
Пространственно разрешенная транскриптомика (SRT) преобразует геномику путем картирования экспрессии генов в точных тканевых точках. В недавнем обзоре Nature Communications Гуанао Ян классифицирует пространственно изменяющиеся гены (SVG) на три категории, что помогает понять организацию тканей и клеточные взаимодействия.
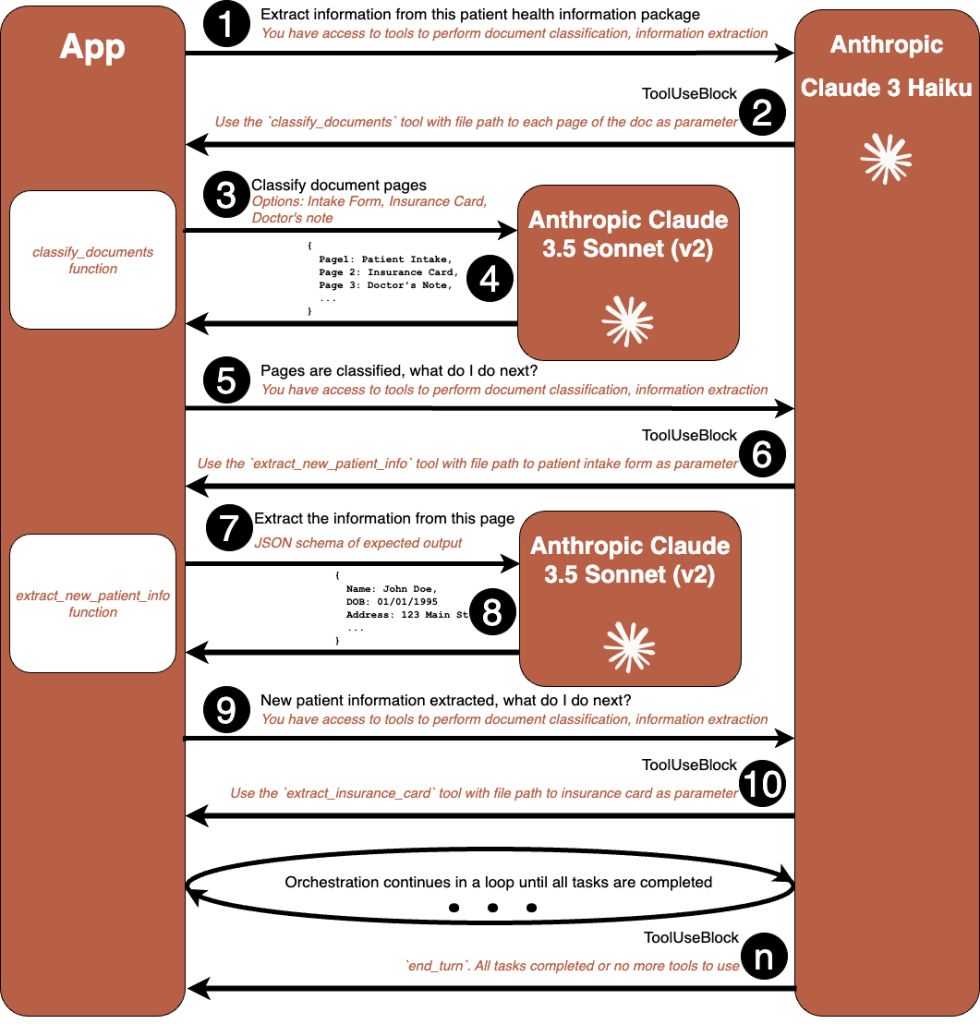
Генеративный ИИ преобразует автоматизацию предприятий: Amazon Bedrock FM решает сложные задачи обработки документов. Модели Claude 3 Haiku и Sonnet (v2) компании Anthropic отлично справляются с рассуждениями и визуальной обработкой, оптимизируя эффективность рабочего процесса и точность данных.

Анализ данных позволяет выявить вкусовые различия между европейскими и американскими M&M's, что ставит под сомнение восприятие качества шоколада. Международные дебаты о вкусе M&M вдохновили на лабораторный эксперимент, чтобы определить, действительно ли европейское производство улучшает вкус.

