
Робототехника развивается: исследовательский центр NVIDIA Research демонстрирует технологию переноса результатов моделирования в реальные условия, позволяющую роботам адаптироваться и надежно работать в динамичных средах. Среди инноваций — координация действий нескольких манипуляторов с помощью ScheduleStream и набора правил COMPASS для различных типов роботов, что обеспечивает значительное по...
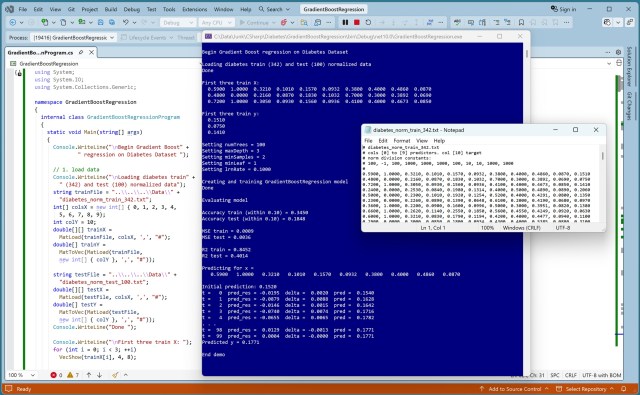
Практикуя навыки программирования, разработчик тестирует модель регрессии с градиентным бустом на наборе данных по диабету, демонстрируя изящную технику, лежащую в основе этой ансамблевой модели. Реализуя 100 деревьев решений на языке C#, разработчик исследует тонкий, но эффективный подход к прогнозированию остаточных значений с целью повышения точности.
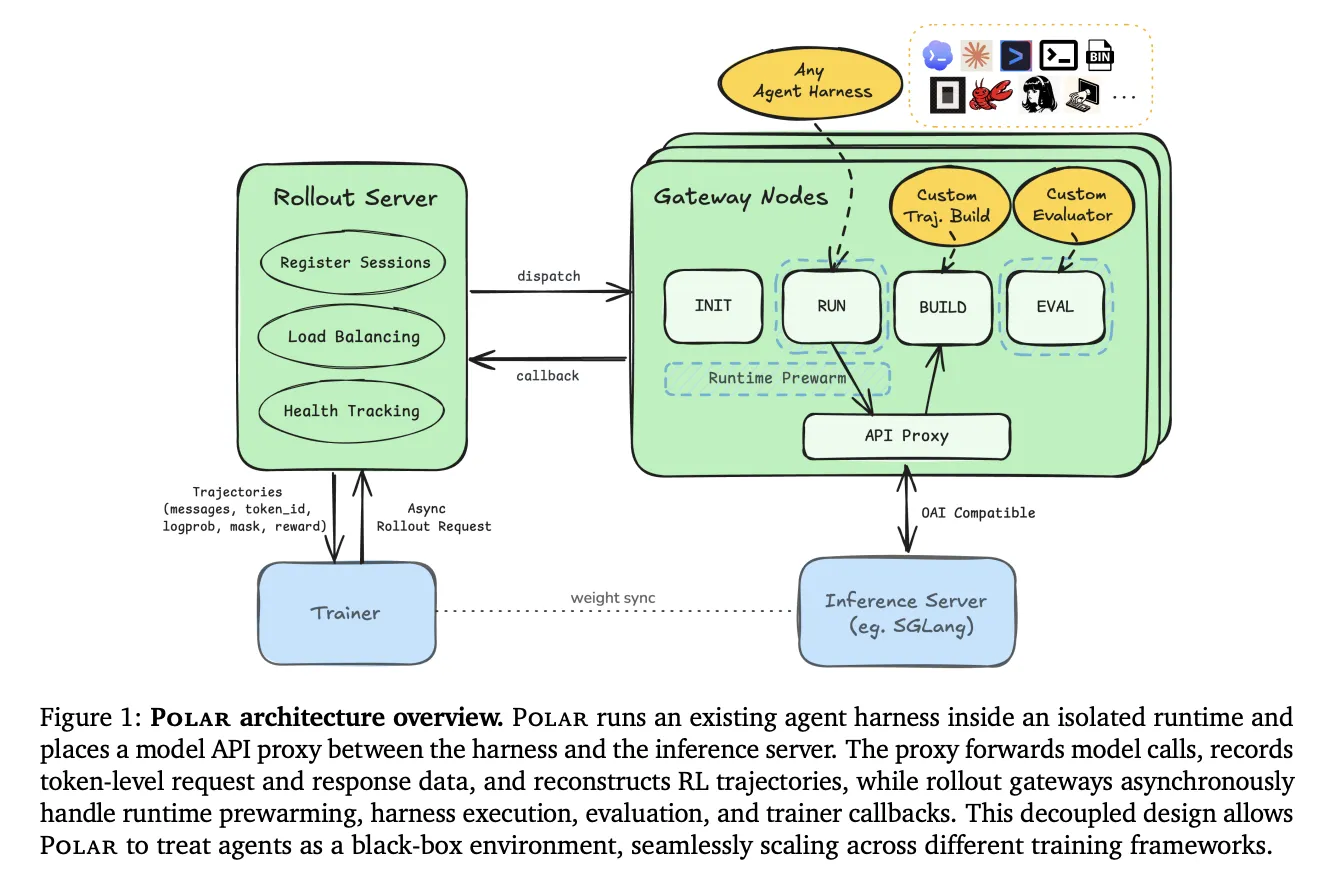
Компания NVIDIA представляет Polar — платформу для внедрения методов обучения с подкреплением в языковых агентах. Polar упрощает интеграцию агентов с существующими тестовыми средами, повышает совместимость API моделей и оптимизирует процессы обучения.
