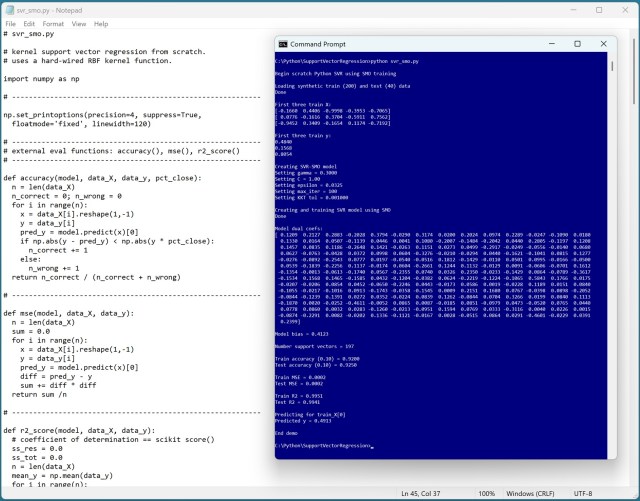
Автор демонстрирует реализацию ядра Support Vector Regression (SVR) с использованием языка Python, представляя пример работы с синтетическими данными и подчеркивая сложности реализации SVR по сравнению с Kernel Ridge Regression (KRR). Особое внимание уделяется алгоритму обучения SMO и его деталям, что позволяет продемонстрировать трудности и особенности реализации SVR.
В компании monday.com, благодаря использованию ИИ-ассистентов на платформе Amazon Bedrock, производительность работы отдела связей с общественностью увеличилась более чем вдвое. Это стало возможным благодаря масштабированному применению инструментов для автоматизации разработки программного обеспечения в существующей кодовой базе, созданной десять лет назад. Агенты monday.com полностью автономн...
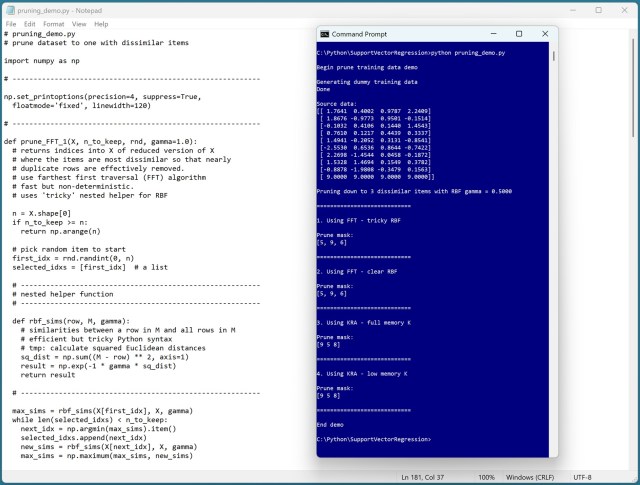
Уникальная задача сжатия обучающих данных с использованием метода сходства на основе радиальных базисных функций привела к созданию функций обрезки FFT и KRA в языке Python. Функция FFT оптимизирует процесс за счет приоритезации различий, а функция KRA ранжирует элементы на основе средней степени сходства для повышения понятности.

Димитри Берцекас, выдающийся профессор факультета электротехники и компьютерных наук Массачусетского технологического института, скончался в возрасте 83 лет. Он был известен своими новаторскими работами в области оптимизации и своим вкладом в подготовку будущих лидеров этой сферы.

Генеральный директор NVIDIA, Дженсен Хуанг, запустил мощную платформу искусственного интеллекта в Военно-морской последипломной школе, предоставив студентам и преподавателям доступ к вычислительным ресурсам для решения задач реального мира, таких как прогнозирование погоды и кибербезопасность. Сотрудничество с NPS направлено на обучение будущих лидеров в области технологий искусственного интелл...

Платформа NVIDIA Vera Rubin, представляющая собой масштабную инфраструктуру, наращивает объемы производства в партнерстве с компаниями, такими как CoreWeave и Microsoft Azure. Благодаря тесному сотрудничеству при разработке чипов и систем, создаются эффективные центры обработки данных для искусственного интеллекта, оснащенные специализированными сетевыми решениями, что позволяет сократить время...

