
Генеративний штучний інтелект швидко впроваджується в різних галузях, від охорони здоров'я до освіти, але виникає занепокоєння через тенденцію великих мовних моделей генерувати неточну інформацію. Критики ставлять під сумнів справжню цінність цієї технології для економіки Великої Британії через постійну ваду LLM, яка полягає в тому, що вони все вигадують.

Чат-бот ChatGPT AI протестований для консультацій з особистих фінансів людьми-експертами. Чи може АІ ефективно управляти нашими грошима?

Міністр технологій Великобританії Пітер Кайл закликав британських працівників впроваджувати штучний інтелект зараз, інакше вони ризикують відстати, адже для подолання розриву між поколіннями у використанні технологій потрібно лише 2,5 години тренінгу.
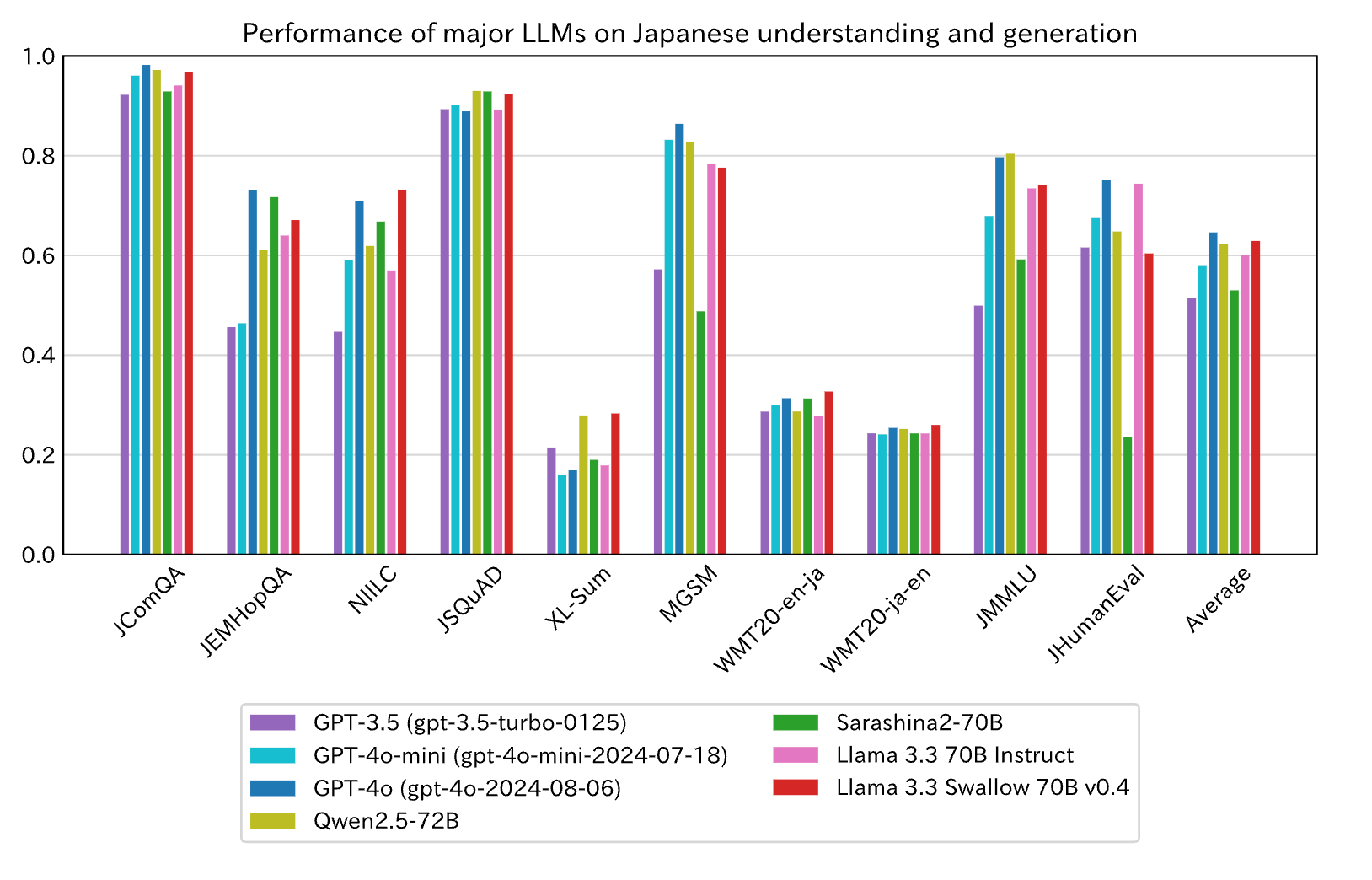
Казукі Фудзіі очолив розробку Llama 3.3 Swallow, 70-мільярдної LLM з чудовими можливостями японської мови. Модель перевершує GPT-4o-mini, демонструючи оптимізовану навчальну інфраструктуру та методологію.
Торстен Клеппе (https://github.com/grensen) створює приголомшливі інтерактивні візуалізації даних, які захоплюють глядачів. Його останні дослідження демонструють красу та інтерактивність візуалізацій машинного навчання.
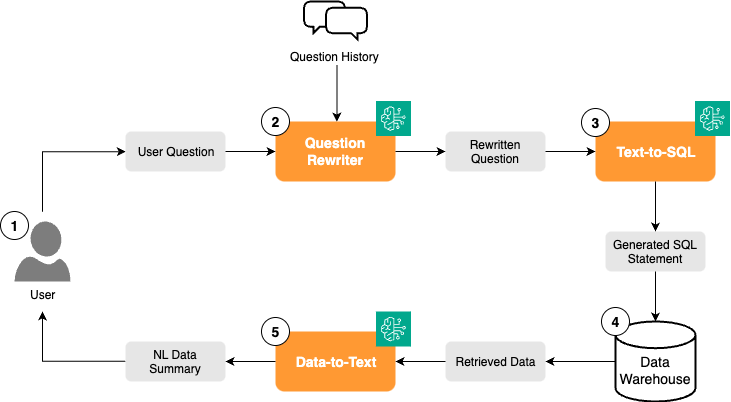
VideoAmp співпрацював з AWS GenAIIC для розробки прототипу чат-бота NL Analytics, який покращує медіа-аналітику за допомогою штучного інтелекту. Шлях VideoAmp до штучного інтелекту привів до точного таргетингу, кращих моделей атрибуції та збільшення рентабельності інвестицій, позиціонуючи їх як лідерів у сфері реклами на основі даних.
Стаття демонструє лінійну регресію опорних векторів за допомогою C# з навчанням рою частинок для оцінки точності прогнозування моделі. Демонстрація розкриває проблеми прогнозування нелінійних даних, підкреслюючи важливість спеціалізованих алгоритмів оптимізації, таких як рій частинок.