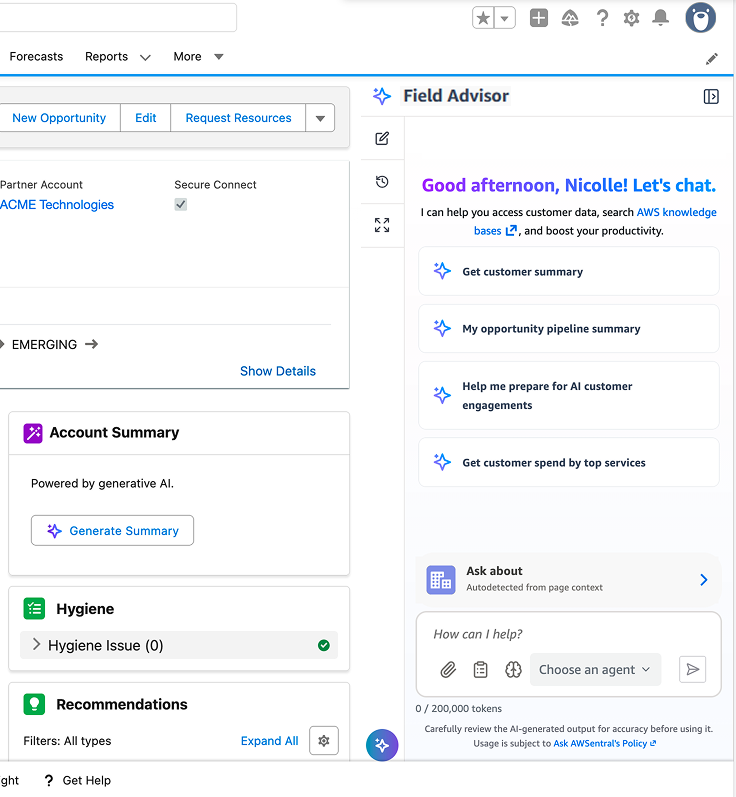
Field Advisor на платформе Amazon Bedrock AgentCore оптимизирует координацию работы агентов в отделе продаж AWS, снижая когнитивную нагрузку и улучшая взаимодействие с клиентами. Этот внутренний диалоговый помощник повышает производительность за счет перенаправления запросов специализированным агентам, что позволяет торговым представителям сосредоточиться на потребностях клиентов.
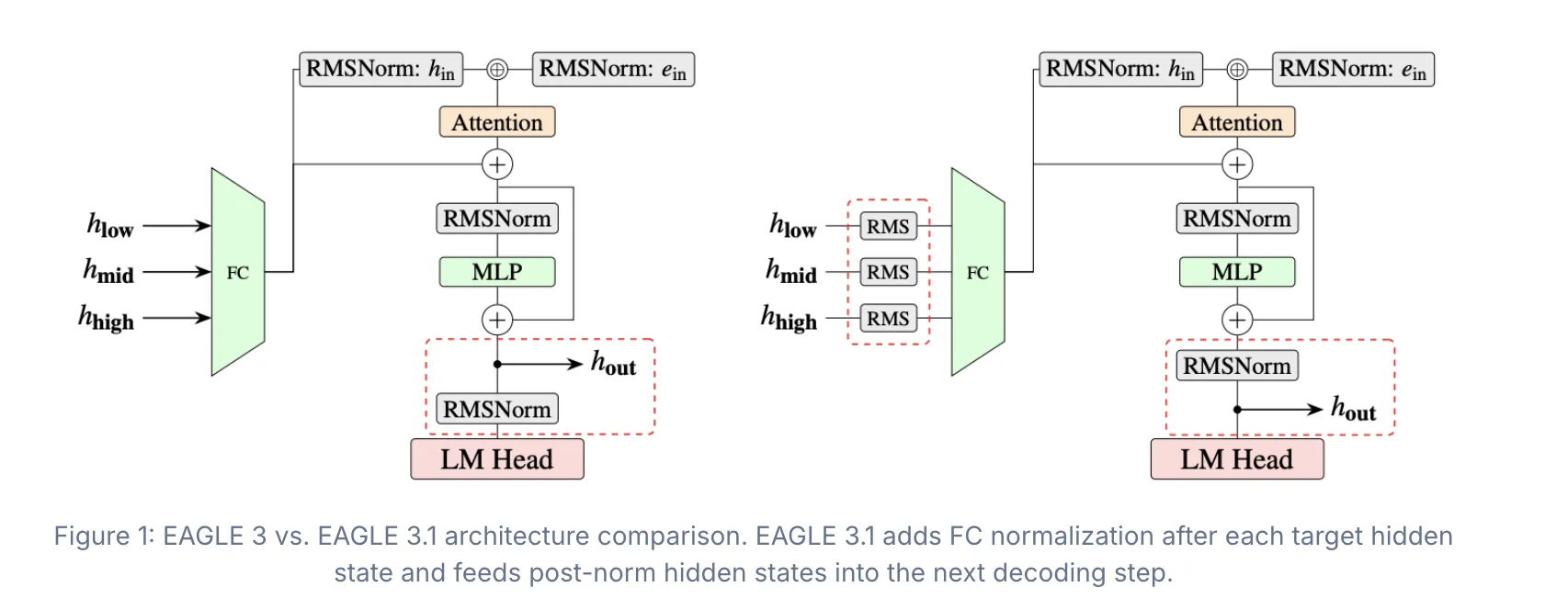
Команды EAGLE Team, vLLM Team и TorchSpec Team представляют версию EAGLE 3.1, которая повышает надежность спекулятивного декодирования. EAGLE 3.1 решает проблемы с отклонением внимания, обеспечивая повышенную стабильность и производительность в различных условиях.
