
GenAI позволяет легко интегрировать объекты реального мира в генерируемые искусственным интеллектом 4D-сцены для создания видео. Прогресс в области генеративного ИИ быстро развивается, особенно в текстовых задачах, в то время как создание видео все еще находится на ранних стадиях, но ежемесячно улучшается.
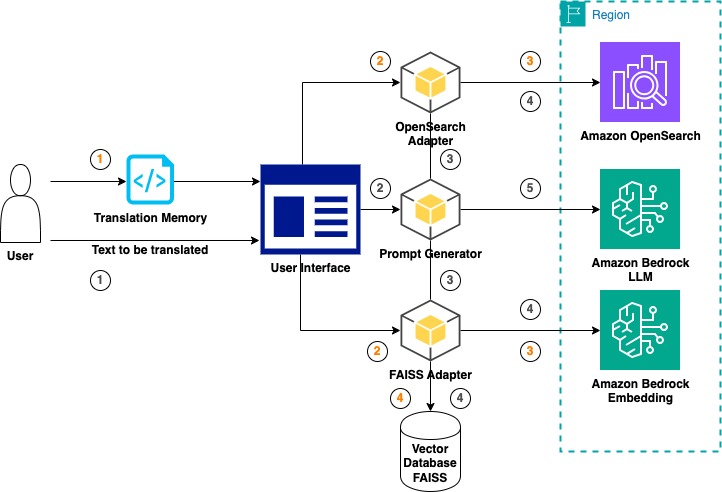
Большие языковые модели (БЯМ) отлично подходят для машинного перевода, улавливая контекст и культурные нюансы лучше, чем нейронные модели, например Amazon Translate. LLM обеспечивают потенциальную экономию средств и ускоряют выполнение проектов, но при этом сталкиваются с такими проблемами, как непостоянное качество и риск возникновения галлюцинаций.

Поддельные аудиозаписи представляют угрозу для демократии: писательница Джорджина Финдли обнаруживает, что ее голос используется в ультраправой пропаганде. Последствия фальшивых аудиозаписей далеко идущие и тревожные.
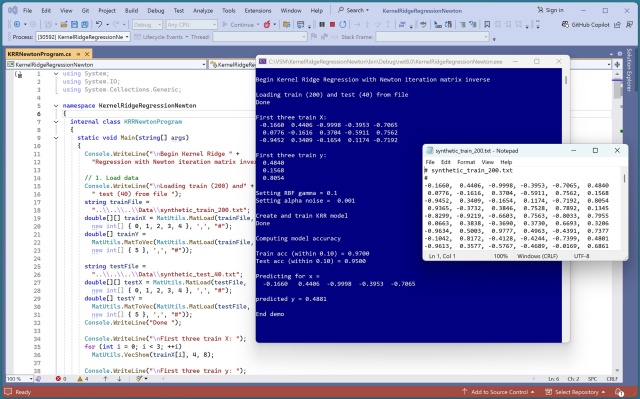
К распространенным методам регрессии относятся линейная регрессия, k-nearest neighbors и kernel ridge. Регрессия по гребню ядра эффективна для сложных нелинейных данных, но может плохо масштабироваться на большие наборы данных. Переработанная реализация KRR с итерациями Ньютона показала многообещающие результаты в демонстрационном примере на синтетических данных.

Зеленый берет использовал платформу ИИ для поиска информации о взрывчатке в Афганистане. Нападавший на кибергрузовик Tesla использовал генеративный ИИ для планирования атаки.

