
Новое исследование показало, что автомобиль TeslaИсследование проводилось Страховым институтом дорожной безопасности.
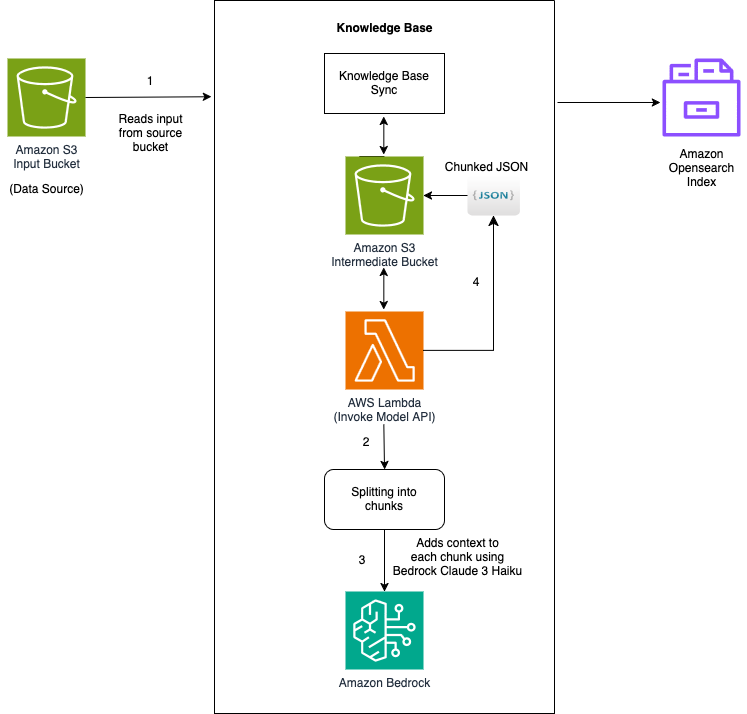
Разработчики расширяют большие языковые модели с помощью контекстного поиска, улучшая ответы путем добавления поясняющего контекста к каждому фрагменту перед генерацией вкраплений. Этот метод смягчает ограничения традиционных систем RAG, сохраняя зависимости между фрагментами, что позволяет получать более точные и тонкие ответы.
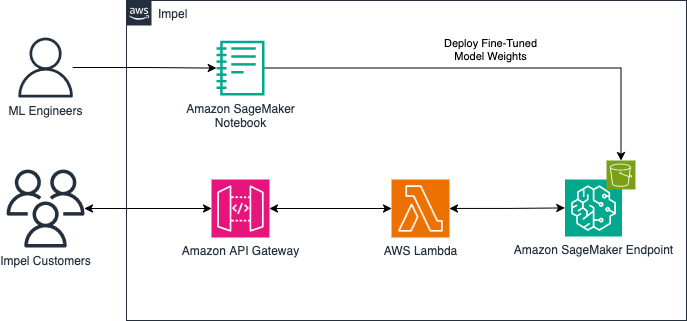