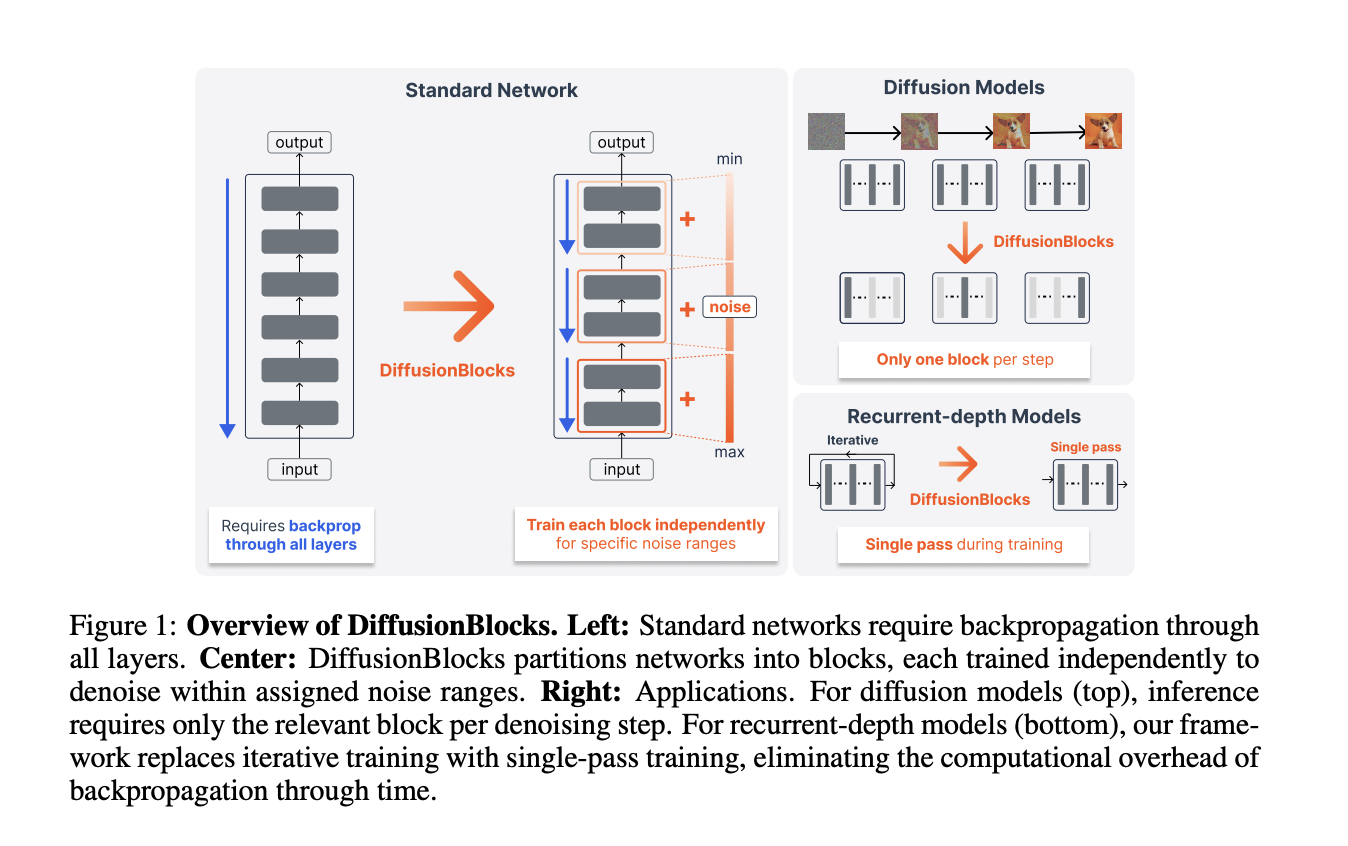
Исследователи из компании Sakana AI и Токийского университета представляют DiffusionBlocks — метод обучения сетей на основе трансформеров по одному блоку за раз, позволяющий сократить потребление памяти в B раз. Благодаря применению дискретизации Эйлера к связям между остаточными векторами данный метод обеспечивает независимое обучение каждого блока с использованием собственной локальной цели,...
