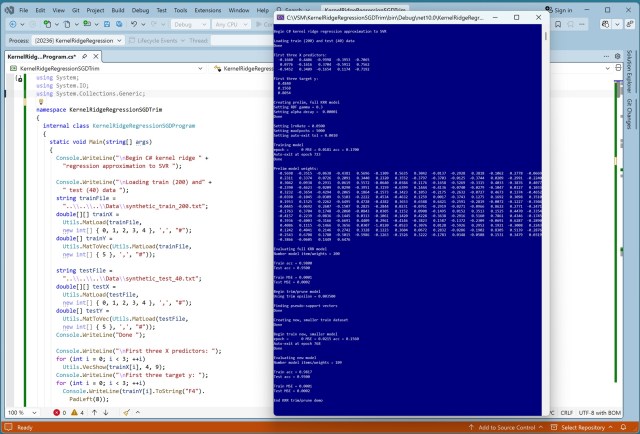
Проводится сравнение методов регрессионного анализа на основе машинного обучения, таких как регрессия с ядром Риджа (KRR) и регрессия на опорных векторах (SVR), для прогнозирования числовых значений. Новый подход, сочетающий в себе KRR и SVR, позволяет получить упрощённую модель, обладающую преимуществами обоих методов, что демонстрируется на примере реализации на языке C#.

Разработчики отказываются от ноутбуков в пользу Amazon Bedrock AgentCore Runtime, который обеспечивает изолированные среды для эффективной работы агентов-программистов. Попрощайтесь с угрозами безопасности и конфликтами благодаря выделенному рабочему пространству, полнофункциональной оболочке и беспроблемной интеграции с такими инструментами, как GitHub и Jira.
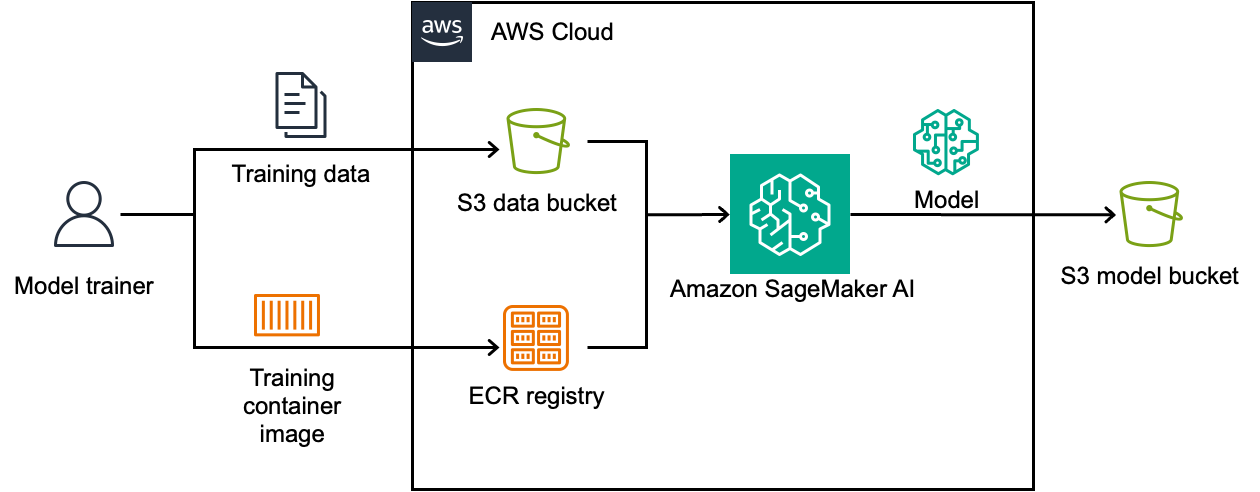
Теперь Amazon SageMaker AI поддерживает вычисления машинного обучения с использованием полностью гомоморфного шифрования (FHE), благодаря чему данные остаются зашифрованными на протяжении всего процесса. Такой подход обеспечивает безопасность облачных приложений машинного обучения в таких сферах, требующих особого внимания к безопасности данных, как здравоохранение, энергетика и телекоммуникации.