
Міністр внутрішніх справ стикається з тиском на поліцію через пропозиції щодо дострокового звільнення. Джерела в оборонному секторі прогнозують, що на саміті НАТО Велика Британія візьме на себе зобов'язання щодо витрат на оборону в розмірі 3,5% ВВП до 2035 року. Лорди кидають виклик уряду щодо законопроекту про дані, звинувачуючи його в нехтуванні креативними індустріями всупереч ШІ.
Themis AI вдосконалює моделі штучного інтелекту, щоб виявляти та виправляти невизначеності та упередження, забезпечуючи надійність у додатках з високими ставками. Цей спін-аут Массачусетського технологічного інституту пропонує рішення для вдосконалення моделей штучного інтелекту та запобігання руйнівним наслідкам шляхом прогнозування збоїв ще до того, як вони трапляться.

Йошуа Бенгіо запускає компанію LawZero для розробки чесного ШІ, щоб запобігти обману людей у гонці озброєнь зі штучним інтелектом вартістю $1 трлн. Бенгіо, хрещений батько ШІ, прагне створити захист від зловмисних ШІ-агентів.
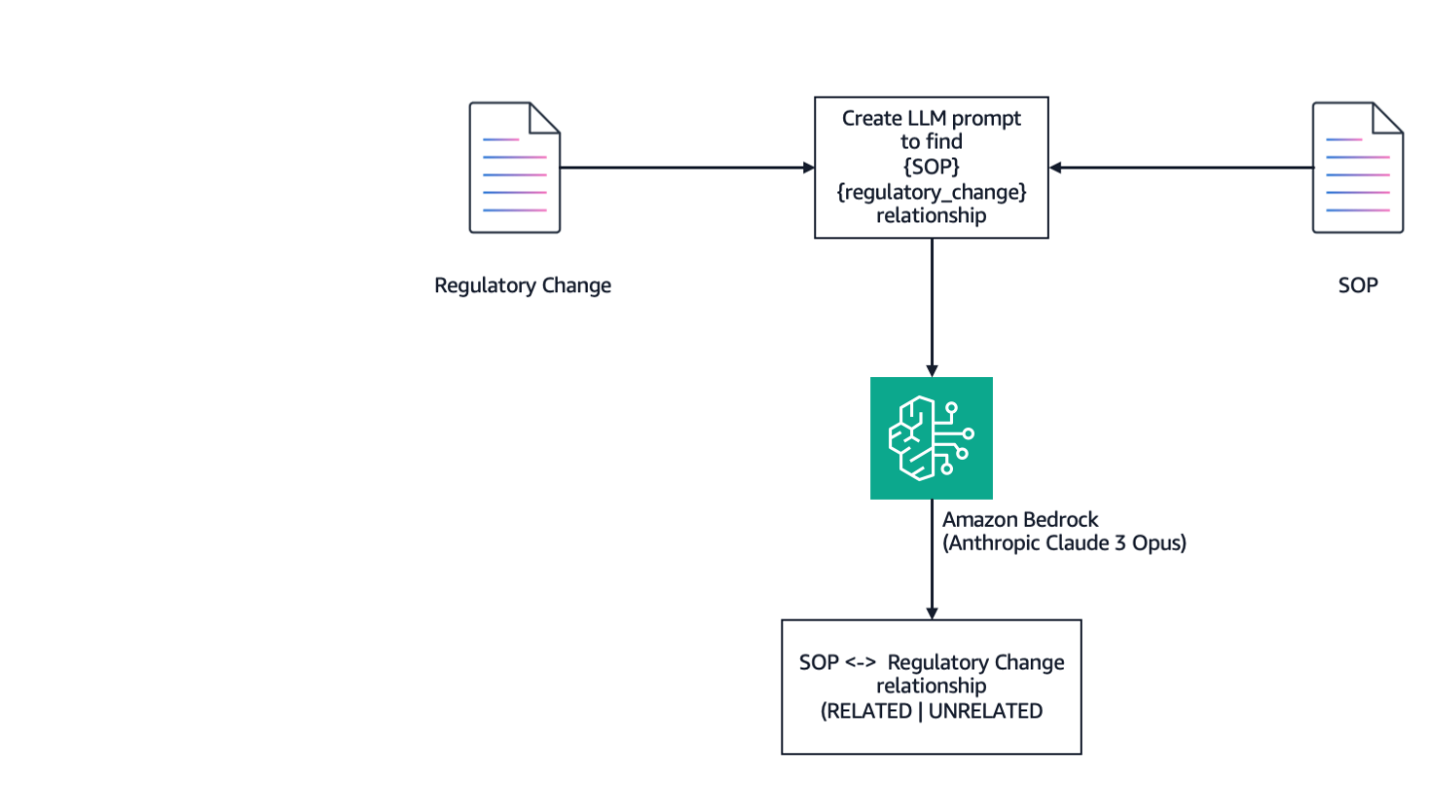
СОП мають вирішальне значення в галузях, що регулюються FDA, таких як охорона здоров'я та медико-біологічні науки, для забезпечення відповідності нормативним стандартам. Використовуючи Amazon Bedrock, організації можуть автоматизувати приведення СОПів у відповідність до мінливих нормативних вимог, оптимізуючи процеси і скорочуючи ресурси.
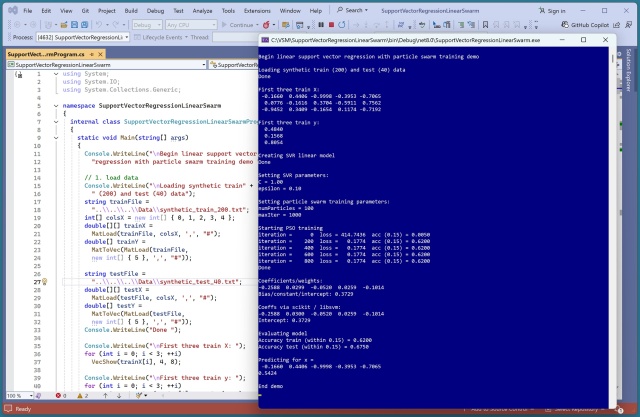
Навчання лінійної регресії опорних векторів (SVR) викликає труднощі через те, що функція втрат не піддається обчисленню. Використання оптимізації рою частинок (PSO) виявилося більш ефективним, ніж еволюційні алгоритми для навчання лінійних SVR-моделей.

