
Колишній член правління OpenAI Хелен Тонер попереджає про «поступове позбавлення ШІ можливостей» через підрив ринку праці генеративним ШІ. Орієнтація США на академічні дослідження та іноземних студентів розглядається як «великий подарунок» Китаю в конкурентній боротьбі зі штучним інтелектом.

Ofcom обмірковує проблеми зі штучним інтелектом в оцінці ризиків після звіту про автоматизацію перевірок Meta. Учасники кампанії наполягають на обмеженні використання ШІ в Meta для Facebook, Instagram, WhatsApp.

Британські міністри відкладають законопроект про регулювання ШІ щонайменше на рік через побоювання щодо безпеки та авторських прав. Міністр з питань технологій планує розробити комплексне законодавство для вирішення проблеми відсутності регулювання.
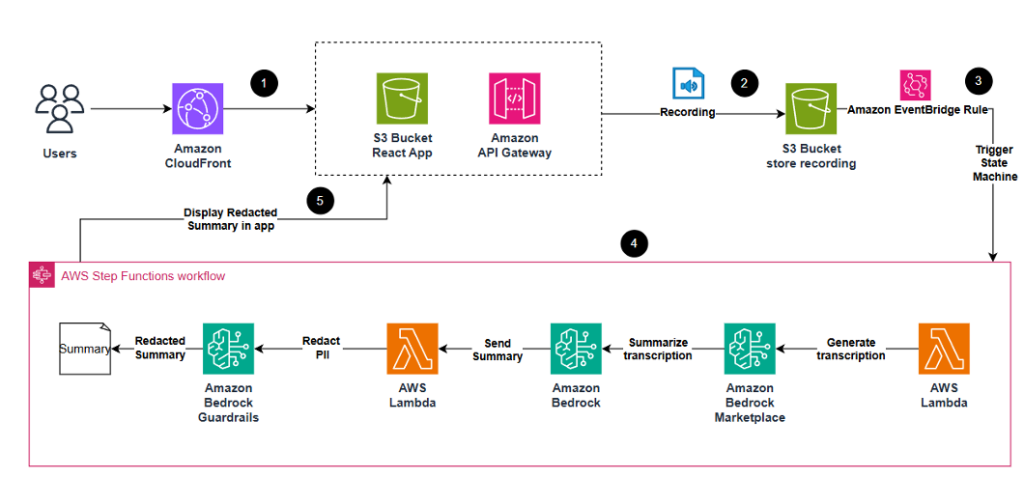
Автоматизовані рішення для штучного інтелекту, такі як Open AI Whisper Large V3 Turbo на Amazon Bedrock Marketplace, спрощують процеси транскрипції та редагування конфіденційних даних у записах. Інтеграція Amazon Bedrock з безсерверними технологіями забезпечує безперебійний робочий процес для масштабованої обробки контенту, гарантуючи дотримання нормативних вимог і захист даних.
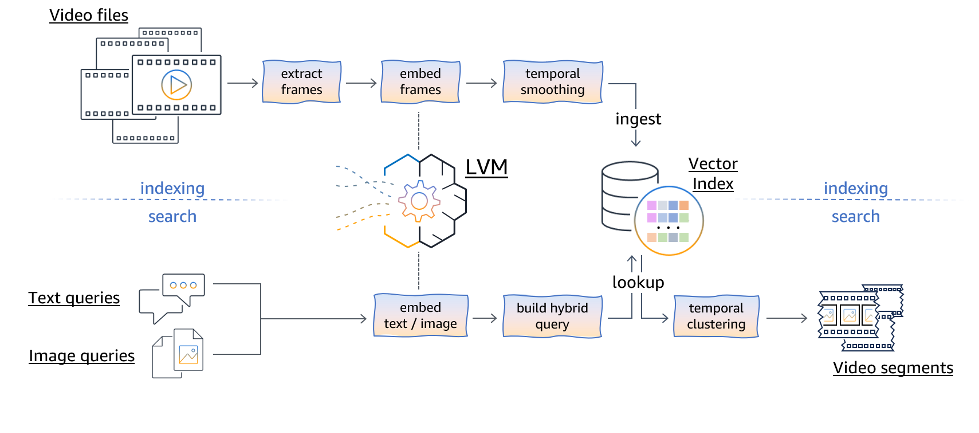
Семантичний пошук відео з використанням моделей машинного зору дозволяє користувачам шукати відеоконтент за допомогою запитів на природній мові, покращуючи виявлення та модерацію контенту. Великі моделі зору, такі як CLIP, дозволяють переносити дані з нульового кадру на різні завдання комп'ютерного зору, революціонізуючи ефективність відеопошуку.
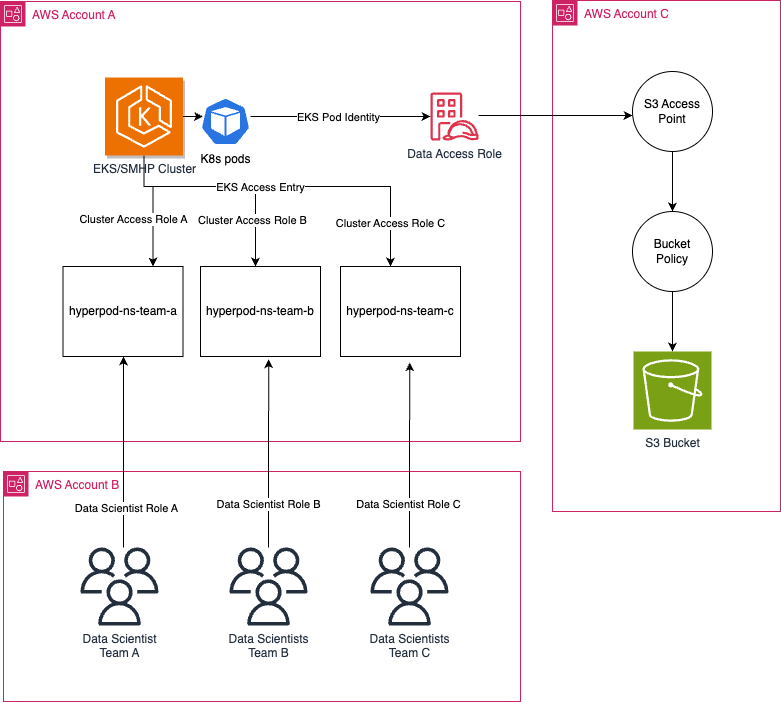
Графічні процесори є критично важливими та дорогими для генеративних робочих навантажень ШІ, що спонукає організації спільно використовувати високопродуктивну інфраструктуру графічних процесорів у декількох облікових записах AWS для кращого використання ресурсів та відстеження витрат. Керування завданнями SageMaker HyperPod забезпечує багатоакаунтний доступ, оптимізуючи розподіл ресурсів і вик...