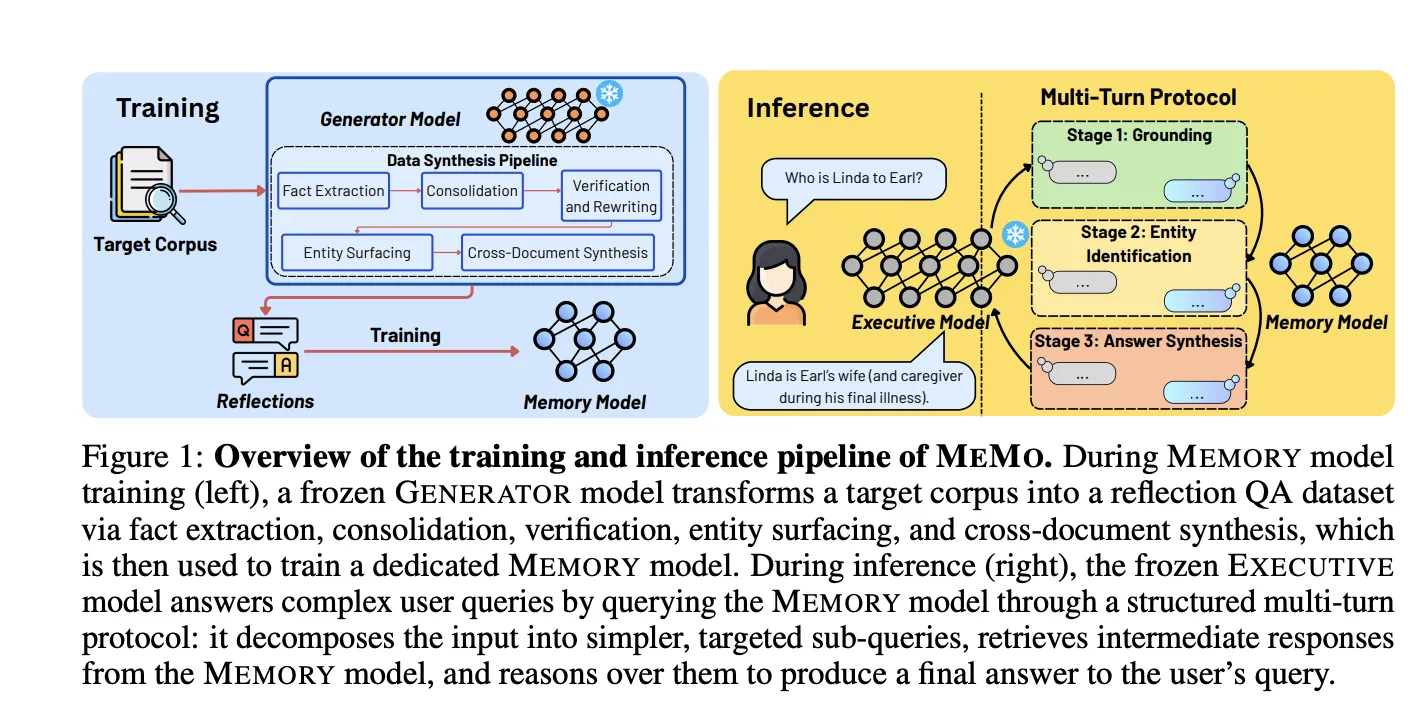
Исследователи из Национального университета Сингапура и Массачусетского технологического института (MIT) предлагают систему MEMO для обновления больших языковых моделей (LLM) без потери качества, используя отдельные модели памяти и логического вывода. Уникальный конвейер обучения MEMO генерирует разнообразные пары «вопрос-ответ», что позволяет модели усваивать знания для логического вывода на ...

Amazon Bedrock Data Automation оптимизирует извлечение данных из финансовых документов с помощью настраиваемых шаблонов, обеспечивающих точность и эффективность. Базовые модели, такие как Anthropic Claude, расширяют возможности OCR для извлечения структурированных и пригодных к использованию данных.
Для создания приложений на базе ИИ больше не требуются глубокие знания в области машинного обучения. С помощью Strands Agents и сервисов AWS можно создавать интеллектуальных агентов всего за 30 строк кода, что упрощает разработку решений на базе ИИ для сред AWS.
