
Зламані чат-боти становлять відчутну загрозу, генеруючи незаконну інформацію. Тенденція «джейлбрейкінгу» в обхід контролю безпеки.

Ruby і Python популярні для ШІ, але Ruby блищить у веб-додатках. SPA, такі як стек MERN, додають складності, впливаючи на користувацький досвід.

Штучний інтелект має потенціал у сфері психічного здоров'я, але залежність від технологій, а не від людської підтримки, створює ризики. Жінка звертається до ChatGPT за розрадою у важкі досвітні години.
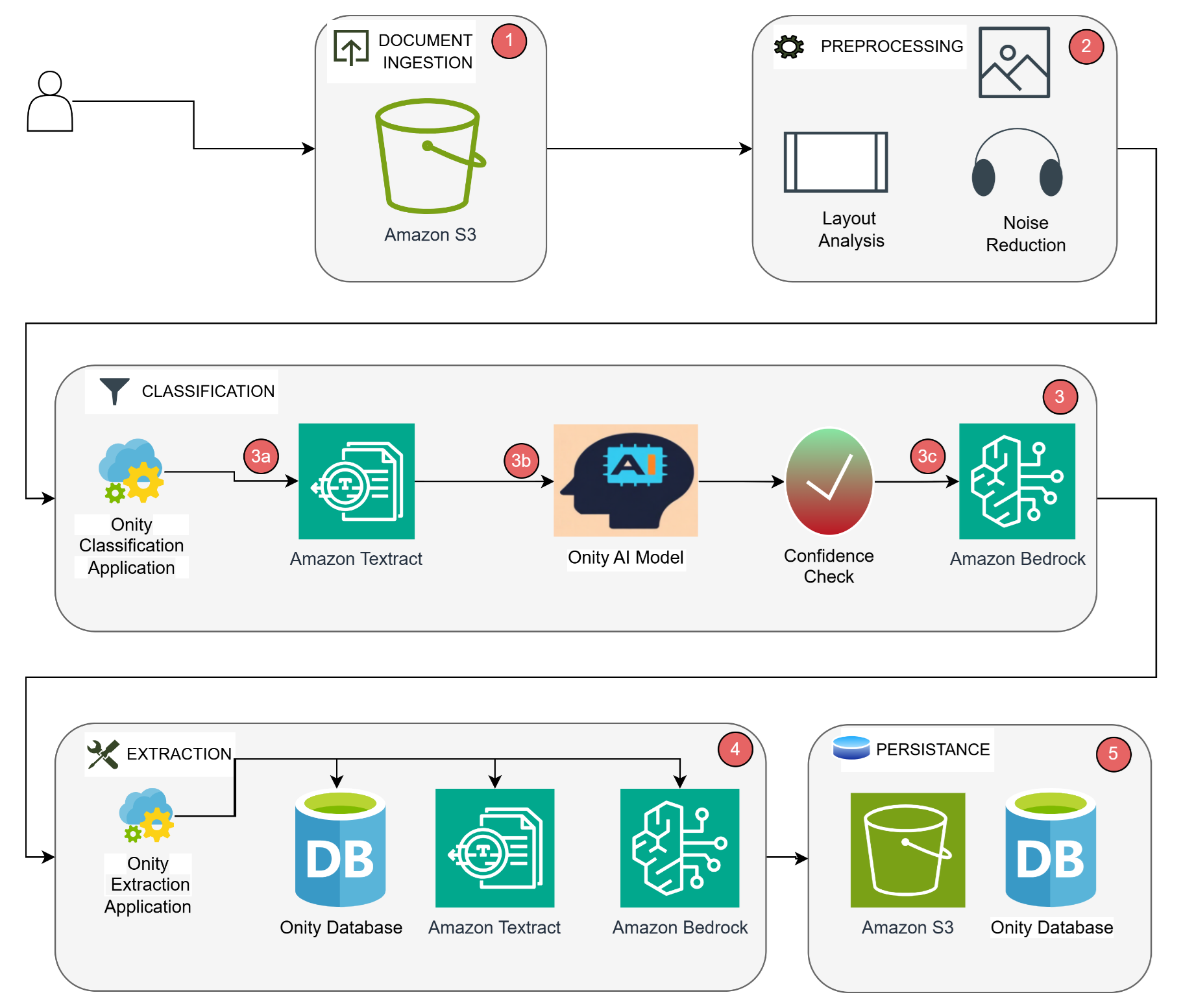
Onity Group використала Amazon Bedrock, щоб революціонізувати обробку документів в іпотечному обслуговуванні, скоротивши витрати на 50% і підвищивши точність на 20%. Традиційні моделі OCR та ML не справлялися з такими проблемами, як багатослівний текст, непослідовний почерк та виявлення печаток, що спонукало Onity перейти на більш досконале рішення.