Новий центр обробки даних в Елшемі, що в Лінкольнширі, викидатиме 850 000 тонн CO2 на рік, що перевищує викиди 5 аеропортів. Проект вартістю 10 мільярдів фунтів стерлінгів стимулює попит на ШІ у Великобританії.

Верховний суд закликає провідних юристів звернути увагу на зловживання штучним інтелектом у юридичній роботі. У двох нещодавніх справах було виявлено фальшиві цитати з прецедентного права, що викликає занепокоєння щодо контенту, створеного штучним інтелектом.
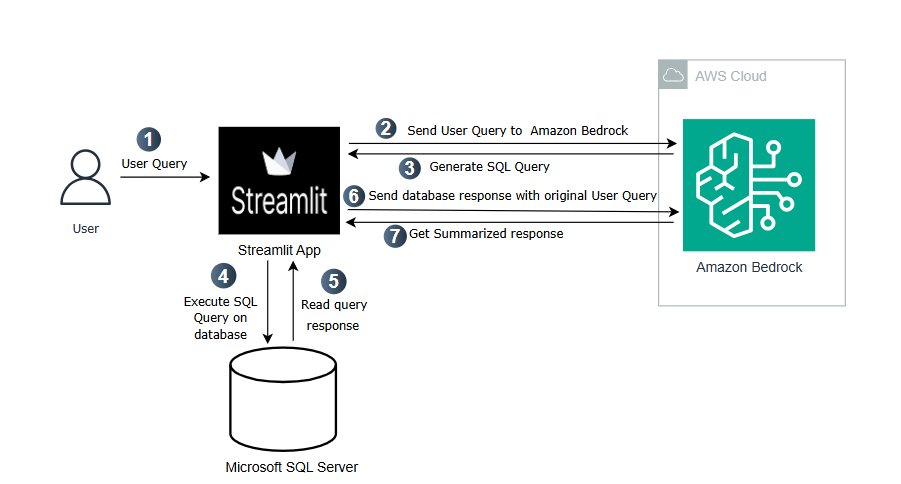
Text-to-SQL заповнює прогалину для нетехнічних користувачів, надаючи точні, специфічні для схеми запити для швидшого прийняття рішень. Amazon Nova з функцією Text-to-SQL перевершує інші підходи до штучного інтелекту завдяки точним і надійним результатам зі структурованих даних.