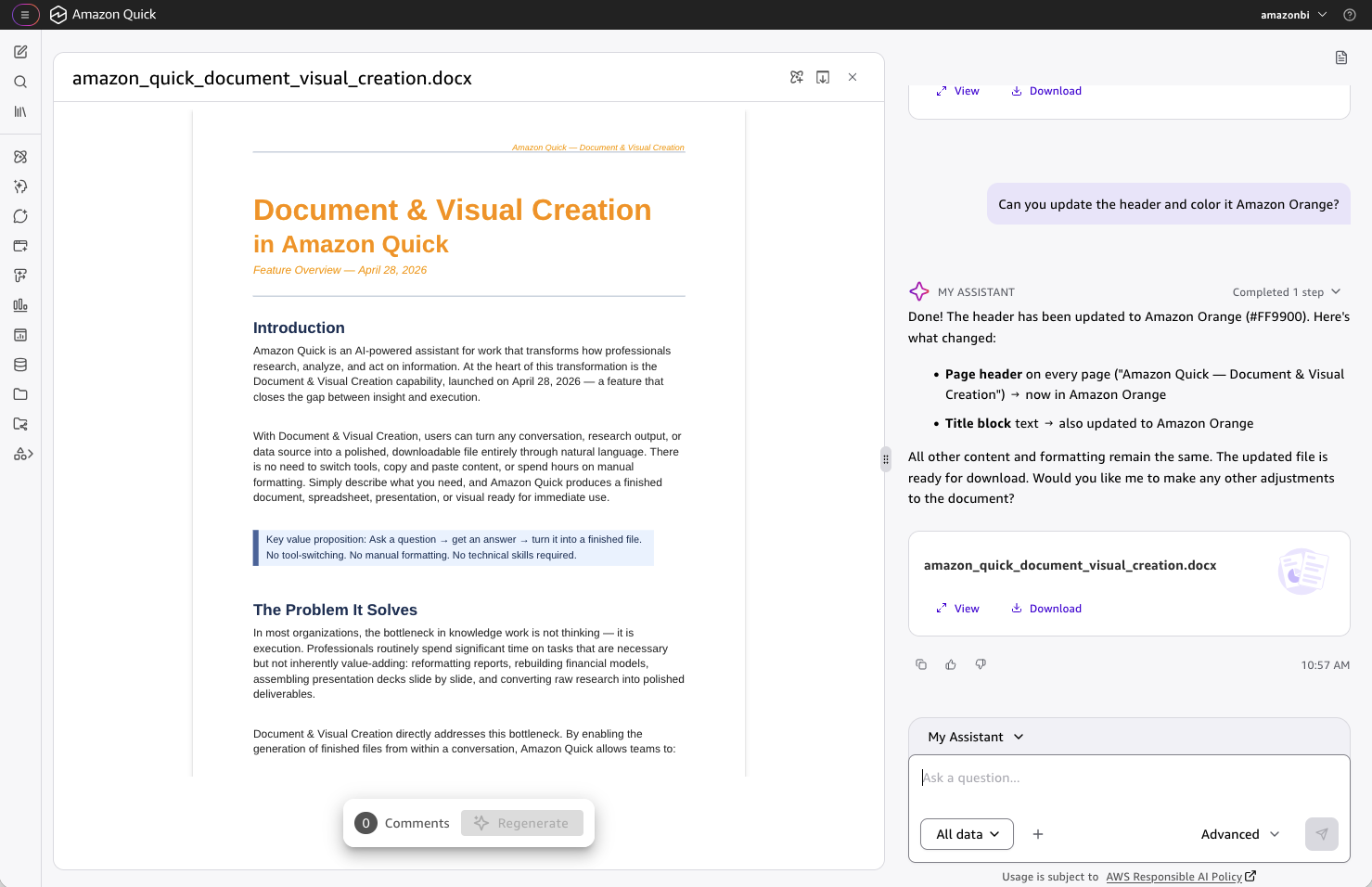
Amazon Quick позволяет специалистам создавать отформатированные документы и визуальные материалы на основе актуальных данных, что позволяет сэкономить время на рутинных задачах. Результаты могут быть выведены в форматах Word, Excel, PowerPoint, PDF, а также в виде бизнес-визуализаций, причем все они полностью доступны для редактирования, что позволяет продолжать работу без необходимости повтор...