Графические процессоры NVIDIA GeForce RTX 5070 Ti с передовыми тензорными ядрами и DLSS 4 улучшают рабочие процессы создания генеративного AI-контента и редактирования видео. МОДЕЛИ FLUX. 1 [dev] модели, оптимизированные для FP4, теперь эффективно работают на графических процессорах серии GeForce RTX 50, революционно повышая скорость генерации изображений.
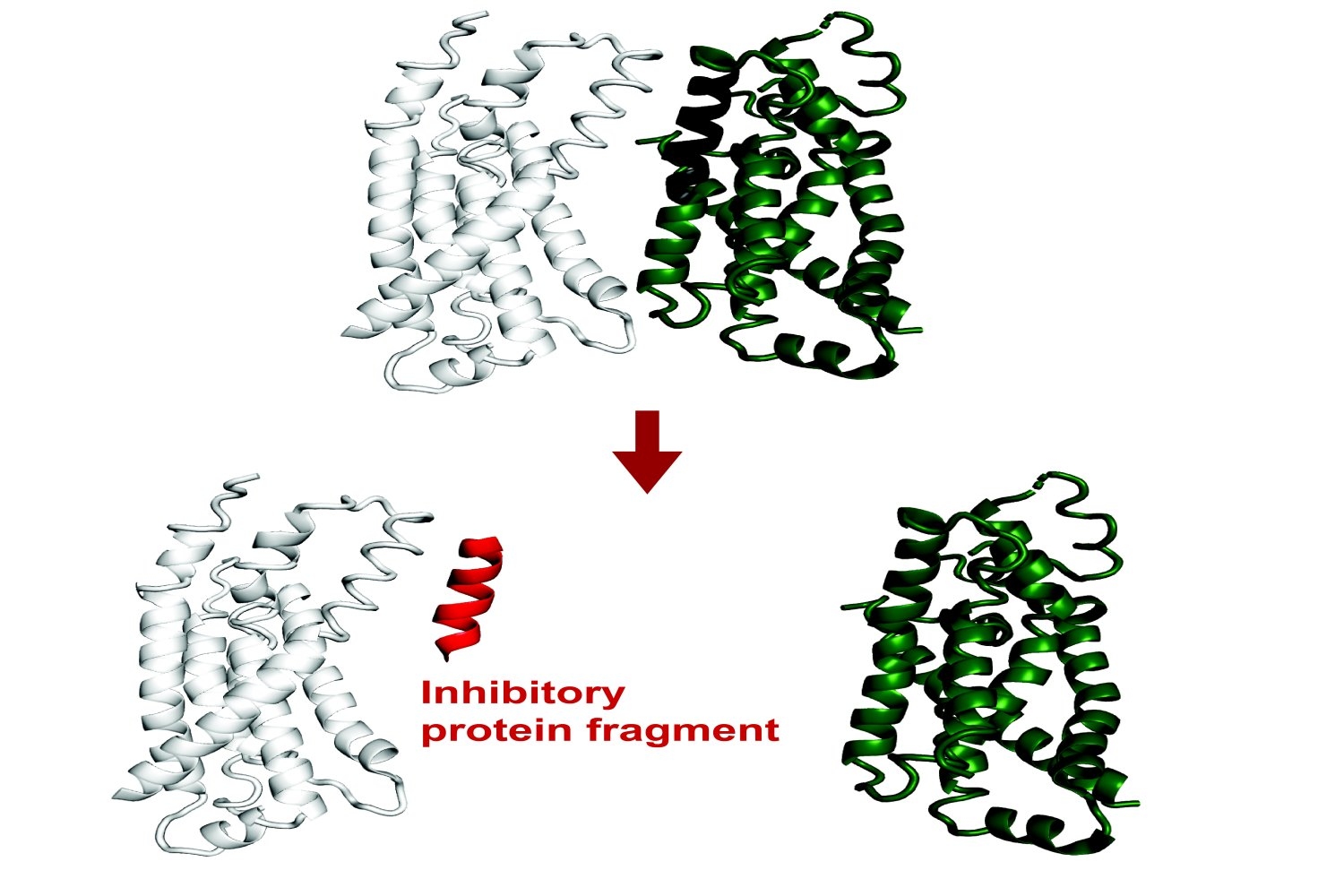
Новый метод предсказывает фрагменты белков, которые будут ингибировать полноразмерные белки в E. coli. FragFold использует модель искусственного интеллекта AlphaFold для точных предсказаний, что потенциально позволяет создавать генетически кодируемые ингибиторы для любых белков.