GeForce NOW пропонує літо ігор з 25 новими іграми, включаючи ексклюзивний доступ до гри Dune від Funcom: Пробудження. Скористайтеся літнім розпродажем зі знижкою 40%, щоб отримати максимальну продуктивність на будь-якому пристрої, а нові ігри з'являтимуться протягом усього червня.

Amazon створює програмне забезпечення для людиноподібних роботів, які виконуватимуть функції кур'єрів, що потенційно «вилізатимуть» з фургонів. Технологічний гігант вартістю $2 трлн створює в США «парк гуманоїдів» для тестування цих інноваційних роботів.
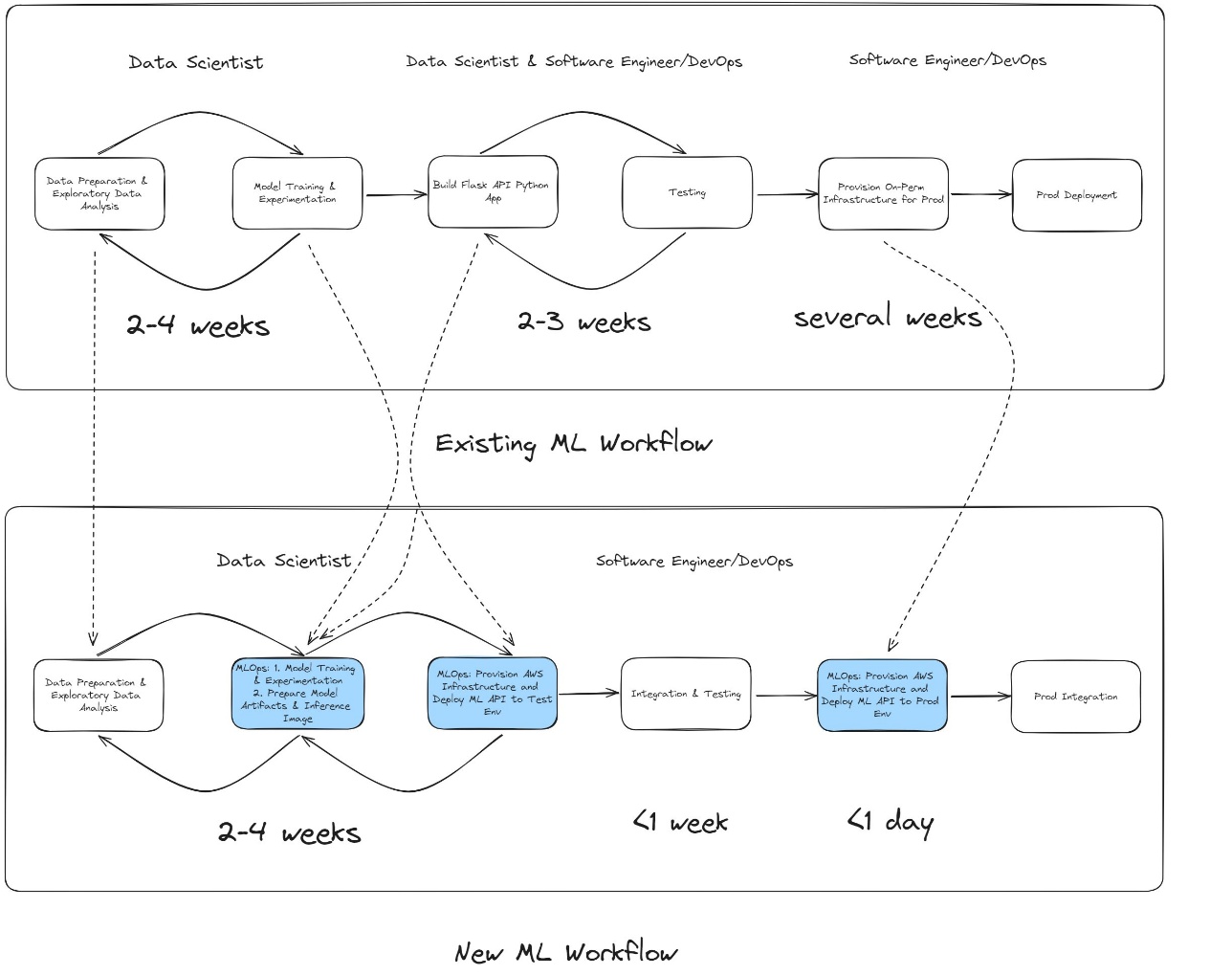
Радикально модернізовано технологію виявлення шахрайства за допомогою Amazon SageMaker, що підвищує точність та зменшує кількість хибних спрацьовувань. Локальні моделі ML стикаються з проблемами масштабування та обслуговування, що перешкоджає адаптації та інноваціям.