Генеративний штучний інтелект змінює цифр Велика модель SD3.5 з квантуванням до FP8, що зменшує обсяг VRAM на 40% для швидшої та ефективнішої генерації зображень.

Дослідники Массачусетського технологічного інституту розробили революційний апаратний прискорювач ШІ для обробки бездротових сигналів, який працює зі швидкістю світла, пропонуючи у 100 разів швидшу та енергоефективнішу альтернативу цифровим прискорювачам ШІ. Ця технологія може революціонізувати майбутні бездротові додатки 6G та уможливити ШІ-висновки в режимі реального часу для різних високопр...

Інструменти штучного інтелекту, такі як ChatGPT, швидко розвиваються у сфері вищої освіти у Великій Британії. Недавнє дослідження підкреслює значний вплив генеративного ШІ на навчання студентів.

Аспірант Массачусетського технологічного інституту Алекс Качкін розробляє метод фізичного нанесення цифрової реставрації на оригінальні картини, що прискорює процес у 66 разів. Його інноваційний підхід дозволяє вести чіткий цифровий облік реставраційних змін, потенційно повертаючи більше пошкоджених творів мистецтва до уваги громадськості.

Тім Ейрс підкреслює, що Австралії необхідно скористатися перевагами штучного інтелекту, щоб уникнути залежності від ланцюгів поставок інших країн. Лейбористський уряд планує регулювати технологію штучного інтелекту, одночасно заохочуючи дискусії про вплив автоматизації на робочі місця.