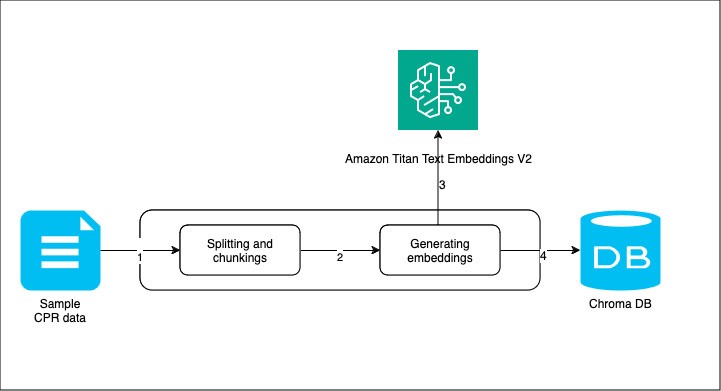
Приложения, работающие с данными, выигрывают от использования генеративных моделей ИИ, таких как большие языковые модели (LLM), которые могут создавать синтетические данные в различных форматах и сферах деятельности. ABC Bank использует усовершенствованный RAG с LLM для оценки риска контрагента по внебиржевым деривативам, решая проблемы, связанные с необъективностью данных и точностью модели.

NVIDIA в сотрудничестве с организациями ASL разработала Signs - интерактивную платформу для изучения ASL и приложений ИИ. Пользователи могут получить доступ к проверенной библиотеке знаков ASL и внести свой вклад в растущий массив данных для создания доступных технологий.
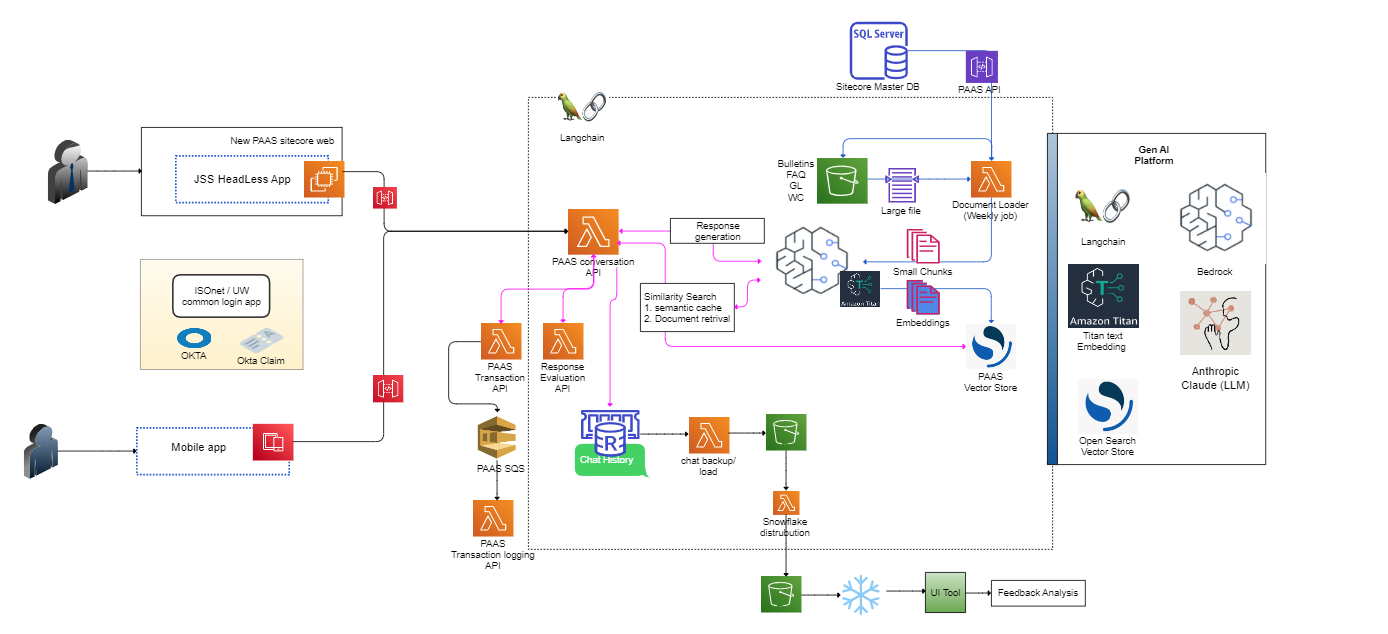
Компания Verisk использует генеративный искусственный интеллект для повышения эффективности операций и прибыльности страховых клиентов. ИИ PAAS обеспечивает интерактивную поддержку аудиторов премий, повышая эффективность и улучшая процесс принятия решений.

