
Керівники технологічних компаній прагнуть автоматизувати всю працю за допомогою штучного інтелекту, отримуючи при цьому заробітну плату. Засновник Fairly Trained попереджає про рішучість еліти замінити людей на робочі місця.

Протокол Model Context Protocol (MCP) необхідний для інтеграції користувацьких інструментів з Claude Desktop, забезпечуючи централізований спосіб керування інструментами через різні інтерфейси. У порівнянні з традиційними методами, такими як RAG, MCP забезпечує безперешкодну інтеграцію без необхідності створювати власний сервер з нуля.

Президент України запросив Папу Римського Лева XIV до України, закликавши ЗМІ припинити поляризацію мови. Лев виступає за відповідальне використання штучного інтелекту в журналістиці.

WebAssembly розширює можливості браузера Бібліотека Pyodide дозволяє запускати код на Python у браузері, що є корисним для дослідників даних та фахівців з машинного навчання.

Штучний інтелект ще не є надійним для виконання робочих завдань, попри свій потенціал. Тім Кук з компанії Apple підкреслює роль ШІ в підвищенні ефективності та розвитку.

Доктор Роман Рачка застерігає від заміни людської підтримки чат-ботами на основі штучного інтелекту в сфері психічного здоров'я, підкреслюючи важливість справжньої взаємодії з людиною. Хоча ШІ пропонує певні переваги, залишаються побоювання щодо конфіденційності даних та залежності від технологій, проте він може забезпечити цінний анонімний простір, доступний цілодобово, який доповнює очні посл...

Захисник безпеки ШІ Макс Тегмарк закликає оцінювати екзистенційні загрози перед випуском потужних систем ШІ, проводячи паралелі з розрахунками Оппенгеймера перед першим ядерним випробуванням. Дослідження Тегмарка вказує на 90% ймовірність того, що високорозвинений ШІ може становити катастрофічний ризик, підкреслюючи важливість розрахунків безпеки, подібних до тих, що були проведені перед випро...

Генеральний директор CrowdStrike скорочує 5% персоналу, покладаючись на ефективність штучного інтелекту для прийняття рішень. Джордж Курц оголосив про скорочення 500 посад по всьому світу.

Англійська з африканським акцентом є складним завданням для систем ASR, але AccentFold пропонує унікальне рішення, вивчаючи вставки акценту з більш ніж 100 африканських акцентів. Цей метод допомагає системам розпізнавання мови узагальнювати раніше невідомі їм акценти, що робить значний внесок у дослідження в галузі машинного розпізнавання мови.

Стиснення моделей має важливе значення в епоху великих мовних моделей. Дізнайтеся про обрізання, квантування, низькорангову факторизацію та методи дистиляції знань у машинному навчанні.

GlitterGPT, яскравий стиліст GPT-4, привів до несподіваних висновків про поведінку LLM, ритуали спонукання та емоційний резонанс. Грайливий експеримент перетворився на дослідження того, як великі мовні моделі поводяться більше як істоти, ніж як інструменти, кидаючи виклик поняттю душевної взаємодії.

Викривлення даних в аналізі енергоспоживання призвело до лог-перетворення для нормалізації. Порівняння моделей, що використовують лог-трансформовані результати та лог-зв'язки, показало значну різницю в AIC.
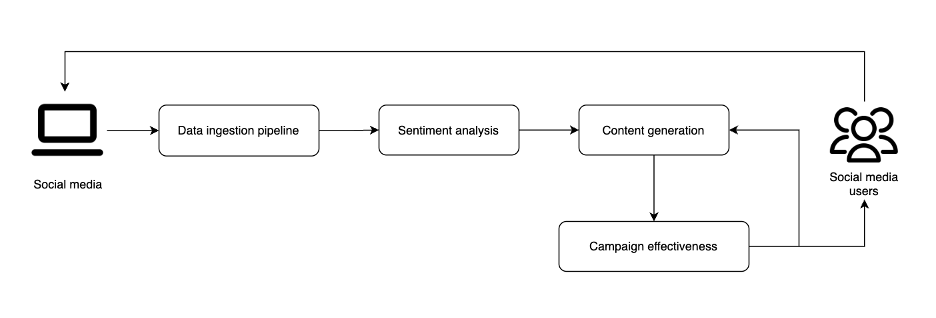
Маркетингові кампанії мають вирішальне значення в медіа та індустрії розваг, але розуміння їхньої ефективності є ключовим. Інноваційне рішення з використанням генеративного ШІ та LLM трансформує маркетингову аналітику, поєднуючи аналіз настроїв, генерацію контенту та прогнозування кампаній для оптимізації результатів.

Лідери британської креативної індустрії, серед яких Coldplay та Dua Lipa, закликають прем'єр-міністра захистити авторські права митців від великих технологій. Провідні митці побоюються, що засоби до існування опиняються під загрозою, оскільки компанії зі штучного інтелекту наполягають на використанні робіт, захищених авторським правом, без дозволу.

Створення MCP-сервера для програми спостережливості з можливостями динамічного аналізу коду захоплює автора більше, ніж genAI. Уроки, винесені з перших POC, підкреслюють потенціал MCP як мультиплікатора сили для підвищення цінності продукту.