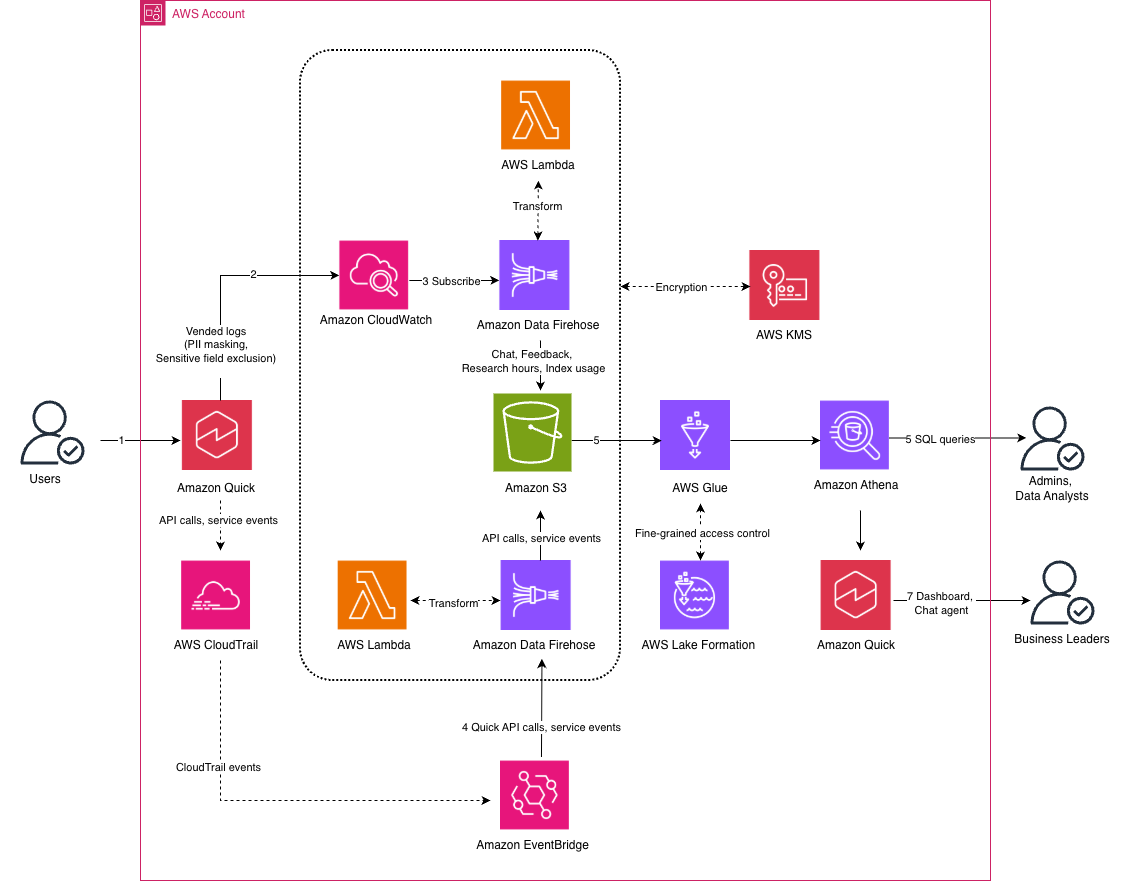
Amazon Quick представляет собой централизованное решение для мониторинга корпоративных платформ искусственного интеллекта, которое объединяет данные об использовании для более эффективного отслеживания и анализа. Благодаря интеграции с сервисами AWS Amazon Quick обеспечивает мониторинг, аналитику и управление с помощью защищенного хранилища данных, Amazon Athena и панели инструментов Quick Sight.
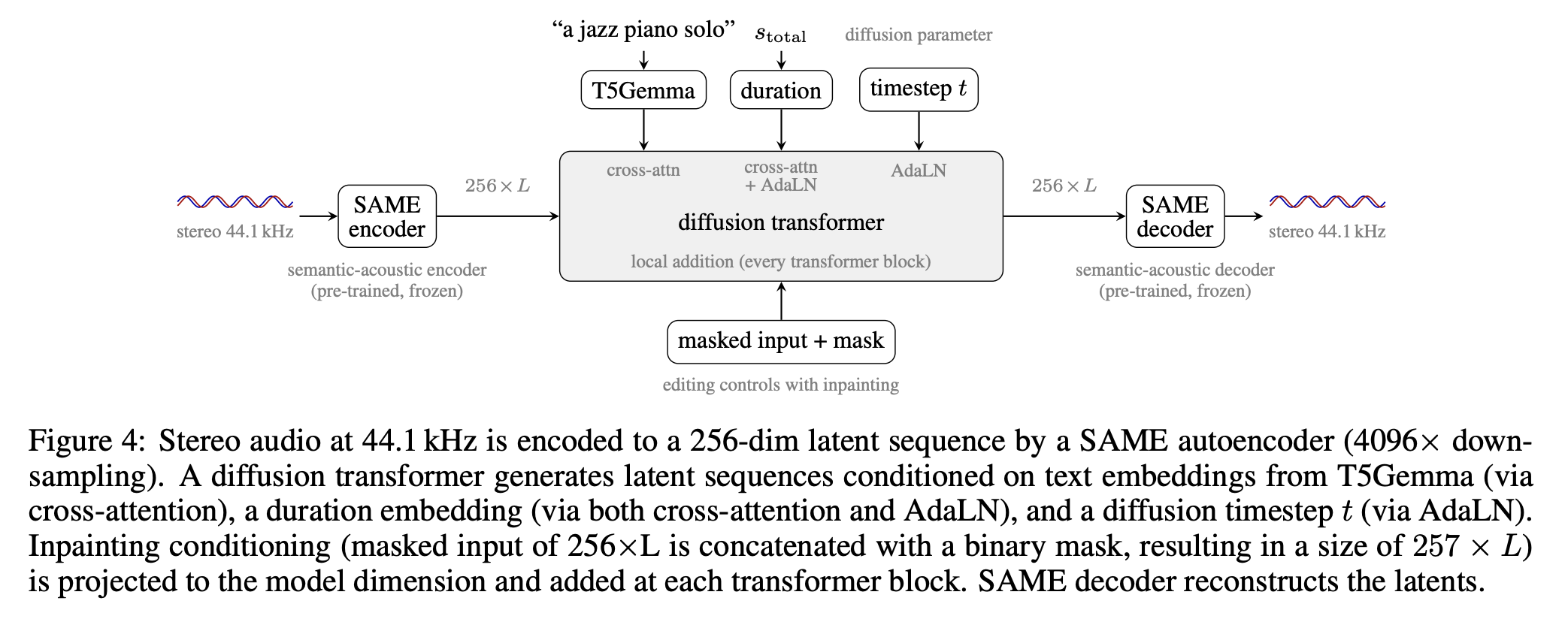
Компания Stability AI выпустила Stable Audio 3 с открытыми весами и техническим документом. Модели латентной диффузии поддерживают вывод данных переменной длины и редактирование на основе ретуширования для генерации стереозвука.