GeForce NOW празднует 5-летие с облачной библиотекой Avowed от Obsidian Entertainment. Погрузитесь в захватывающий фэнтезийный мир Avowed с игровыми платформами на базе GeForce RTX в облаке.

Среды Anaconda могут занимать много места в хранилище, но такие методы, как очистка кэша и архивирование, помогут вернуть память. Узнайте, как уменьшить занимаемое пространство с помощью этих советов по управлению памятью.
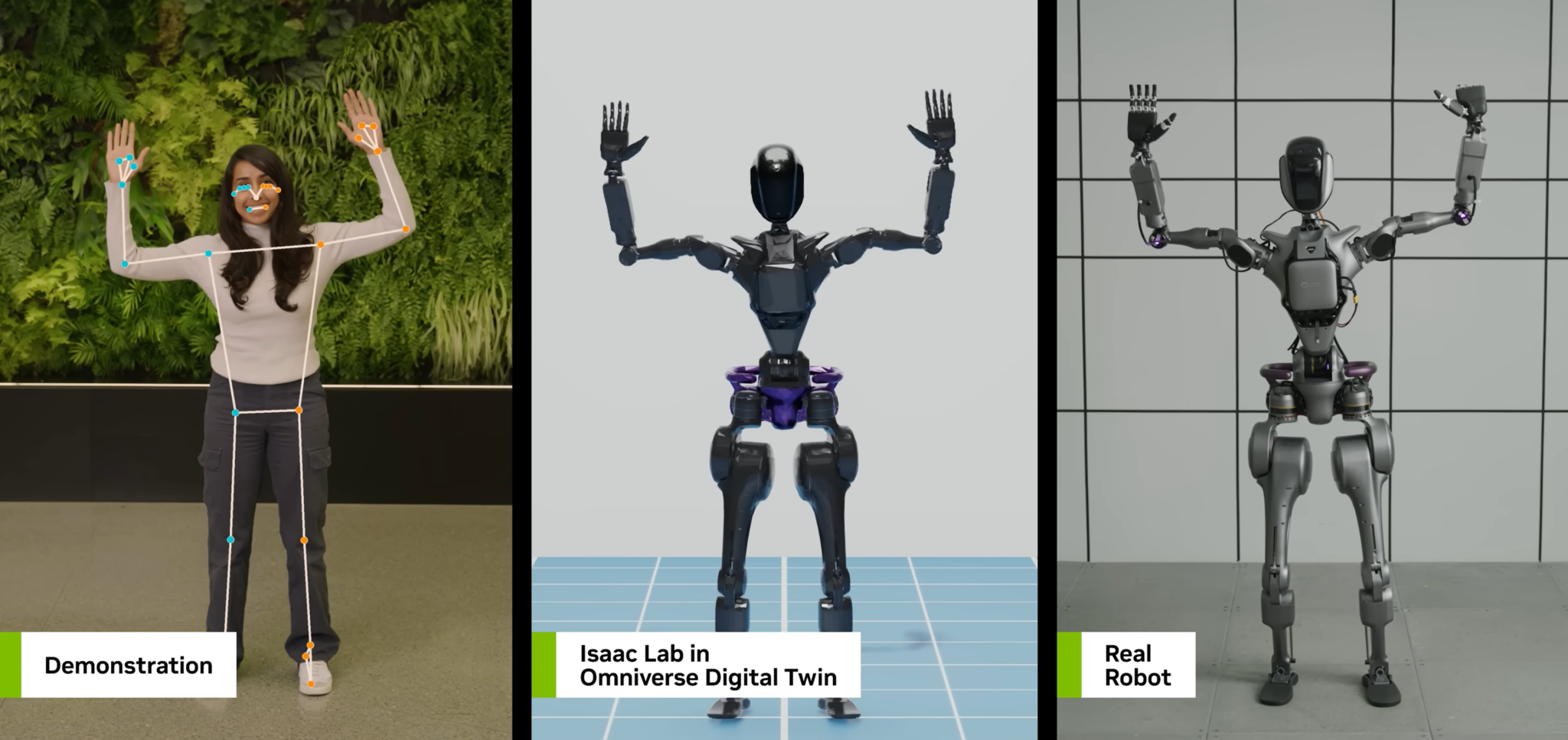
Гуманоидные роботы, обученные на NVIDIA Isaac GR00T с помощью синтетических данных OpenUSD, совершают революцию в робототехнике. NVIDIA Omniverse упрощает обучение благодаря масштабной генерации данных о движениях и обучению на основе симуляции.