Модели Amazon Nova 2 отлично справляются с задачами, требующими логического мышления. Технология Self-Distilled Reasoning повышает производительность без потери ранее полученных знаний.
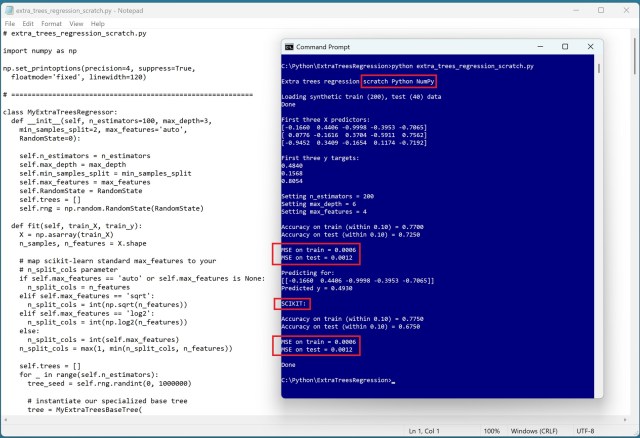
Метод регрессии "Extra Trees" использует случайные деревья решений для точного прогнозирования значений. Реализация этого метода с нуля может дать результаты, близкие к результатам, получаемым с помощью модуля scikit-learn.
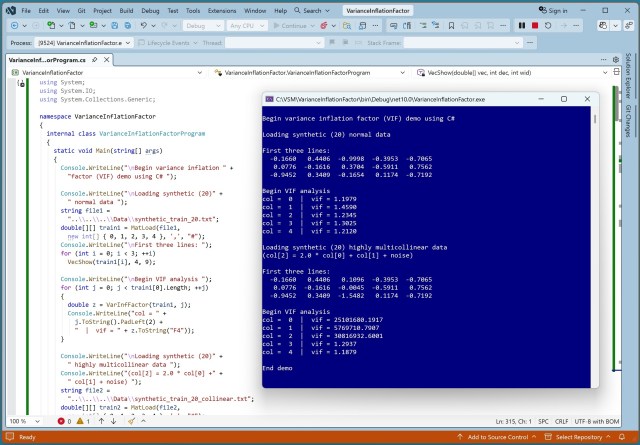
Многомерные данные для обучения влияют на интерпретируемость модели. Показатель VIF помогает выявить уровень корреляции. Для переноса демонстрационного кода с Python на C# потребовалось реализовать класс линейной регрессии и вспомогательные функции.

Разработчики теперь могут продлить срок службы своих устройств AWS DeepRacer, установив собственные операционные системы с помощью нового загрузчика, что позволит экспериментировать с современными дистрибутивами Linux и пользовательскими программными стеками. Загрузчик предоставляет разработчикам возможность самостоятельной настройки, позволяя устанавливать сторонние дистрибутивы и носители инф...

На конференции SIGGRAPH компания NVIDIA демонстрирует последние достижения в области искусственного интеллекта, включая нейронный рендеринг, создание виртуальных миров и методы моделирования. Руководители NVIDIA рассказывают о том, как эти технологии революционизируют создание и использование цифровых миров в различных отраслях промышленности.