Impel совершенствует розничную торговлю автомобилями с помощью искусственного интеллекта Sales AI, повышая точность на 20% с помощью SageMaker AI. ИИ в сфере продаж обеспечивает персонализированное взаимодействие с клиентами, стимулируя дилерские операции и взаимодействие.
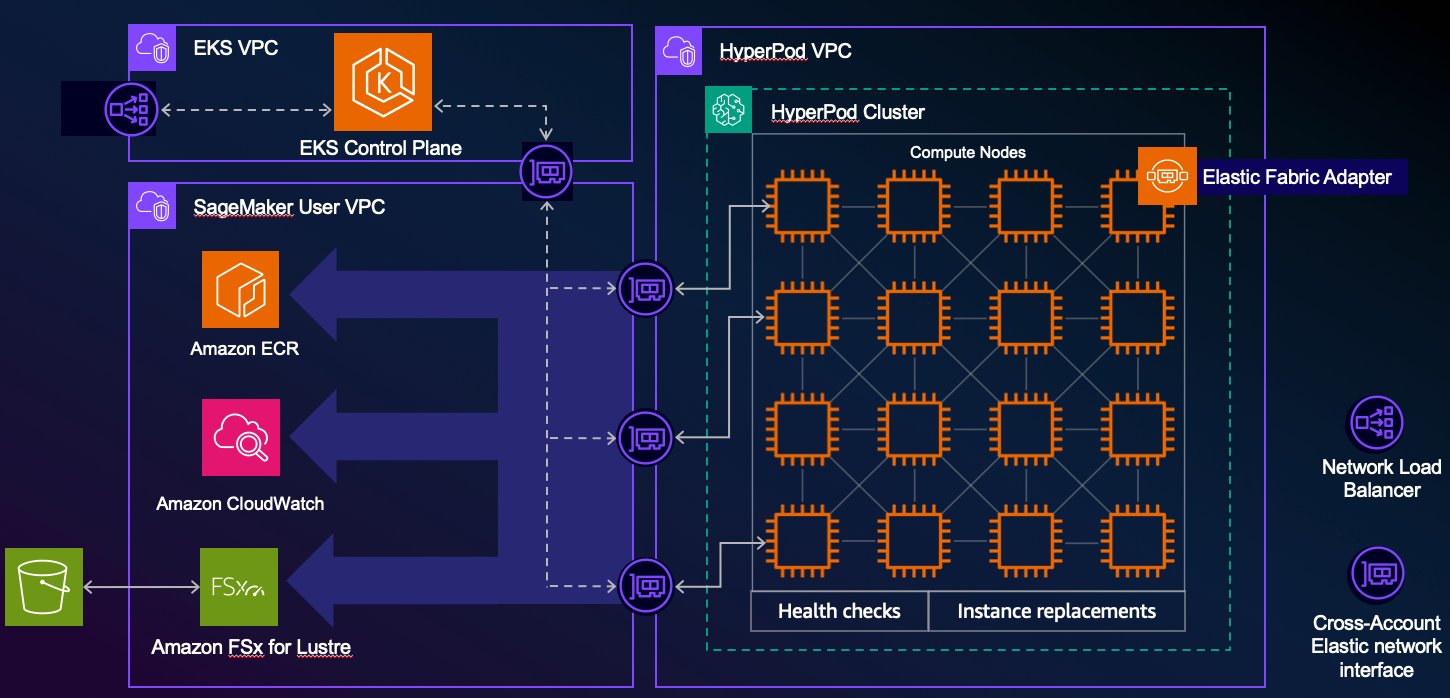
Стартапы в области климатических технологий используют генеративный ИИ для борьбы с климатическим кризисом, применяя AWS SageMaker HyperPod для масштабируемых решений. Расширенные вычислительные возможности и специализированные модели помогают стартапам экономить время и деньги, концентрируясь на инновациях.