Компания Faculty AI, известная своим сотрудничеством с NHS и правительством Великобритании, также участвует в разработке ИИ для военных беспилотников. У консалтинговой компании есть опыт развертывания моделей ИИ на БПЛА, что вызывает опасения по поводу его двойной роли в гражданском и оборонном секторах.
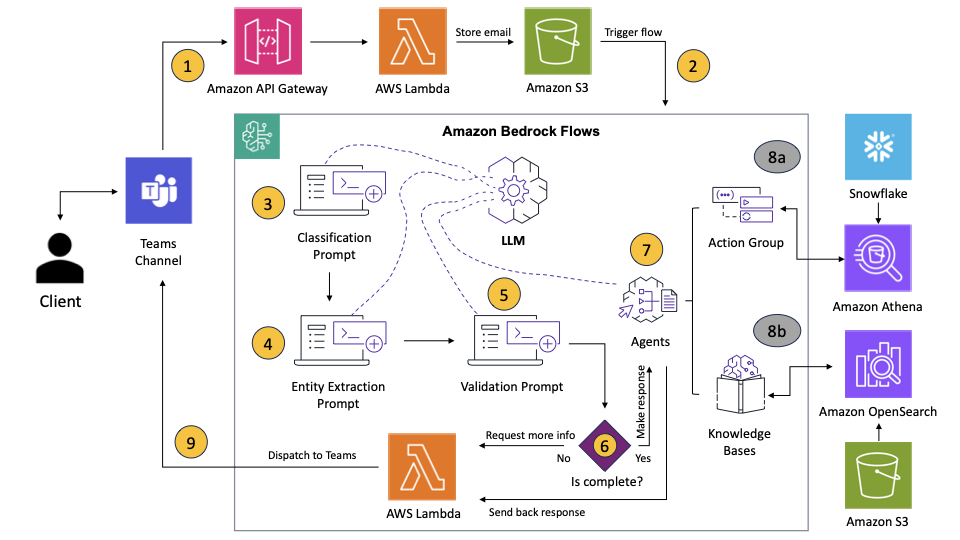
Компания Parameta Solutions использовала Amazon Bedrock Flows для автоматизации операций по обслуживанию клиентов, сократив время решения проблем с недель до нескольких дней. Эта трансформация позволила клиентам получить исчерпывающую информацию об отрасли и повысить эффективность рабочего процесса.
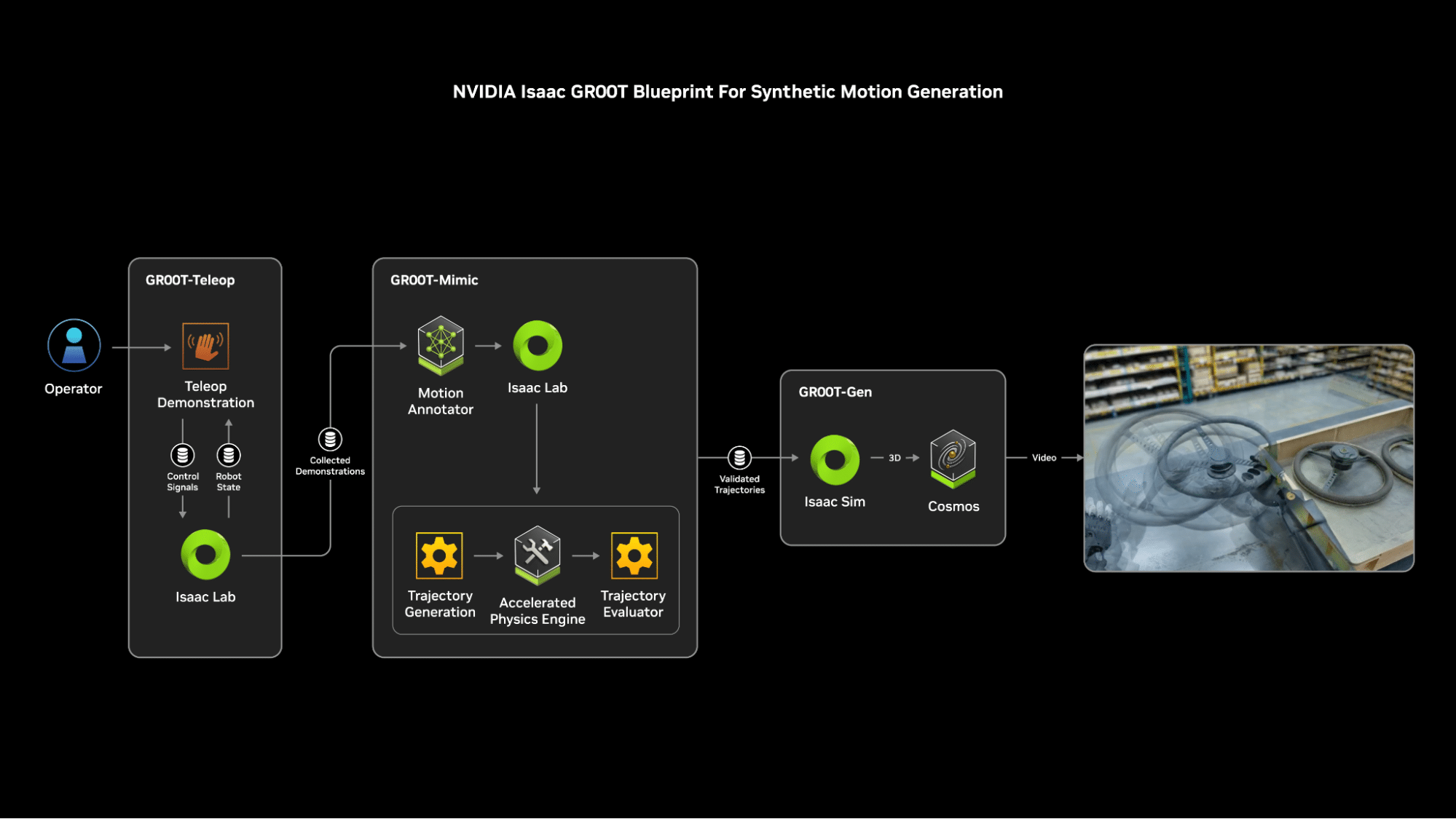
NVIDIA Isaac GR00T Blueprint ускоряет разработку гуманоидных роботов с помощью синтетических данных движения. Платформа Cosmos сокращает разрыв между симуляцией и реальностью для инноваций в области физического ИИ.