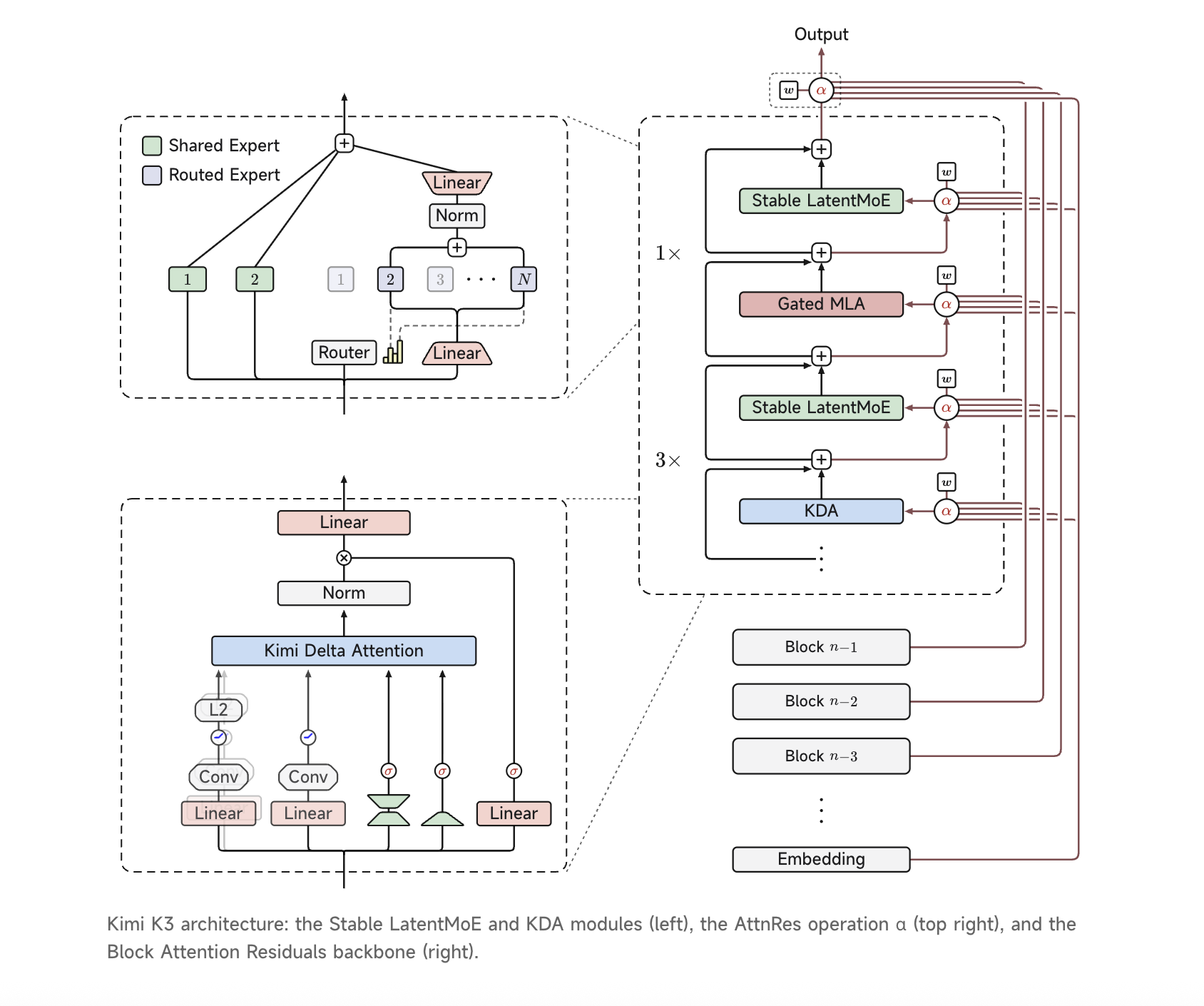
Компания Moonshot AI представила модель Kimi K3, обладающую 2,8 триллиона параметров и уникальными характеристиками. Модель K3 превосходит предыдущие модели по размеру и эффективности, но уступает проприетарным моделям по производительности.