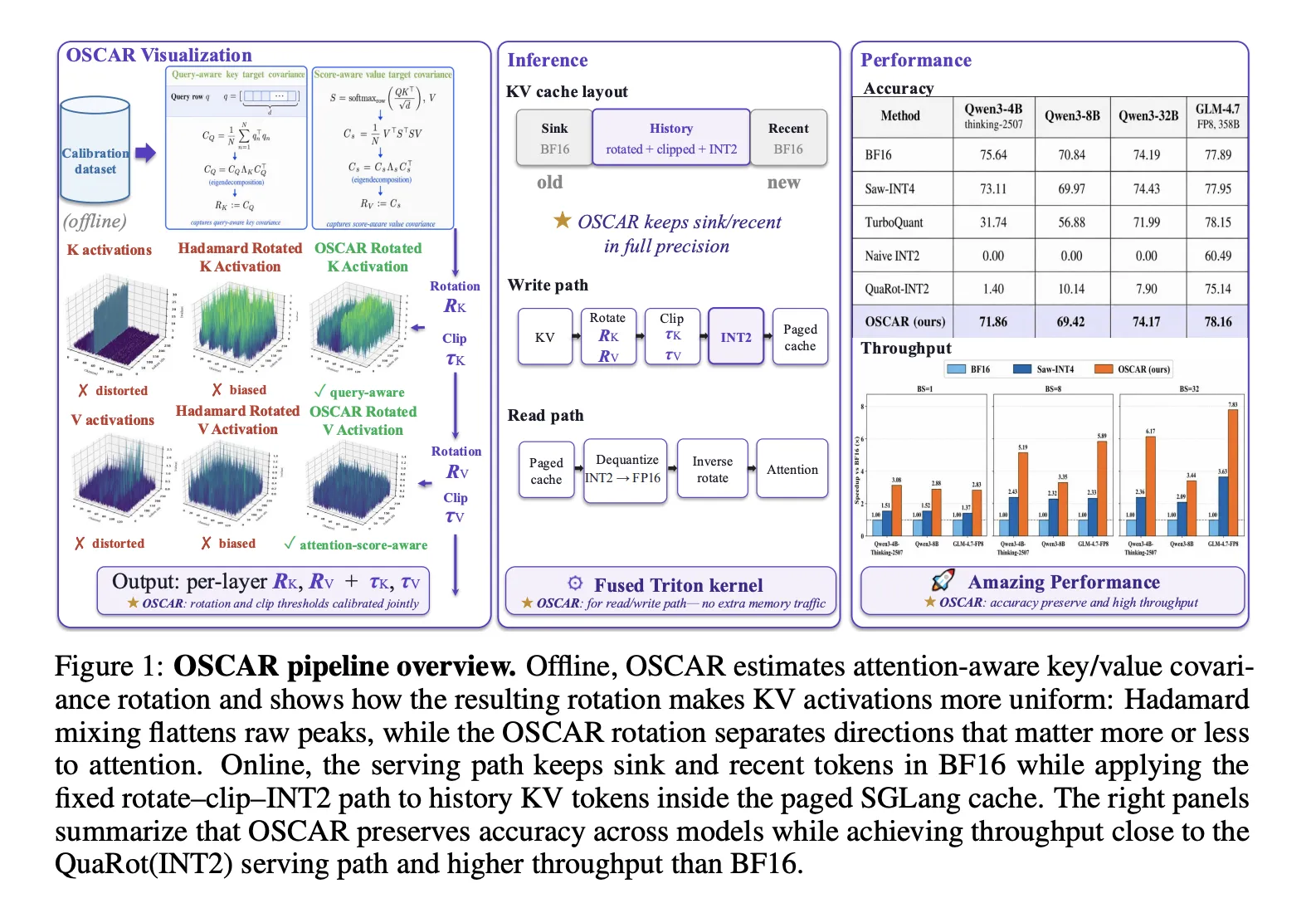
Кэш KV является значительной статьёй затрат при обслуживании больших языковых моделей (LLM); его сжатие с помощью квантования на основе поворотов, реализованного в OSCAR, повышает эффективность при точности INT2. OSCAR вычисляет повороты на основе статистики внимания, чтобы уменьшить ошибки квантования, что позволяет улучшить качество внимания и повысить производительность модели.
