
GeForce NOW запускає «007 First Light», пропонуючи користувачам історію походження Джеймса Бонда та безкоштовний елітний комплект одягу. Насолоджуйтесь високоякісними хмарними іграми з новими іграми та ексклюзивними нагородами, зокрема демоверсією Resident Evil Requiem.
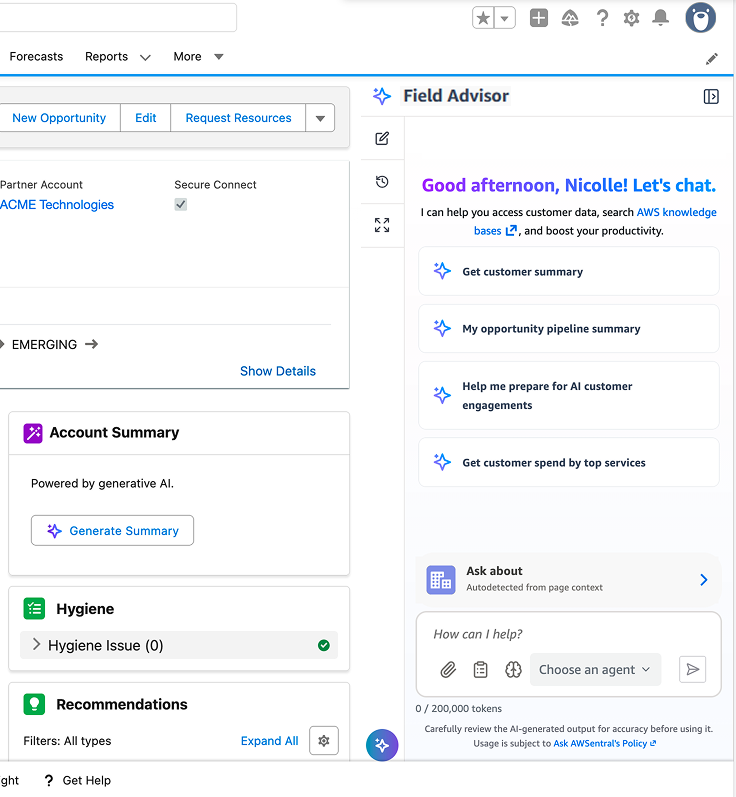
Field Advisor на платформі Amazon Bedrock AgentCore оптимізує координацію роботи агентів у відділі продажів AWS, зменшуючи когнітивне навантаження та покращуючи взаємодію з клієнтами. Цей внутрішній діалоговий помічник підвищує продуктивність, перенаправляючи запити до спеціалізованих агентів, що дозволяє торговим представникам зосередитися на потребах клієнтів.

Amazon Bedrock Data Automation оптимізує процес вилучення даних із фінансових документів за допомогою індивідуальних шаблонів, що забезпечують точність та ефективність. Базові моделі, такі як Anthropic Claude, розширюють можливості OCR для вилучення структурованих даних, придатних для подальшого використання.