Англомовні країни, такі як Великобританія, США, Австралія та Канада, більше стурбовані питанням Глобальний розкол між «подивом і тривогою» щодо ШІ, схоже, пов'язаний з різним рівнем довіри до державного регулювання цієї технології.
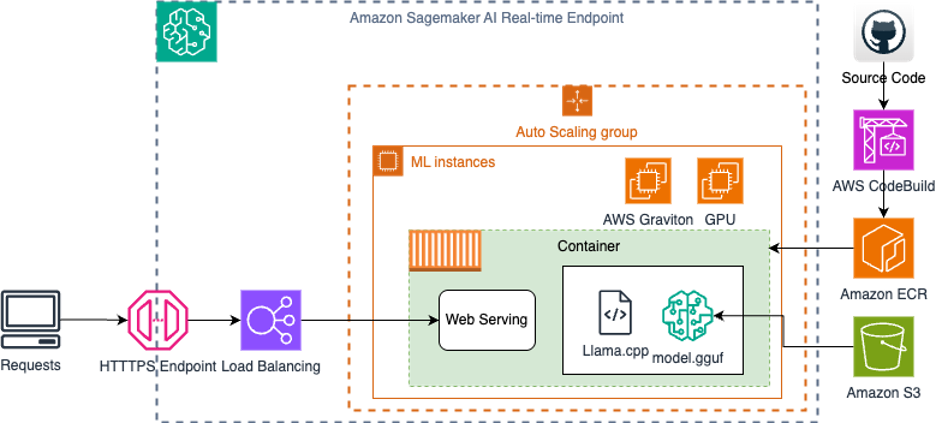
Amazon SageMaker AI пропонує керований сервіс для розгортання великих мовних моделей з декількома варіантами висновків. Використовуючи екземпляри AWS Graviton і попередньо квантовані моделі, організації можуть запускати економічно ефективні невеликі мовні моделі для практичних застосувань у реальному світі.
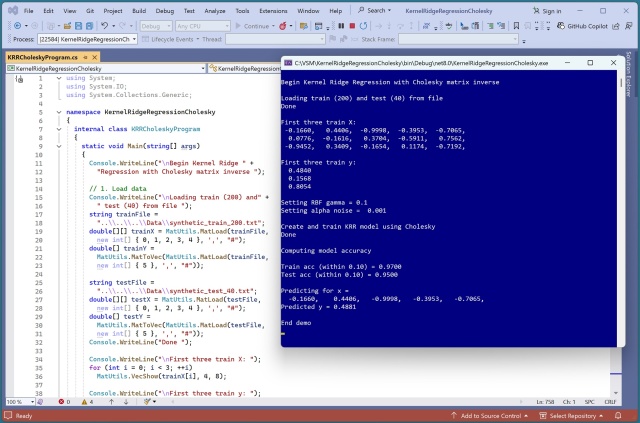
Метод ядрової регресії (kernel ridge regression, KRR) використовує ядерну функцію для обробки складних нелінійних даних, що забезпечує точні прогнози. Навчання моделі KRR передбачає визначення ваг за допомогою методів аналітичного розв'язання з використанням оберненої матриці.