Reddit подал в суд на компанию Anthropic за то, что она якобы без согласия пользователей собирала их комментарии для обучения чатбота Клода. Anthropic обвиняется в использовании ботов для доступа к личным данным, несмотря на просьбу Reddit не делать этого.

Бьорн Ульвеус из Abba использует искусственный интеллект для написания нового мюзикла, подчеркивая роль технологий в преодолении творческих барьеров на SXSW в Лондоне. 80-летний музыкант рассказывает о влиянии искусственного интеллекта на его творческий процесс, подчеркивая его помощь в создании нового мюзикла.
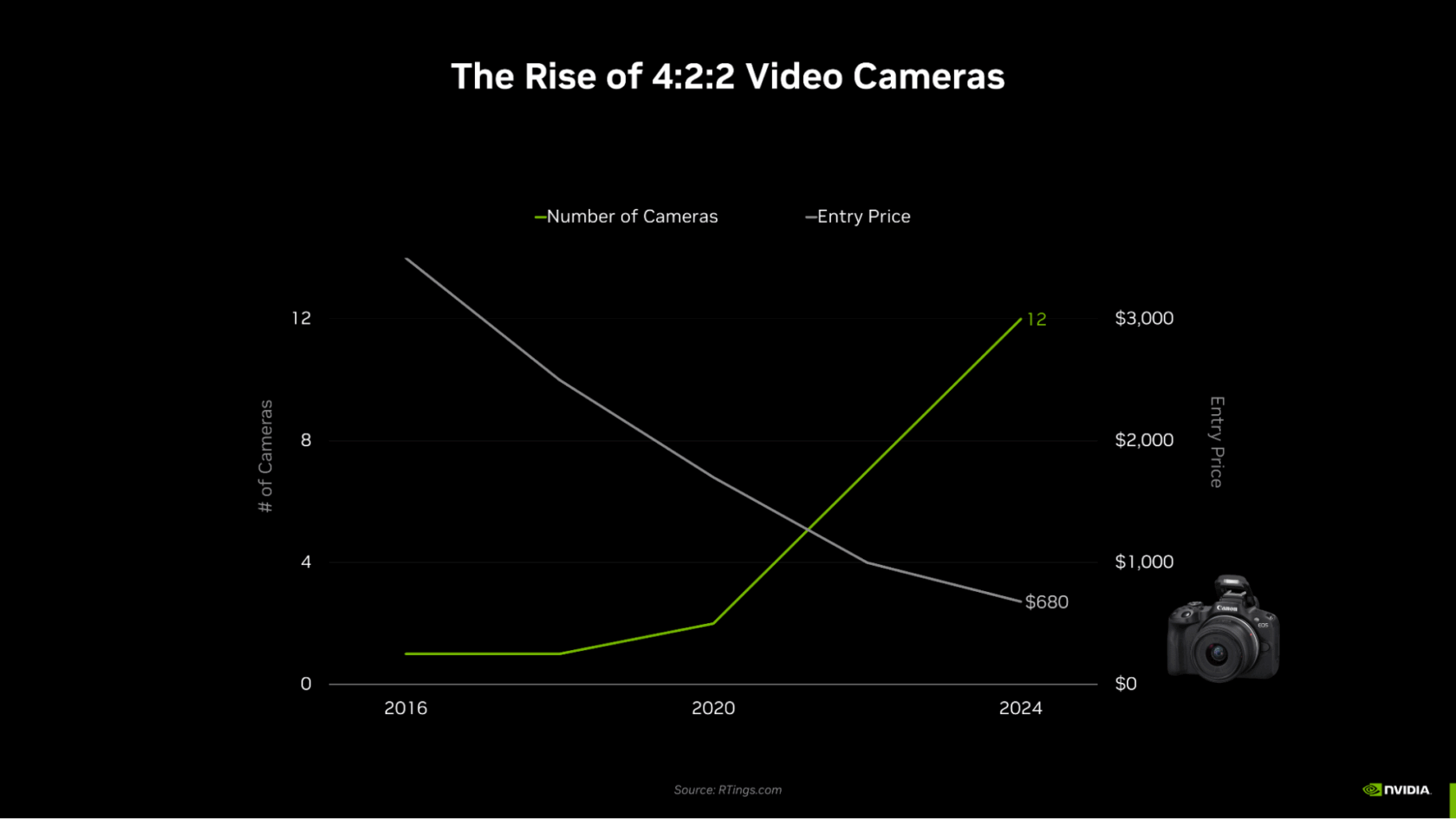
Камеры 4:2:2 передают вдвое больше информации о цвете для лучшего качества видео. Графические процессоры NVIDIA RTX поддерживают кодирование 4:2:2 для улучшения рабочих процессов редактирования.
Оперативное кэширование Amazon Bedrock улучшает кодирование с помощью искусственного интеллекта в Claude Code, снижая задержки и стоимость токенов. Claude Code революционизирует ассистентов кодирования, интеллектуально управляя точками кэширования для молниеносных ответов и снижения затрат.

Палата лордов побеждает правительство в вопросе использования компаниями ИИ материалов, защищенных авторским правом, и требует защиты авторских прав художников. Правительству предъявлен ультиматум: изменить законодательство или потерять поддержку.

По прогнозам Дарио Амодея из Anthropic, развитие искусственного интеллекта может привести к ликвидации половины рабочих мест для белых воротничков начального уровня через 1-5 лет. Безработица в США может достичь 10-20 % к концу десятилетия из-за быстрых технологических изменений.

Молодые тайцы все чаще используют инструменты искусственного интеллекта, такие как ChatGPT, для получения советов по отношениям, получая глубокие рекомендации из нечеловеческого источника. Опыт Вана свидетельствует о том, что в Таиланде происходит переход к гаданиям с использованием технологий.