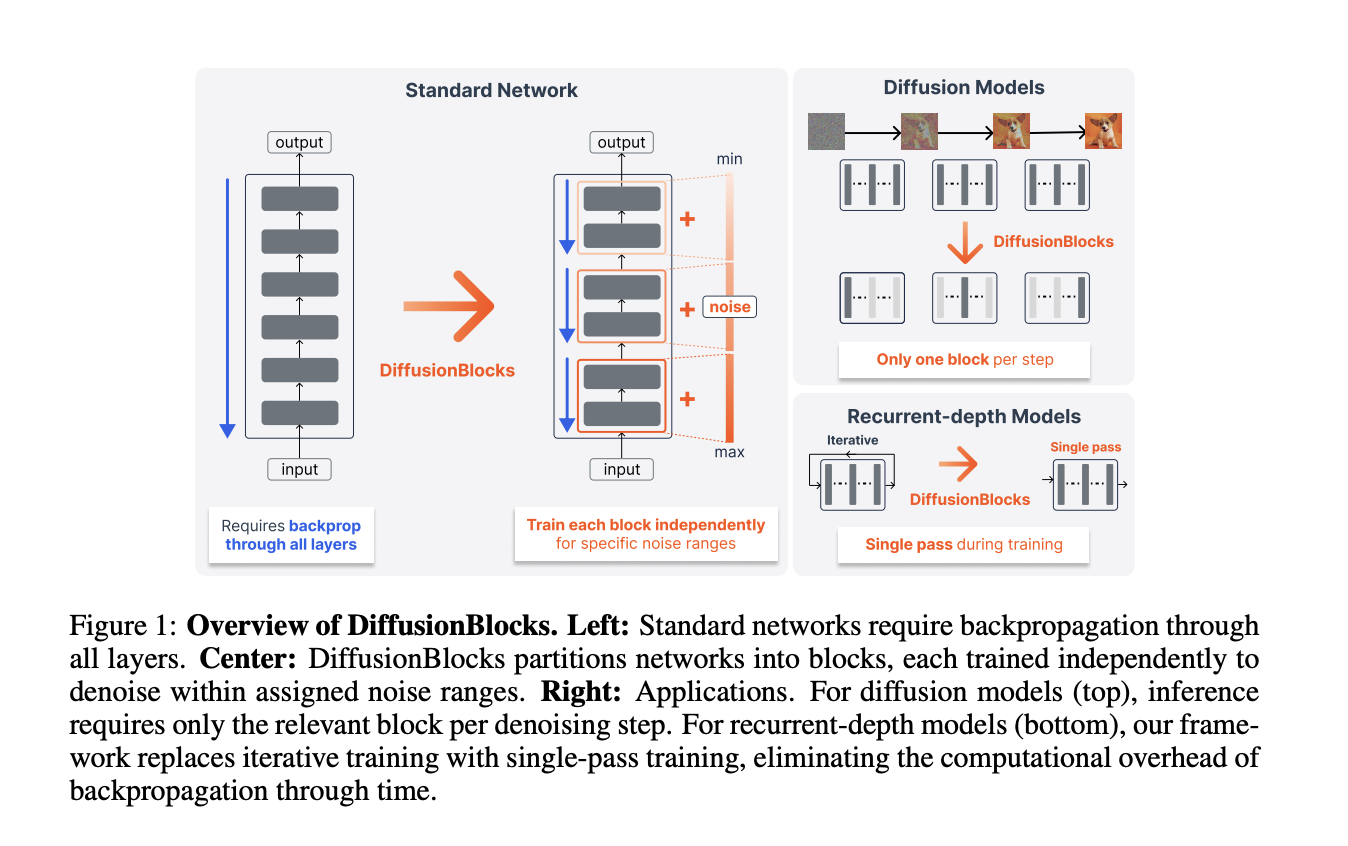
Дослідники з компанії Sakana AI та Токійського університету представляють DiffusionBlocks — метод навчання мереж на основі трансформерів, який передбачає навчання по одному блоку за раз, що дозволяє зменшити споживання пам'яті у B разів. Завдяки застосуванню дискретизації Ейлера до зв'язків залишків цей метод дає змогу навчати кожен блок окремо з використанням власної локальної функції цільово...
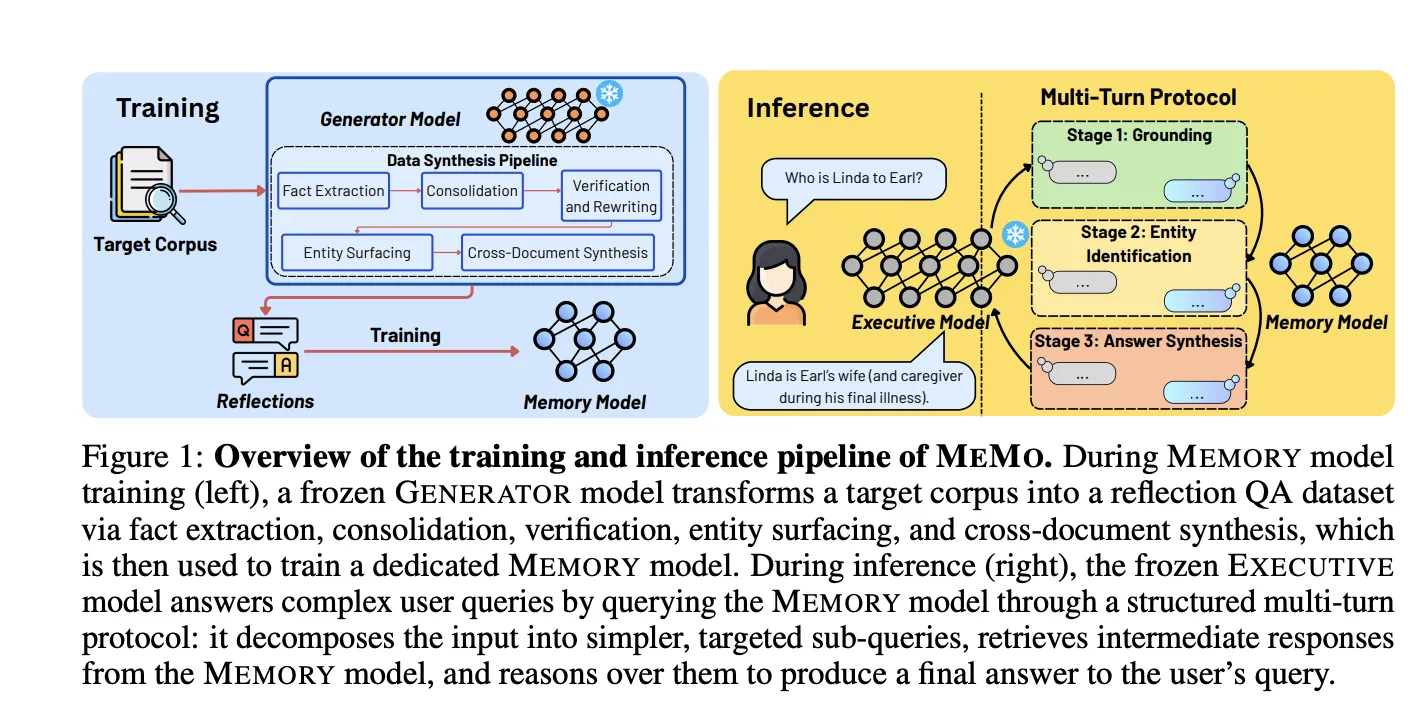
Дослідники з Національного університету Сінгапуру та Массачусетського технологічного інституту (MIT) пропонують систему MEMO для оновлення великих мовних моделей (LLM) без втрати якості за допомогою використання окремих моделей пам'яті та міркування. Унікальний конвеєр навчання MEMO генерує різноманітні пари запитань-відповідей для засвоєння знань, необхідних для міркування на основі різних до...