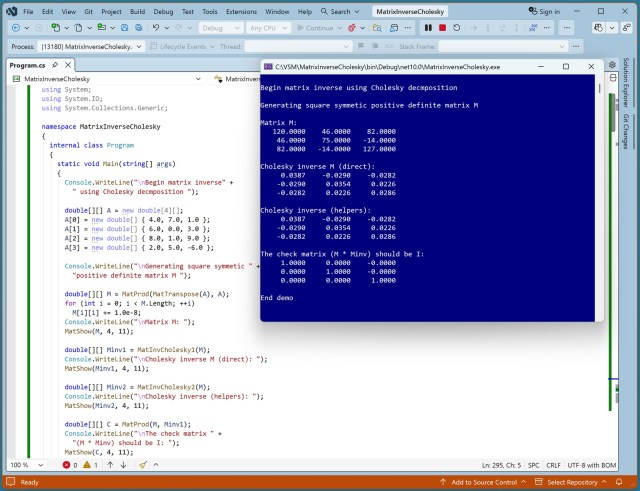
Разработка функции обратного матричного преобразования с использованием разложения Холески: более лаконичный код или более высокая эффективность. Анализ методов разработки программного обеспечения с использованием кода, сгенерированного ИИ, и дизайна персонажей в анимационных фильмах.
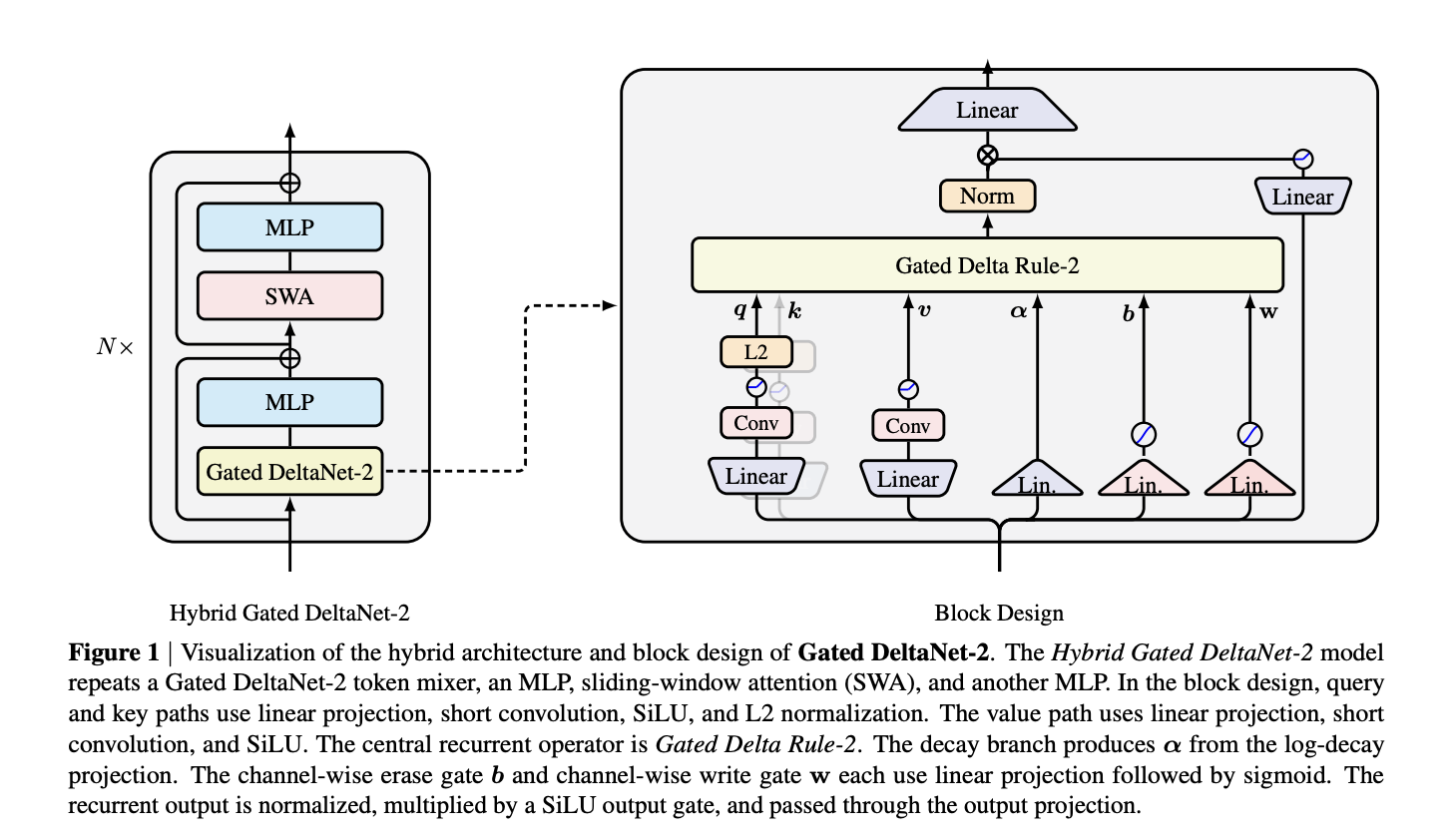
Компания NVIDIA представляет модель Gated DeltaNet-2 с линейным механизмом внимания, предназначенную для улучшения обработки данных в памяти. Модель оснащена двумя канальными гейтами и демонстрирует более высокую производительность по сравнению с предыдущими моделями в исследовательских тестах.