По словам генерального директора OpenAI Сэма Альтмана, агенты искусственного интеллекта могут изменить бизнес, поскольку виртуальные сотрудники пополнят рабочие штаты. Первые агенты искусственного интеллекта могут начать работать на организации уже в этом году, обеспечивая возврат значительных инвестиций в технологию.

NVIDIA Media2 использует ИИ для преобразования создания и доставки контента в медиаиндустрии, оставаясь на передовой благодаря таким технологиям, как NVIDIA Holoscan и архитектура Blackwell. NVIDIA AI Enterprise предлагает ряд микросервисов для расширения возможностей ИИ в рабочих процессах медиакомпаний.
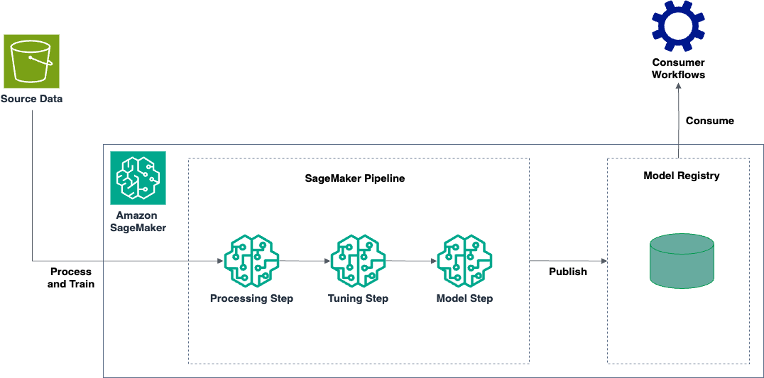
Автоматизируйте обнаружение аномалий на основе журналов с помощью Amazon SageMaker. Используйте настройку гиперпараметров и конвейеры SageMaker для эффективного построения моделей.
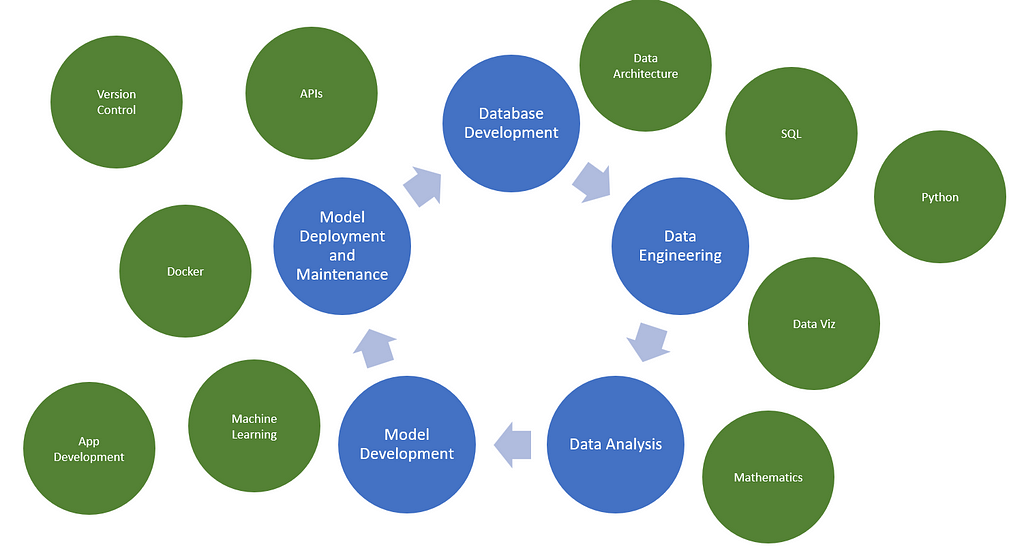
Роли специалистов по работе с данными расширяются и включают в себя навыки развертывания и эксплуатации ML, а также разработки моделей. Узнайте, как развертывать модели ML с помощью FastAPI и Docker для продакшена API.

Система искусственного интеллекта может предложить идеальную молодежную перспективу с определенными качествами игрока, желаемыми футбольными менеджерами, что потенциально может повысить эффективность команды. Технологи утверждают, что менеджеры могут пожелать игроков с такими чертами, как агрессивность Эрлинга Хааланда или самообладание Джуда Беллингема, что превращает систему в спортивную лам...

ИИ-персонажи Meta, в том числе «гордая чернокожая мама-педик», вызвали вирусные дискуссии, прежде чем были удалены. Несмотря на предыдущие удаления, компания планирует ввести больше профилей ИИ-персонажей.

Основные изменения в этике ИИ в 2024 году включают прорыв в интерпретируемости LLM от Anthropic, разработку ИИ, ориентированного на человека, и новые законы об ИИ, такие как закон ЕС об ИИ и законы Калифорнии, направленные на глубокие подделки и дезинформацию. Акцент на объяснимом ИИ и расширении прав и возможностей человека, а также эвристика для оценки законодательства в области ИИ являются ...