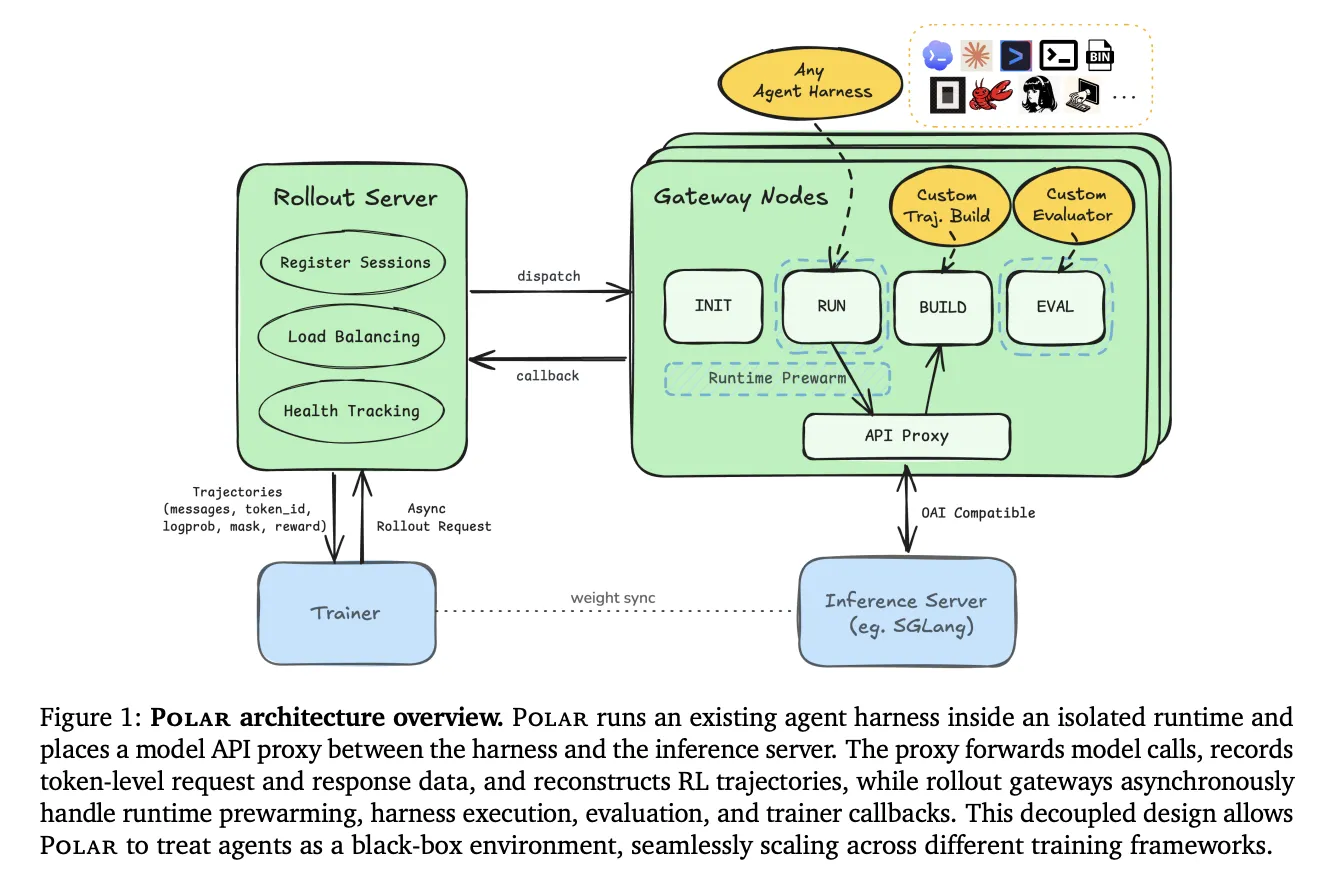
Компанія NVIDIA представляє Polar — платформу для впровадження методів підкріплювального навчання в мовних агентах. Polar спрощує інтеграцію агентів з існуючими тестовими середовищами, покращує сумісність API моделей та оптимізує процеси навчання.