LLM Codegen расширяет возможности шаблонов API Node.js с помощью автоматической генерации кода модулей на основе текстовых описаний, включая E2E-тесты и миграции баз данных. Генерируемый код следует принципам вертикальной архитектуры, обеспечивая чистый и поддерживаемый код с валидными E2E-тестами.
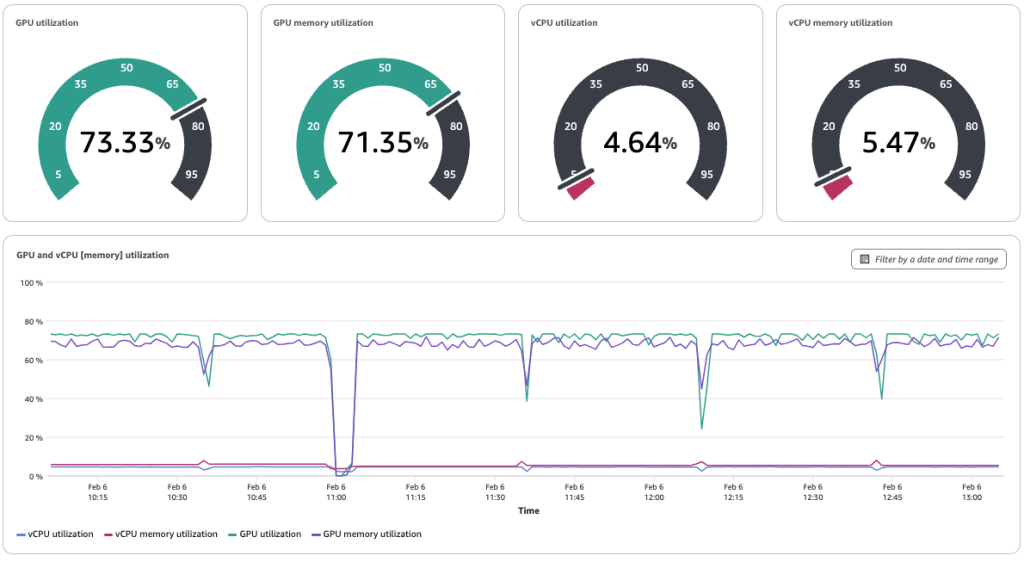
Amazon запустила SageMaker HyperPod на Amazon EKS, позволяющий эффективно разрабатывать генеративный ИИ с помощью общих ускоренных вычислений. Администраторы могут управлять распределением задач, определять приоритеты проектов и оптимизировать использование ресурсов для ускорения инноваций.

Ученые, изучающие данные, могут извлечь выгоду из использования контейнеров для обеспечения стабильности и масштабируемости моделей машинного обучения и конвейеров данных. Контейнеры более гибкие, чем виртуальные машины, они совместно используют ОС хоста для более быстрого, переносимого и эффективного использования ресурсов.

Мультимодальность в искусственном интеллекте преобразует пользовательский опыт. BLIP-2 от Salesforce улучшает визуально-языковое согласование для улучшения задач рассуждения.