Штучний інтелект трансформує роздрібну торгівлю та індустрію товарів повсякденного попиту: такі світові бренди, як L'Oréal, LVMH і Nestlé, використовують ШІ-агентів і 3D-двійників для покращення життєвого циклу продукції та маркетингових стратегій. Nestlé співпрацює з NVIDIA та Accenture для створення цифрових двійників на базі АІ для електронної комерції, а LVMH використовує NVIDIA Omniverse ...
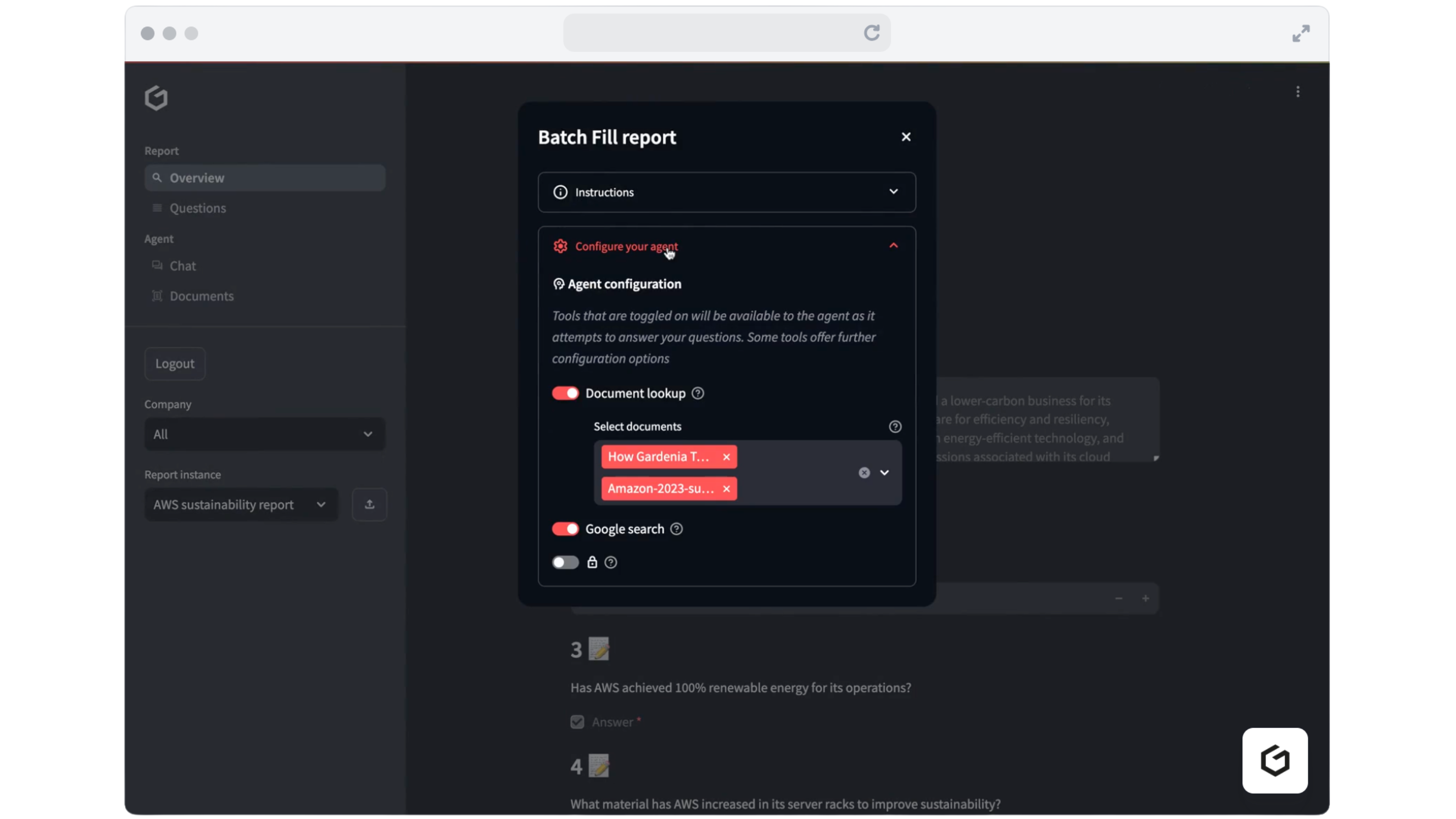
Генеративний ШІ допомагає компаніям полегшити тягар звітності ESG, скорочуючи час звітування на 75%. Gardenia Technologies співпрацює