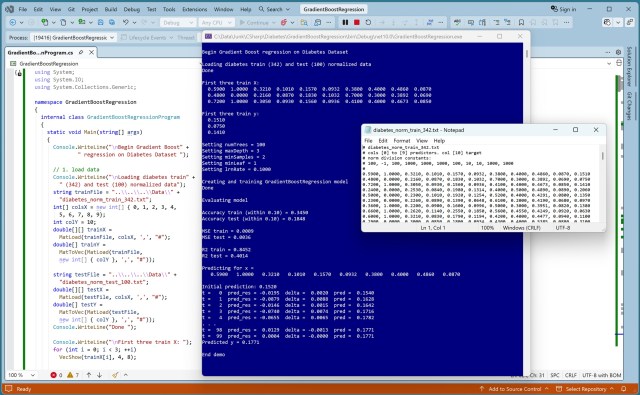
Відточуючи свої навички програмування, розробник тестує модель регресії з градієнтним підсиленням на наборі даних про діабет, демонструючи витончену техніку, що лежить в основі цієї ансамблевої моделі. Реалізуючи 100 дерев рішень на C#, розробник досліджує тонкий, але ефективний підхід до прогнозування залишків з метою підвищення точності.
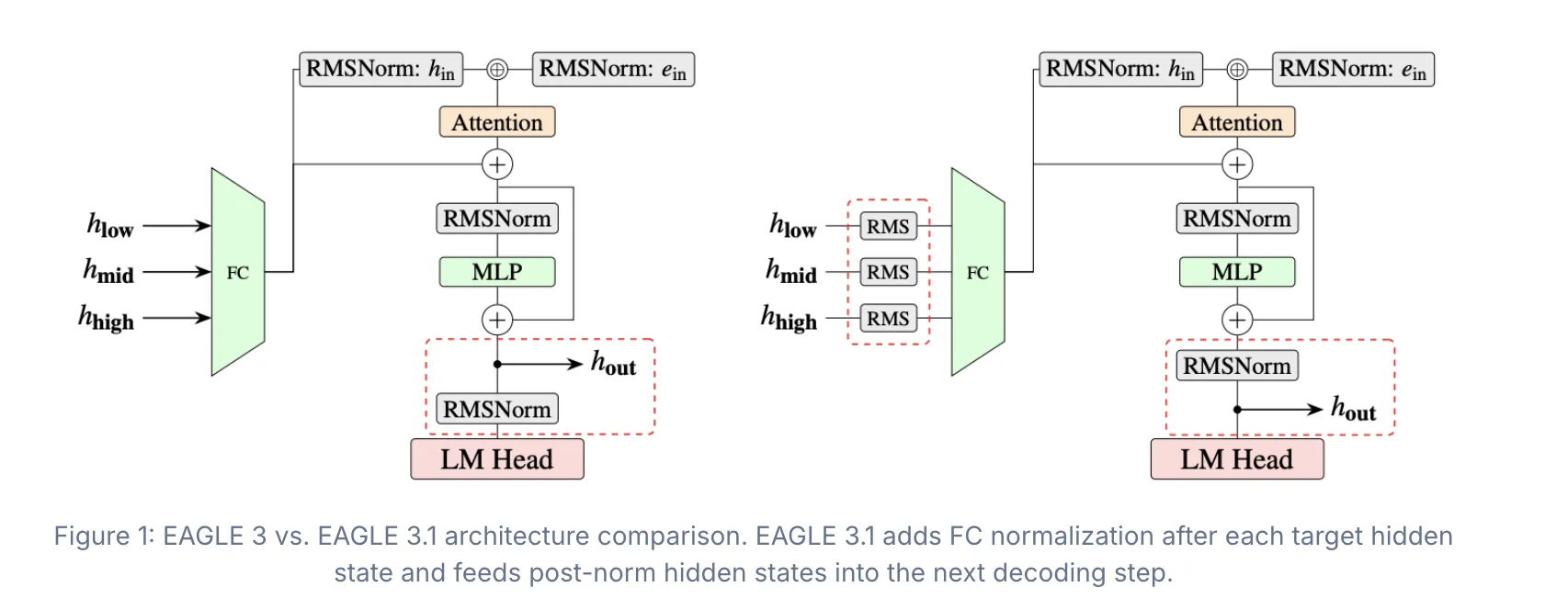
Серія EAGLE, розроблена командами EAGLE Team, vLLM Team та TorchSpec Team, представляє версію EAGLE 3.1, яка підвищує надійність спекулятивного декодування. EAGLE 3.1 вирішує проблеми з відхиленням уваги, забезпечуючи підвищену стабільність та продуктивність у різноманітних середовищах.