Функція та ядро Єпанечникова є ключовими інструментами в аналізі даних для вимірювання подібності та оцінки щільності. Приклади ілюструють їх застосування в статистиці та машинному навчанні.

Силова гра генерального директора OpenAI призвела до звільнення та поновлення на посаді в битві за першість у сфері АІ. Стратегічні кроки Альтмана зміцнюють його позиції, що призводить до кадрових перестановок у мільярдній компанії.

Міністр оборони Джон Хілі планує надати пріоритет штучному інтелекту у збройних силах Великої Британії, прагнучи до інновацій в НАТО. Стратегічний оборонний огляд зосередиться на передових технологіях, щоб запобігти дорогим помилкам у закупівлях.

Дональд Трамп просуває американську технологічну галузь на Близькому Сході. 23andMe збирає дані, бот Ілона Маска створює історичні неточності.

На конференції Google представила вдосконалення штучного інтелекту для оновлення пошукової системи, представивши Gemini 2.5, що змінює спосіб доступу людей до інформації. Новий «режим штучного інтелекту» має на меті зробити пошукову взаємодію більш розмовною, нагадуючи поради експертів.

ChatGPT від OpenAI пропонує безкоштовну генерацію зображень, імітуючи відомих художників, таких як Хаяо Міядзакі, що викликає занепокоєння з приводу втрати мистецтвом зв'язку у світі, керованому ШІ. Поява творів мистецтва та романів, створених штучним інтелектом, становить загрозу для самої суті творчості та демократії в суспільстві.

Видання Chicago Sun-Times визнало, що список літнього читання, створений штучним інтелектом, містить фальшиві назви книг, що викликало негативну реакцію в соціальних мережах. Фрілансер використав ChatGPT для створення неіснуючих книжкових рекомендацій на 2025 рік, підкресливши небезпеку галюцинацій ШІ в журналістиці.