з AWS для розробки Report GenAI, використовуючи новітні моделі штучного інтелекту на Amazon Bedrock для автоматизації рутинних завдань і підвищення ефективності звітності зі сталого розвитку.
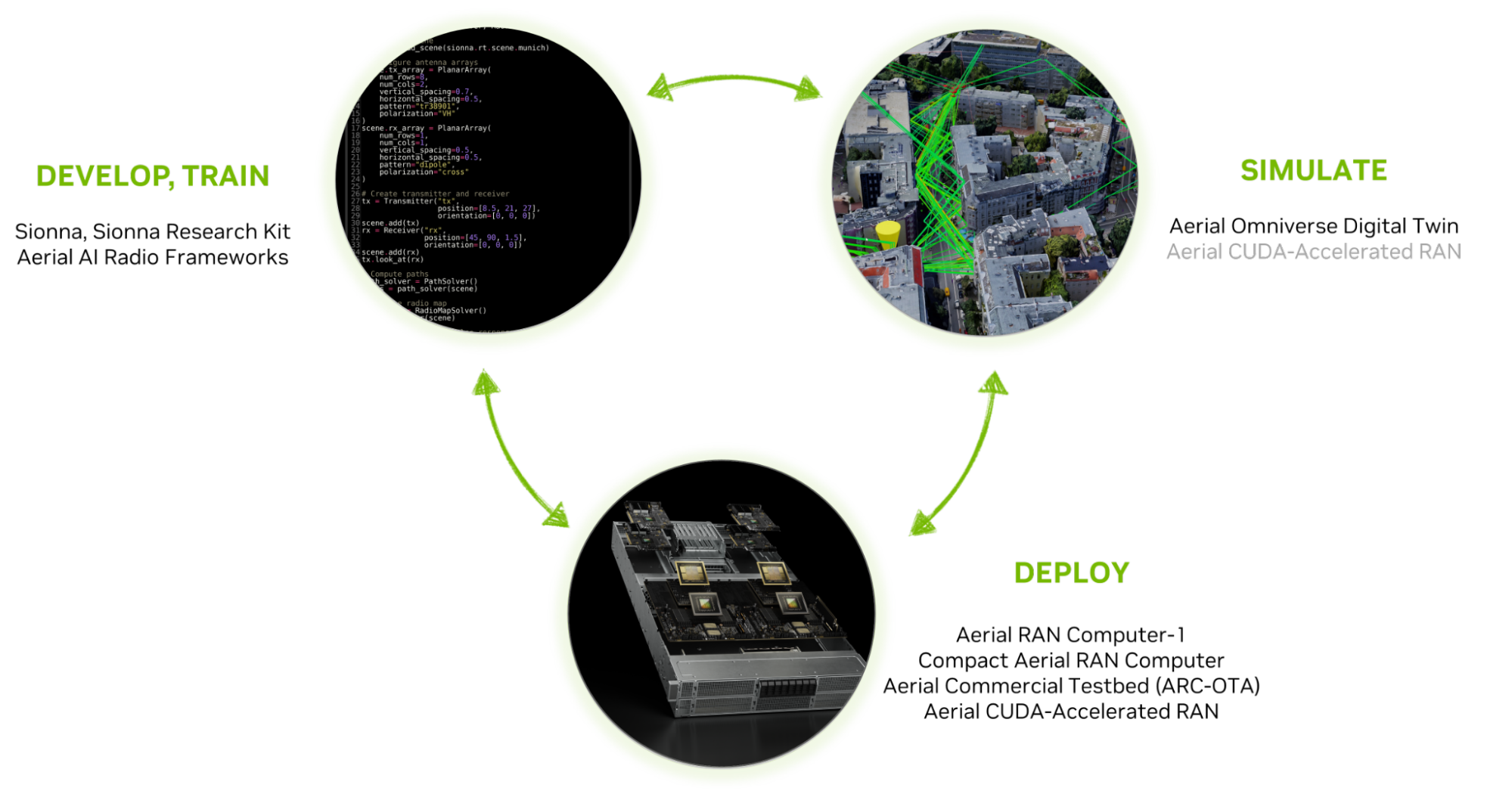
Європейські телекомунікаційні компанії використовують NVIDIA для розробки 6G, інтегруючи ШІ для інновацій та сталого розвитку. Співпраця з урядом Великобританії та провідними університетами, цифровий двійник мережі реального часу у Фінляндії та партнерство з OAI у Франції підкреслюють передові досягнення в бездротових мережах на основі ШІ.