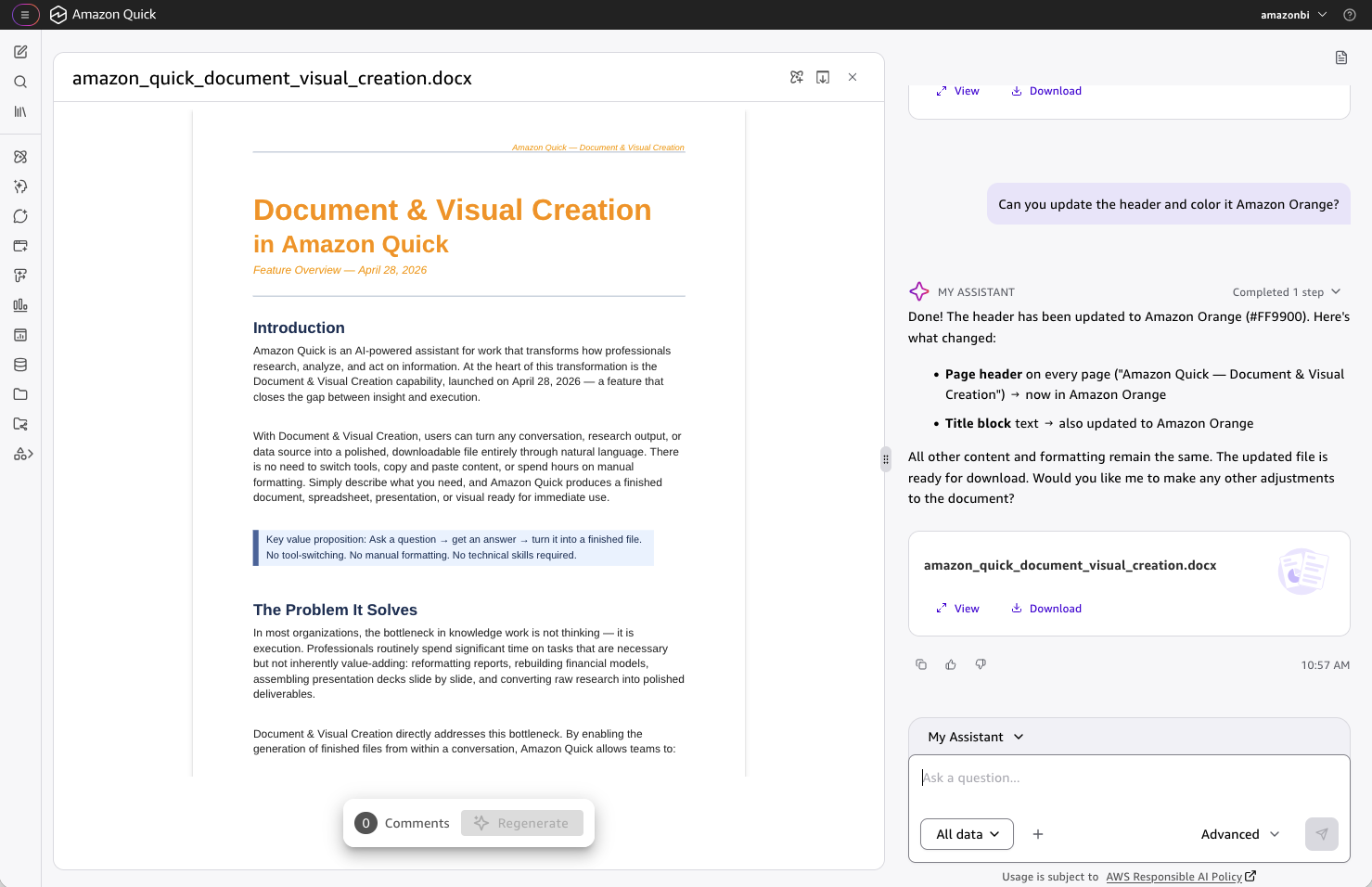
Amazon Quick дає змогу фахівцям створювати відформатовані документи та візуальні матеріали на основі даних у реальному часі, заощаджуючи час на рутинні завдання. Результати можна експортувати у формати Word, Excel, PowerPoint, PDF та у вигляді бізнес-візуалізацій, які можна повністю редагувати для подальшої роботи без необхідності повторного створення.
Для створення додатків на основі штучного інтелекту більше не потрібні глибокі знання в галузі машинного навчання. За допомогою Strands Agents та сервісів AWS можна створювати інтелектуальних агентів, написавши всього 30 рядків коду, що спрощує розробку штучного інтелекту для середовищ AWS.