Meta, власник Facebook та Instagram, використовуватиме інструменти штучного інтелекту для рекламних кампаній, загрожуючи традиційним рекламним агентствам. Цей крок націлений на маркетингові бюджети брендів в обхід агентств.

Лео Ентоні Селі з Массачусетського технологічного інституту розглядає упередженість даних для навчання ШІ, висвітлюючи недоліки та пропонуючи рішення для більш точних моделей. Він наголошує на важливості навчання студентів ретельній оцінці даних, щоб запобігти упередженості в застосуванні ШІ.

Дослідницька група з Olivetti Group та MIT CSHub використовує штучний інтелект для пошуку стійких альтернатив цементу в бетоні, відкриваючи для себе кераміку та побічні продукти гірничодобувної промисловості як життєздатні варіанти. Їхній фреймворк машинного навчання сортує понад 1 мільйон зразків гірських порід, щоб виявити 19 типів матеріалів, які можуть зменшити витрати та викиди у виробниц...
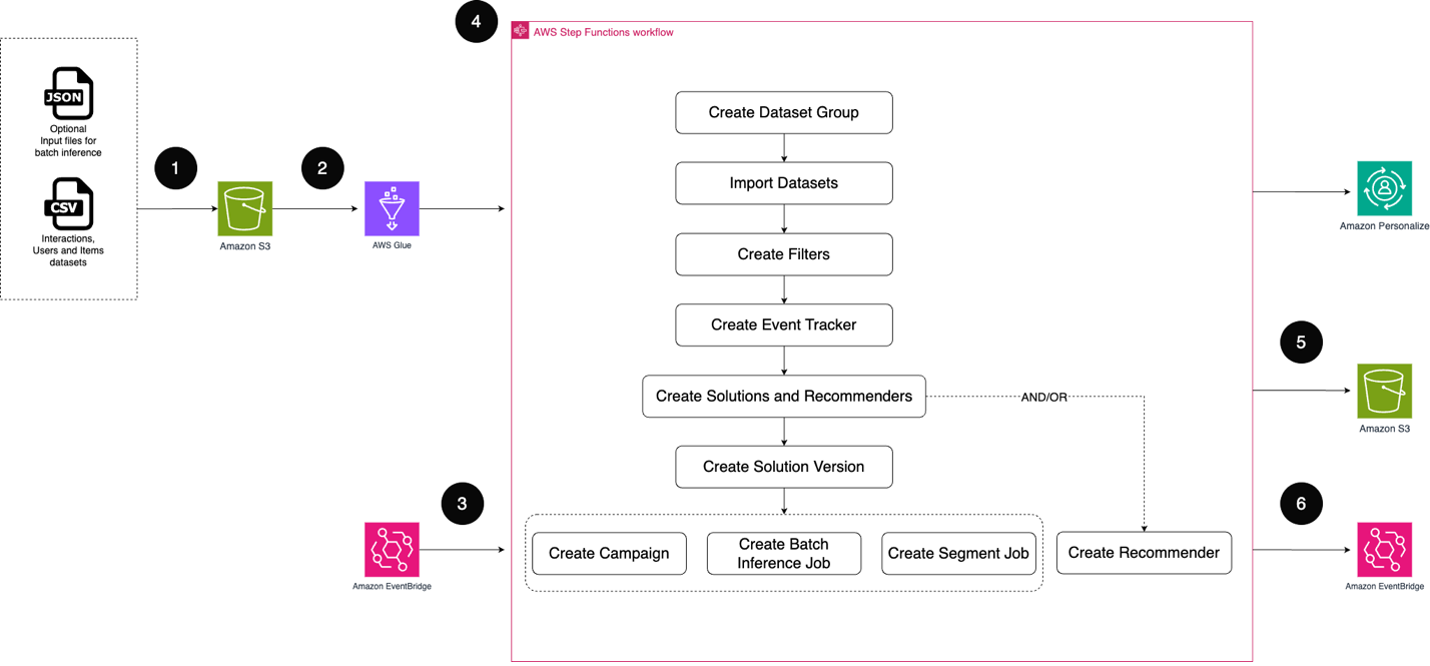
Створення персоналізованого досвіду підвищує залученість і лояльність. Amazon Personalize використовує ML для створення індивідуальних рекомендацій, оптимізуючи процес за допомогою практики MLOps.

Массачусетський технологічний інститут та Стенфордський університет розробляють SketchAgent - систему штучного інтелекту, яка створює ескізи штрих за штрихом на основі підказок природною мовою. Інструмент має на меті докорінно змінити спосіб спілкування людини зі штучним інтелектом завдяки більш природному та ітеративному процесу малювання.

Машинне навчання ШІ аналізує електричні сигнали, що генеруються почерком, щоб виявити тремор Паркінсона за допомогою 3D-друкованої ручки з магнітними чорнилами. Рання діагностика допомагає отримати доступ до підтримки для 10 мільйонів людей у всьому світі, які живуть з хворобою Паркінсона.

Салман Рушді попереджає на фестивалі Hay: ШІ бракує гумору, але якщо він напише смішну книжку, «нам кінець».Рушді зізнається, що уникає ШІ, вважаючи, що автори в безпеці, поки ШІ не зможе створювати гумор.

Радіоведучий замінений аватарами та художник скопійований Midjourney - наслідки заміни ботами. Матеуш Демський ділиться своїм досвідом.

Адвоката Річарда Беднара зі штату Юта оштрафували за використання ChatGPT для посилання на неіснуючу судову справу у подачі документів. Апеляційний суд штату Юта виявив неправдиві посилання, що призвело до вибачень з боку Беднара.

ФБР перевіряє, як підставна особа Сьюзі Вайлз, керівника апарату Білого дому, використовувала штучний інтелект для зв'язку з законодавцями. Особистий мобільний телефон Вайлз зламали, закликаючи одержувачів ігнорувати несанкціоновані повідомлення.