
Министр технологий Питер Кайл стремится сделать Великобританию лидером в области ИИ, уравновесив экономический рост с вопросами безопасности в Интернете. Убедить гигантов Кремниевой долины поддержать революцию ИИ в условиях политической напряженности - непростая задача для лейбористского правительства.

Регуляризация высокоразмерных пространств с различными коэффициентами для каждой переменной с помощью аппроксимированной Лапласом байесовской оптимизации в логистической регрессии. Сравнение с сеточным поиском для оптимального выбора коэффициентов регуляризации в примере бинарной классификации.

Авторы, в том числе Сара Сильверман, обвиняют генерального директора Meta Марка Цукерберга в том, что он одобрил использование пиратских наборов данных книг для обучения искусственного интеллекта. Внутренние коммуникации свидетельствуют о том, что одобрение было получено, несмотря на предупреждения внутри компании.
Аналитика данных может помочь компаниям в создании устойчивых стратегий за счет согласования различных целей между отделами. Один из примеров иллюстрирует, как аналитические модели поддерживают «зеленые» инициативы при разработке экономически эффективных и экологичных сетей цепочек поставок.
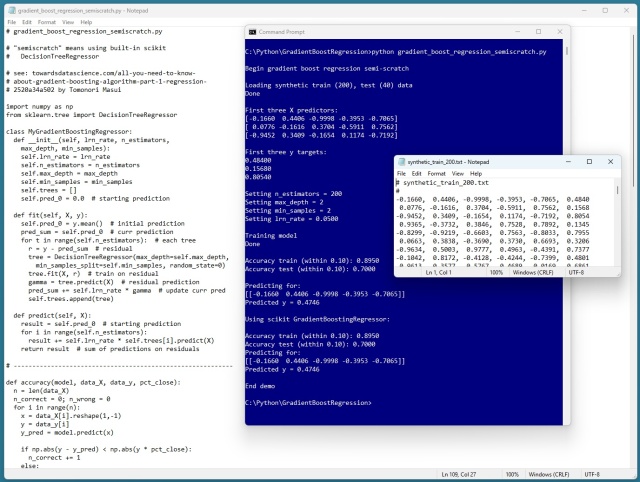
Gradient boosting regression (GBR) использует деревья решений для предсказания значений. Демонстрация на Python демонстрирует точность GBR в предсказании синтетических данных, совпадающих с результатами из библиотеки scikit. XGBoost и LightGBM - популярные библиотеки GBR для энтузиастов машинного обучения.

Оценка модели выходит за рамки точности при калибровке модели. Узнайте, как оценить надежность прогнозов и доверительные оценки вероятности. Калибровка гарантирует, что модели отражают истинную вероятность правильных прогнозов, что очень важно для реальных приложений.

Deep Instinct предлагает DSX, передовое решение для кибербезопасности, использующее глубокое обучение и генеративный искусственный интеллект для защиты от вредоносных программ и программ-вымогателей в режиме реального времени. Инструмент DIANNA на базе Amazon Bedrock расширяет возможности SOC-команд, обеспечивая быстрый анализ известных и неизвестных угроз и решая ключевые задачи в условиях ра...

ИИ-профили Meta не обладают самосознанием, что вызывает этические опасения. Билль о правах ИИ, разработанный Белым домом, требует прозрачности во взаимодействии ИИ.

Исследователи MIT CSAIL создали систему искусственного интеллекта, которая имитирует человеческие вокальные звуки без обучения, вдохновляясь когнитивной наукой. Этот прорыв может привести к созданию более интуитивных интерфейсов звукового дизайна, реалистичных персонажей ИИ и инновационных методов изучения языка.

Элон Маск предлагает использовать самообучающиеся синтетические данные, поскольку ИИ-компании сталкиваются с нехваткой данных. Некоторые предостерегают от потенциального «краха модели».

Статья демонстрирует Random Forest Regression и Bagging Regression на C# для Microsoft Visual Studio Magazine. В ней объясняется, как ансамбль деревьев решений позволяет избежать чрезмерной подгонки и улучшить прогнозы.

Профессор Джон Макдермид подчеркивает необходимость того, чтобы регулирующие органы имели возможность отзывать модели ИИ и оценивать опережающие индикаторы риска, чтобы снять опасения Джеффри Хинтона по поводу опасностей ИИ. Совместные исследования и разработка ИИ для обеспечения безопасности имеют решающее значение для снижения рисков, выходя за рамки тестирования «красных команд» после разра...
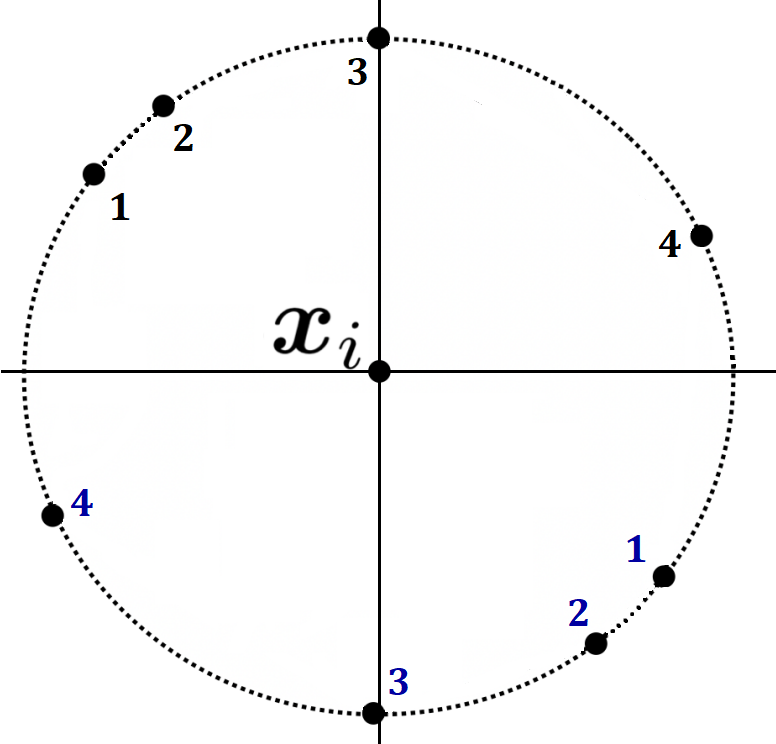
Сложность стратегического VC-измерения (SVC) возрастает с увеличением функций затрат по экземплярам, доводя их до бесконечности. Линейные классификаторы с функциями затрат могут отличаться от канонических аналогов, что влияет на сложность классификации.
Байесовское A/B-тестирование бросает вызов традиционным методам, используя предварительные убеждения для динамической оценки вероятности. Автор делится идеями из академического и профессионального опыта, подчеркивая преимущества и недостатки байесовского тестирования.

Подросток из Сиднея попал под следствие за использование искусственного интеллекта для создания и распространения поддельных изображений студенток. Задействована полиция.