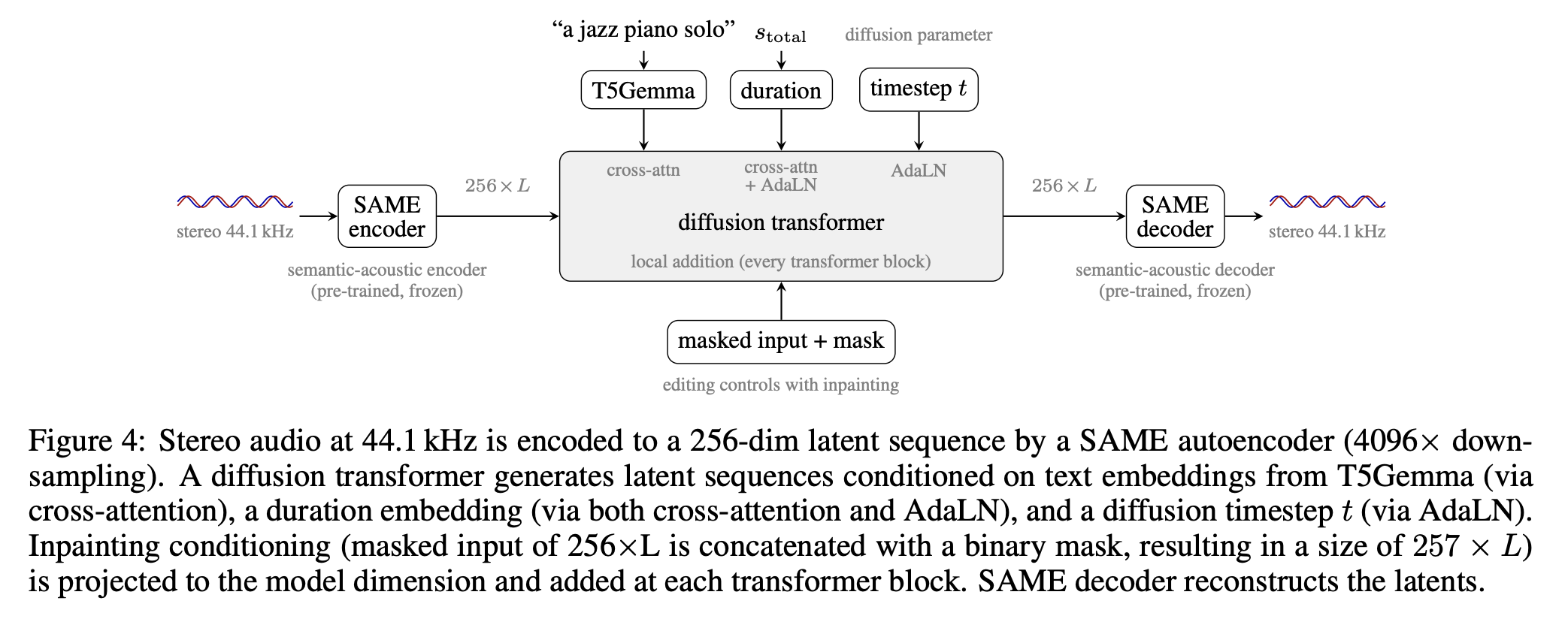
Компанія Stability AI випустила Stable Audio 3 з відкритими вагами та технічним документом. Моделі латентної дифузії підтримують вихідні дані змінної довжини та редагування на основі відновлення пропущених фрагментів для генерації стереоаудіо.
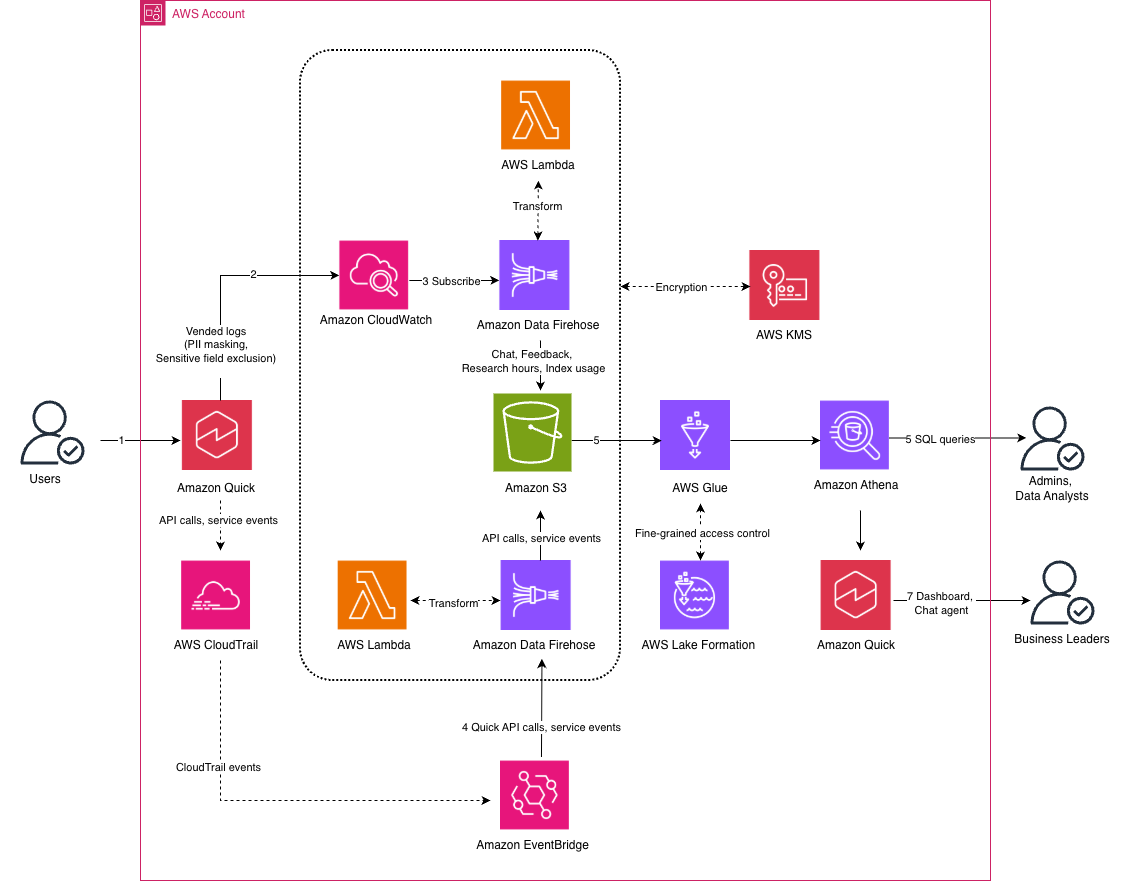
Amazon Quick пропонує централізоване рішення для моніторингу корпоративних платформ штучного інтелекту, об’єднуючи дані про використання для більш ефективного відстеження та аналізу. Завдяки інтеграції зі службами AWS Amazon Quick забезпечує моніторинг, аналітику та управління за допомогою захищеного сховища даних, Amazon Athena та інформаційної панелі Quick Sight.