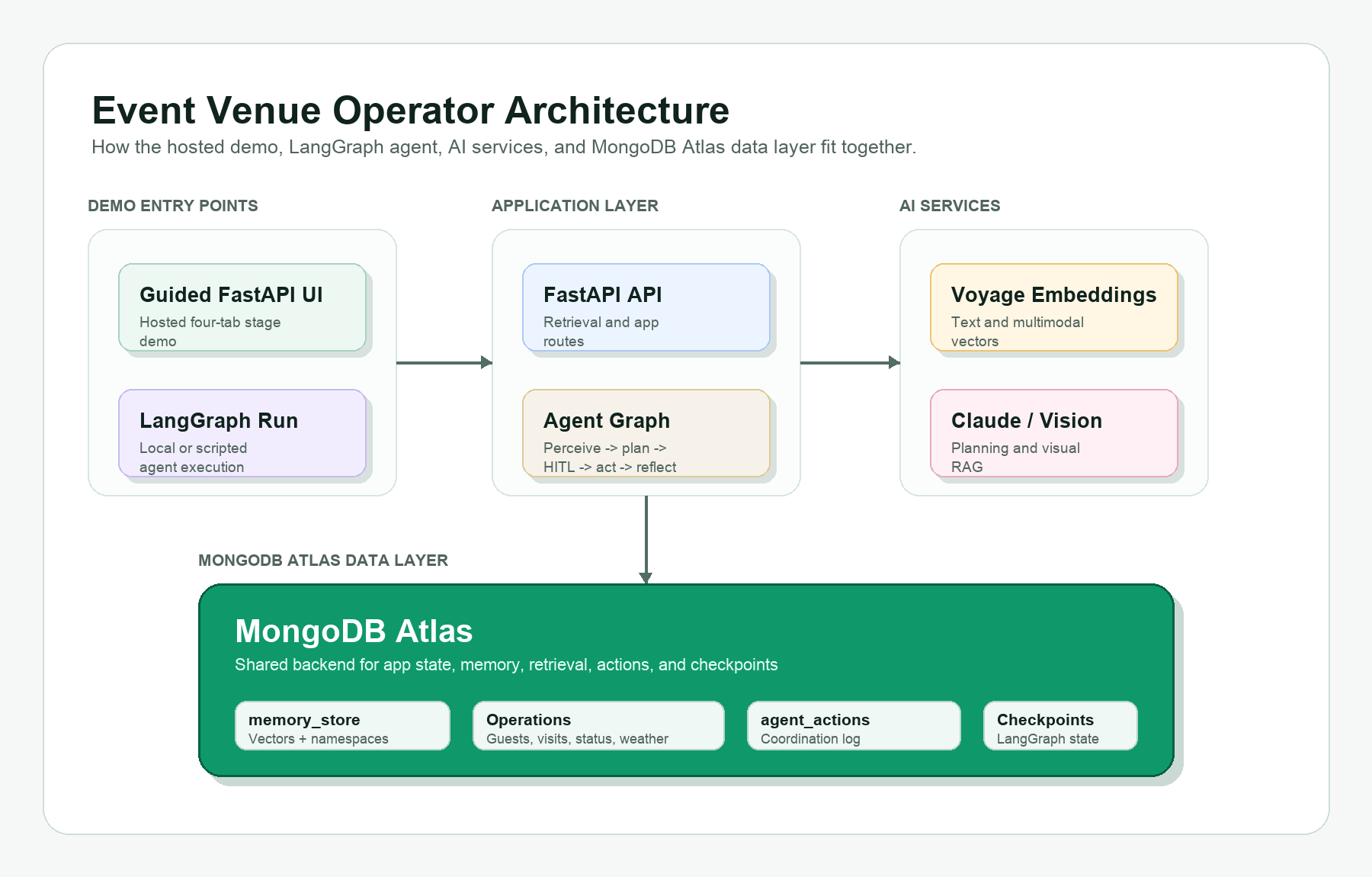
Создайте демонстрационную версию системы управления площадками для проведения мероприятий, используя MongoDB Atlas, векторные представления данных от Voyage AI и LangGraph. Изучите сложности организации престижного теннисного турнира с высокими ожиданиями зрителей и потенциальными рисками, связанными с погодными условиями.

Разносторонние интересы Бейли Фланиган привели ее от медицины к музыке и исследованиям в области вычислительной демократии. Ее путь, охватывающий различные дисциплины в ведущих учебных заведениях, формирует ее новаторский подход к осмысленному участию в демократических процессах.