Генеральный директор BBC и босс Sky выступают против предложения по авторскому праву, позволяющего технологическим компаниям получать доступ к творческим работам без разрешения, что угрожает стоимости сектора в 125 млрд фунтов стерлингов. Творческая индустрия призывает к введению правила opt-in и заключению лицензионных сделок для защиты авторских прав от законодательства об искусственном инте...

Генеративные модели ИИ могут не привести к настоящему AGI, поскольку им не хватает воплощенного понимания. Языковые модели, такие как LLM, могут иметь лишь поверхностное представление о реальности, несмотря на свои впечатляющие способности.

Мошенники используют потоковые сервисы с поддельными треками, сгенерированными искусственным интеллектом, что негативно сказывается на инди-артистах. Музыкальной индустрии предстоит борьба, поскольку на таких платформах, как Spotify и Apple Music, все чаще используются тактики манипулирования.
Расширение возможностей беженцев с помощью искусственного интеллекта: масштабируемое решение на AWS
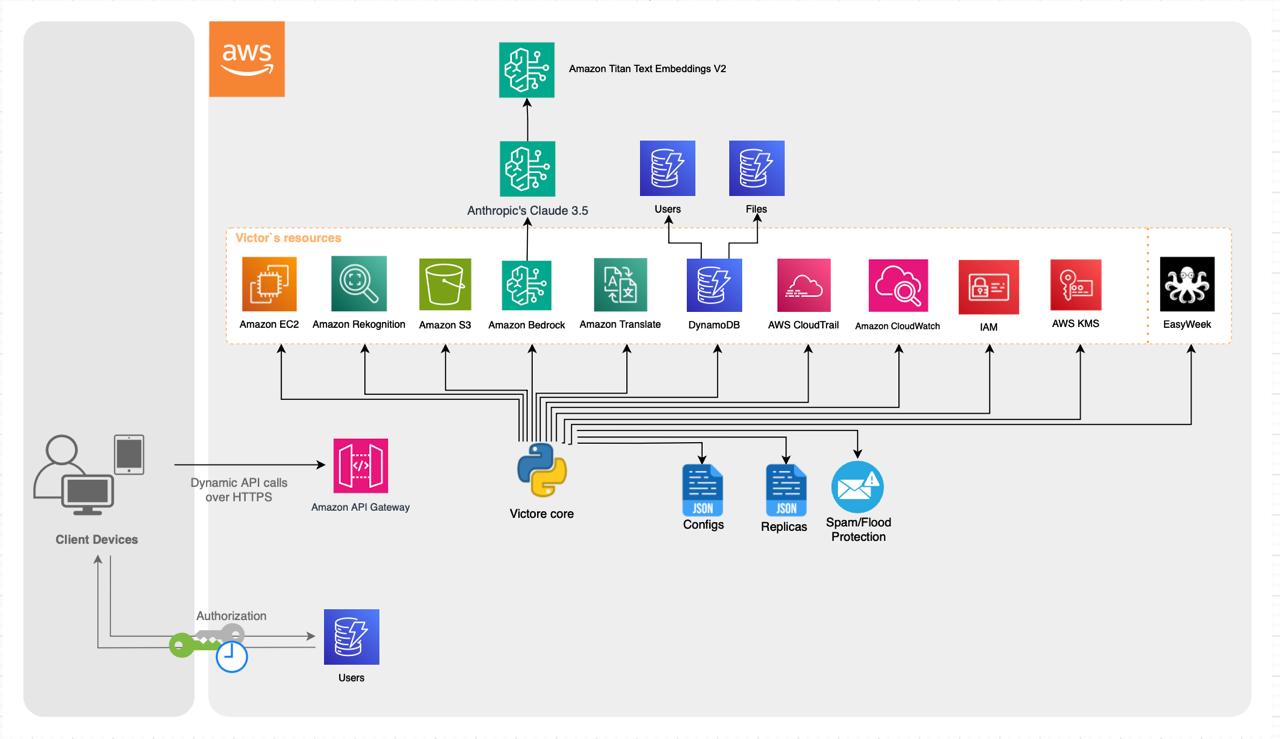
ИИ-помощник Виктор из Bevar Ukraine помогает украинским беженцам в Дании, используя сервисы AWS для масштабируемости и защиты данных. Система, разработанная добровольцами, использует Claude 3.5 LLM от Anthropic для создания естественных и увлекательных ответов.