Функції бажаності в Data Science оптимізують численні метрики елегантно і просто, пояснюючи це на прикладі випікання хліба. Різні типи функцій бажаності дозволяють здійснювати цілісну оптимізацію в Python, забезпечуючи потужний інструмент для вирішення багатоцільових задач.
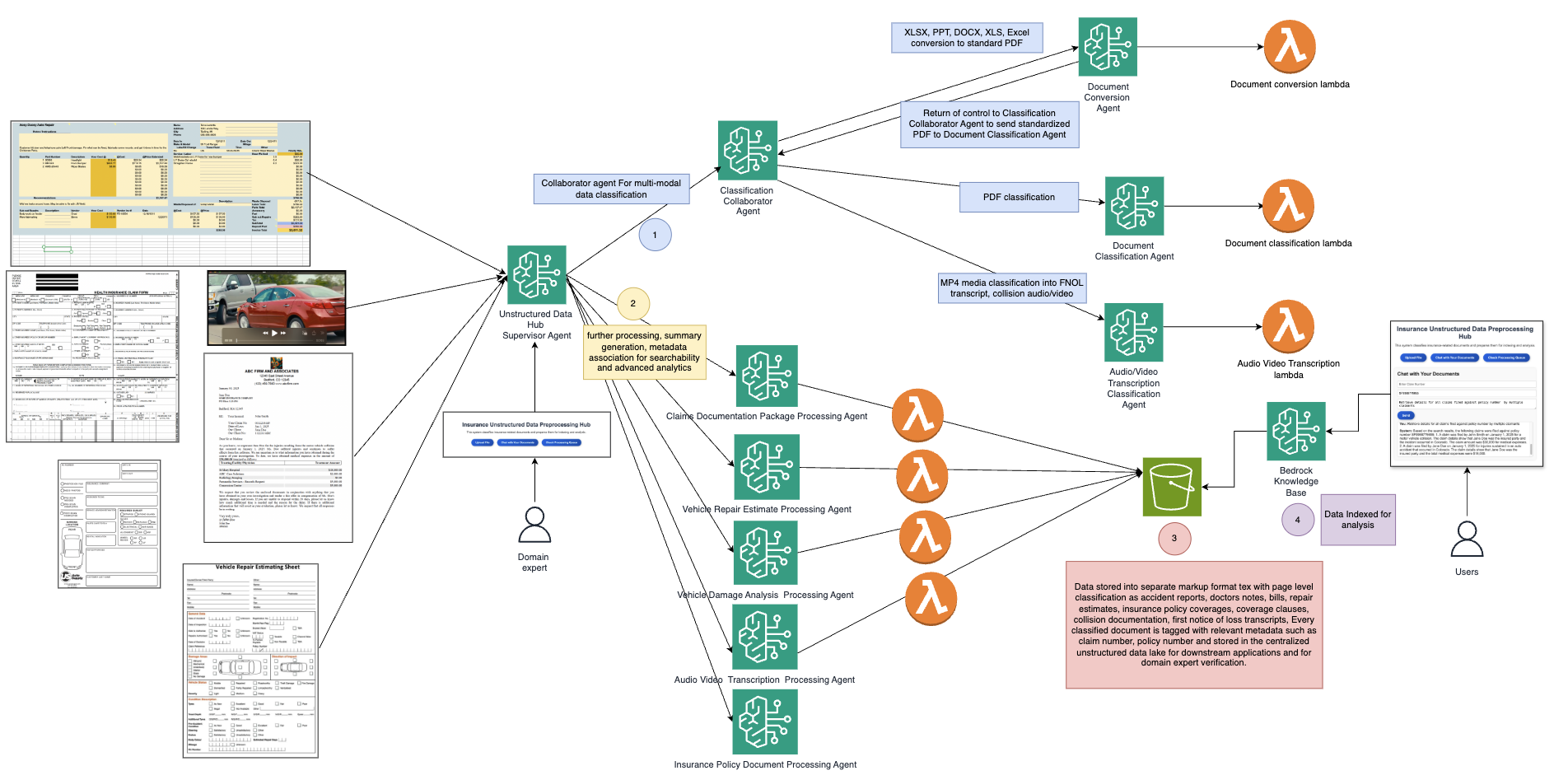
Страхові компанії стикаються з проблемами при обробці різноманітних неструктурованих даних. Конвеєр мультиагентної співпраці автоматизує збір і перетворення даних, підвищуючи точність аналітики на основі штучного інтелекту.
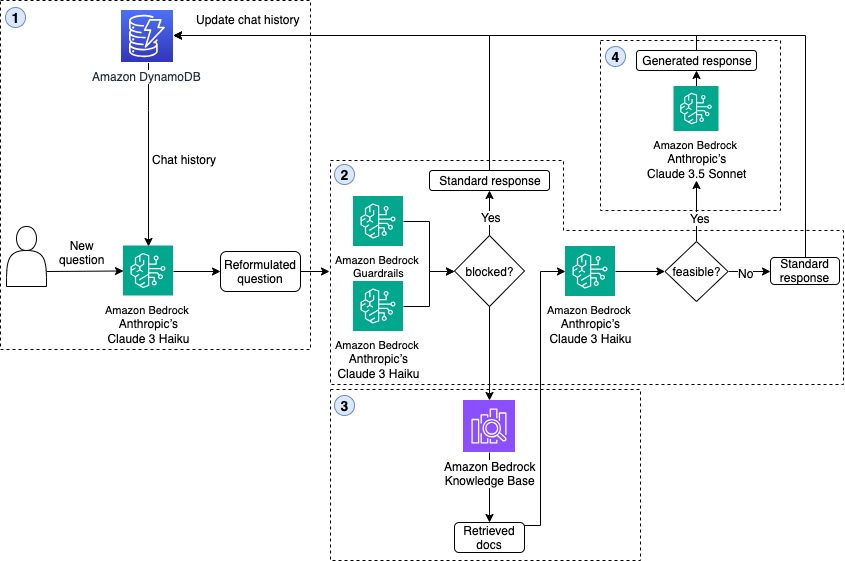
HERE Technologies у партнерстві з AWS GenAIIC створили генеративного помічника для розробників на основі штучного інтелекту, який покращує процес адаптації до самообслуговування Maps API. Інструмент перетворює запити на природній мові в інтерактивні картографічні візуалізації, покращуючи користувацький досвід та залученість.

«План дій щодо можливостей штучного інтелекту» Кейра Стармера має на меті інтегрувати ШІ у Великобританії, але критики стверджують, що це лише чергова технологічна бульбашка, яка приносить користь обраним, експлуатуючи чужу працю та дані. Автори книги прямо говорять про потенційне накопичення багатства і заміну якісних послуг штучними замінниками в індустрії ШІ.