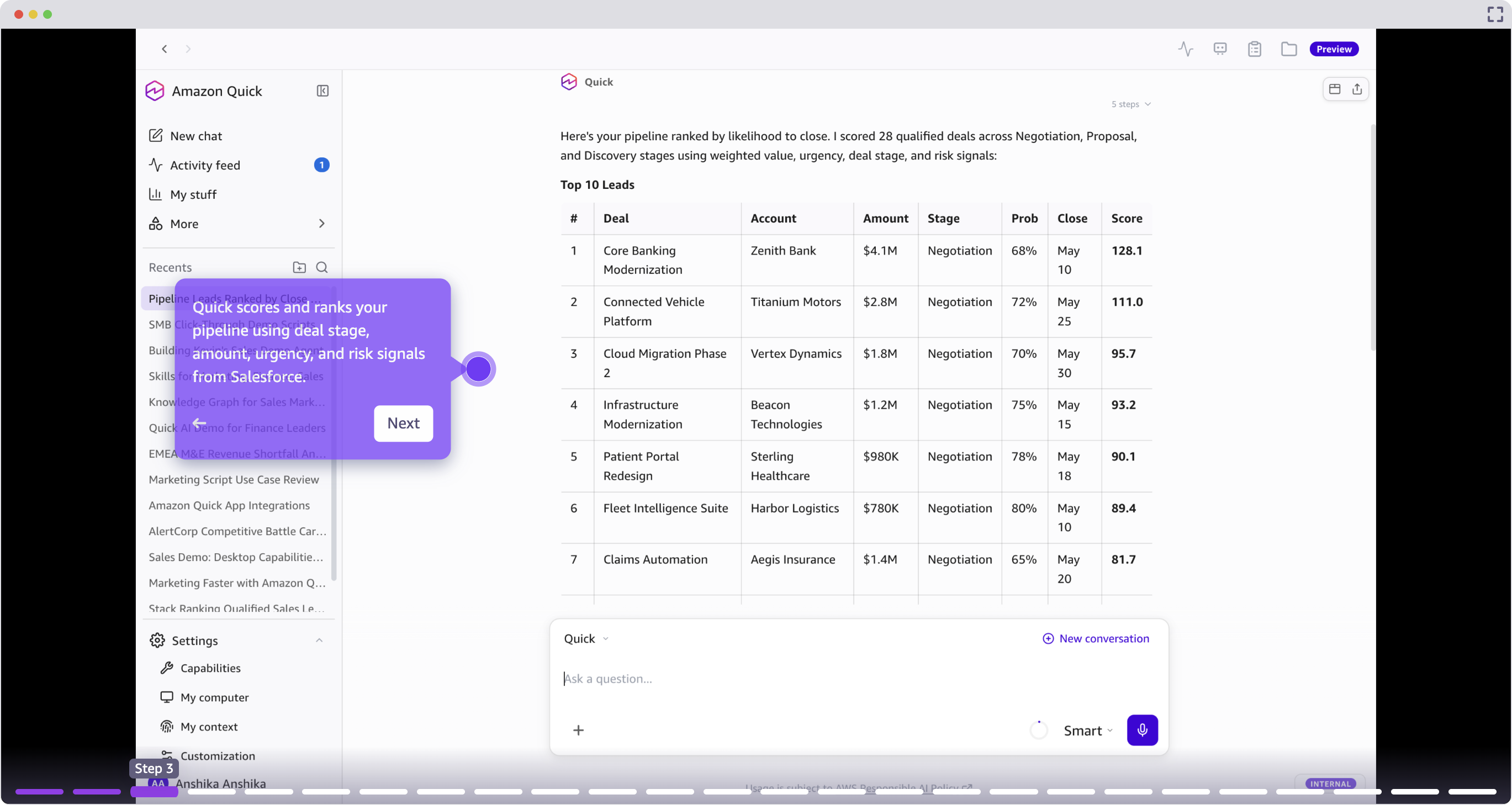
Amazon Quick – это ИИ-ассистент, который помогает менеджерам по продажам тратить больше времени на продажи и меньше – на административные задачи. Такие компании, как 3M и AWS, уже используют Quick для определения наиболее перспективных клиентов и ускорения заключения сделок.