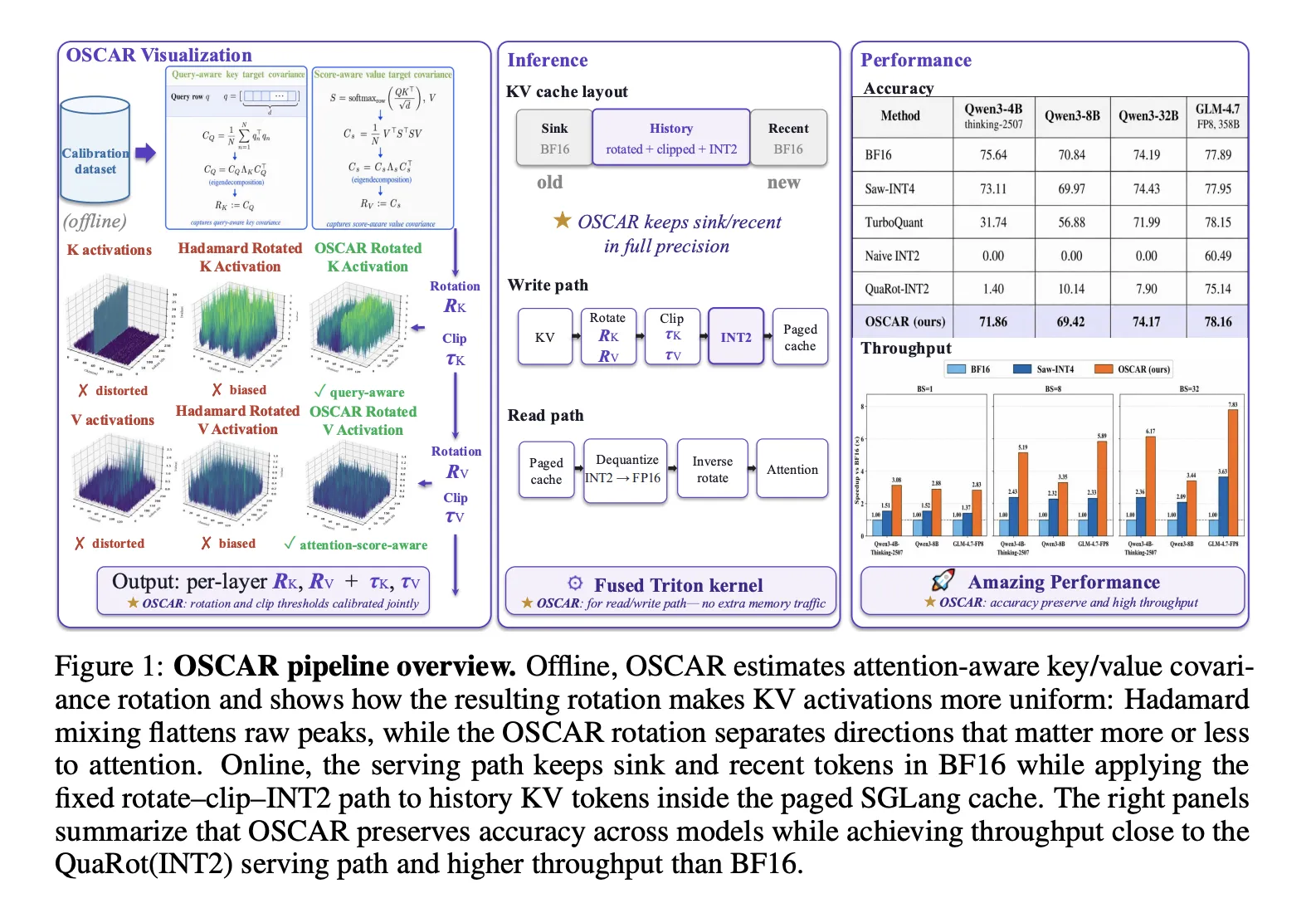
Кеш KV є значною статтею витрат при обслуговуванні великих мовних моделей (LLM); його стиснення за допомогою квантування на основі обертань, реалізованого в OSCAR, підвищує ефективність при точності INT2. OSCAR обчислює обертання на основі статистичних даних уваги, щоб зменшити похибки квантування, покращуючи якість уваги та продуктивність моделі.
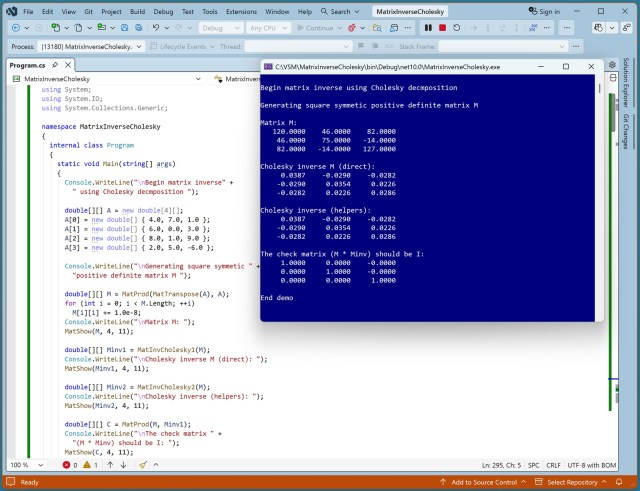
Розробка функції обернення матриці з використанням розкладу Холеського: коротший код проти більшої ефективності. Аналітика в галузі розробки програмного забезпечення з використанням коду, згенерованого штучним інтелектом, та дизайн персонажів в анімаційних фільмах.
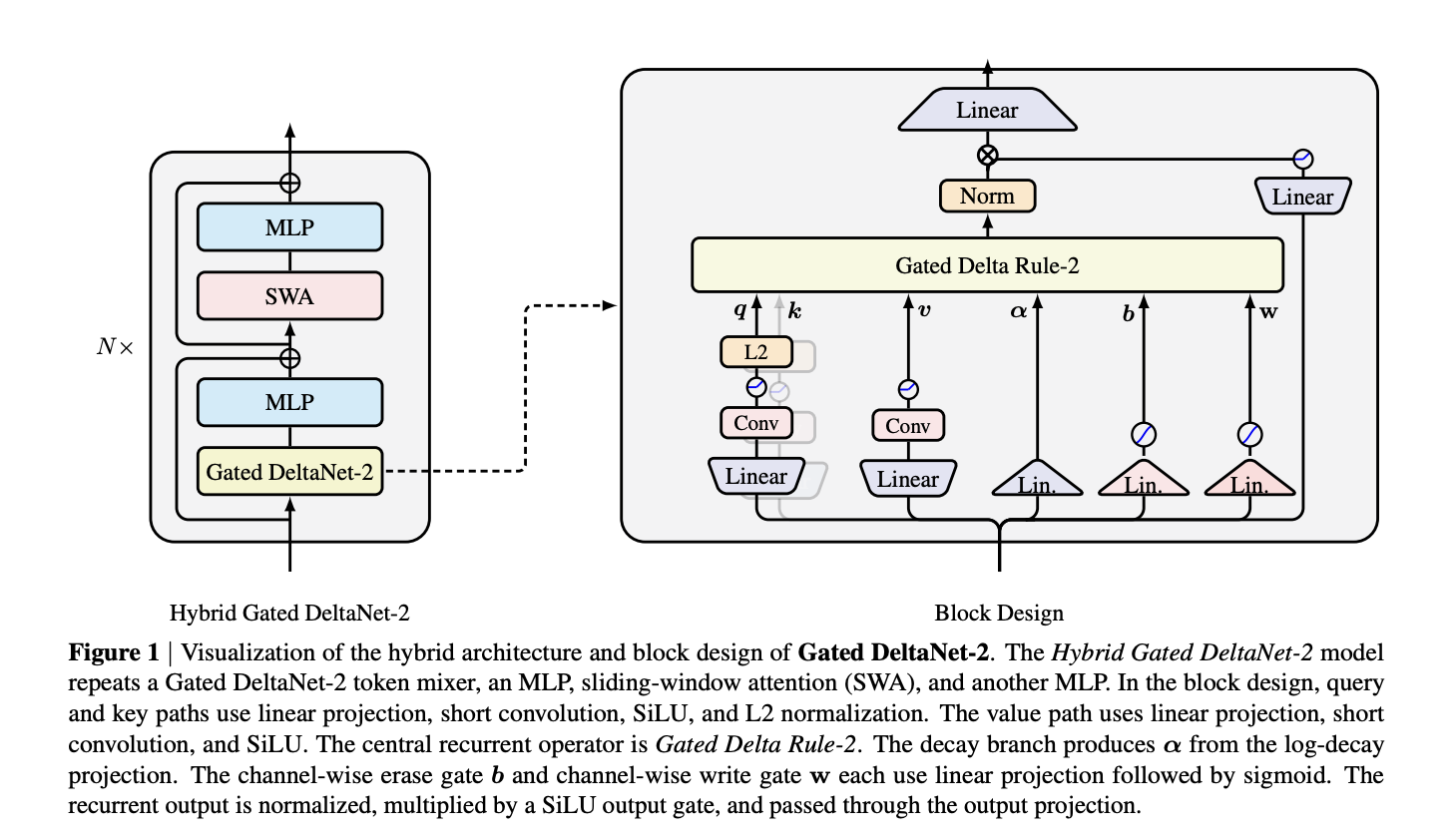
Компанія NVIDIA представляє модель Gated DeltaNet-2 з лінійною увагою для покращення редагування пам'яті. Модель оснащена двома каналними шлюзами, що забезпечує їй кращі результати порівняно з попередніми моделями в дослідницьких тестах.