
Трансформаторні LLM просунулися у виконанні завдань, але залишаються чорними скриньками. Нова стаття Anthropic про трасування ланцюгів має на меті розкрити внутрішню логіку LLM для інтерпретації.

Австралійська команда відроджує американського композитора Елвіна Люсьєра, викликаючи дискусії про штучний інтелект та авторство. Моторошна, красива симфонія, створена без участі живих музикантів.

Навчання еволюційної оптимізації для Kernel Ridge Regression є перспективним, але обмежується точністю 90-93% через проблеми з масштабуванням. Традиційна матрична інверсна техніка перевершує за точністю та швидкістю.

NVIDIA висвітлює досягнення фізичного ШІ під час Національного тижня робототехніки, демонструючи технології, що формують інтелектуальні машини в різних галузях. IEEE відзначає дослідників NVIDIA за новаторську роботу в області масштабованого навчання роботів, навчання з підкріпленням у реальному світі та втіленого ШІ.
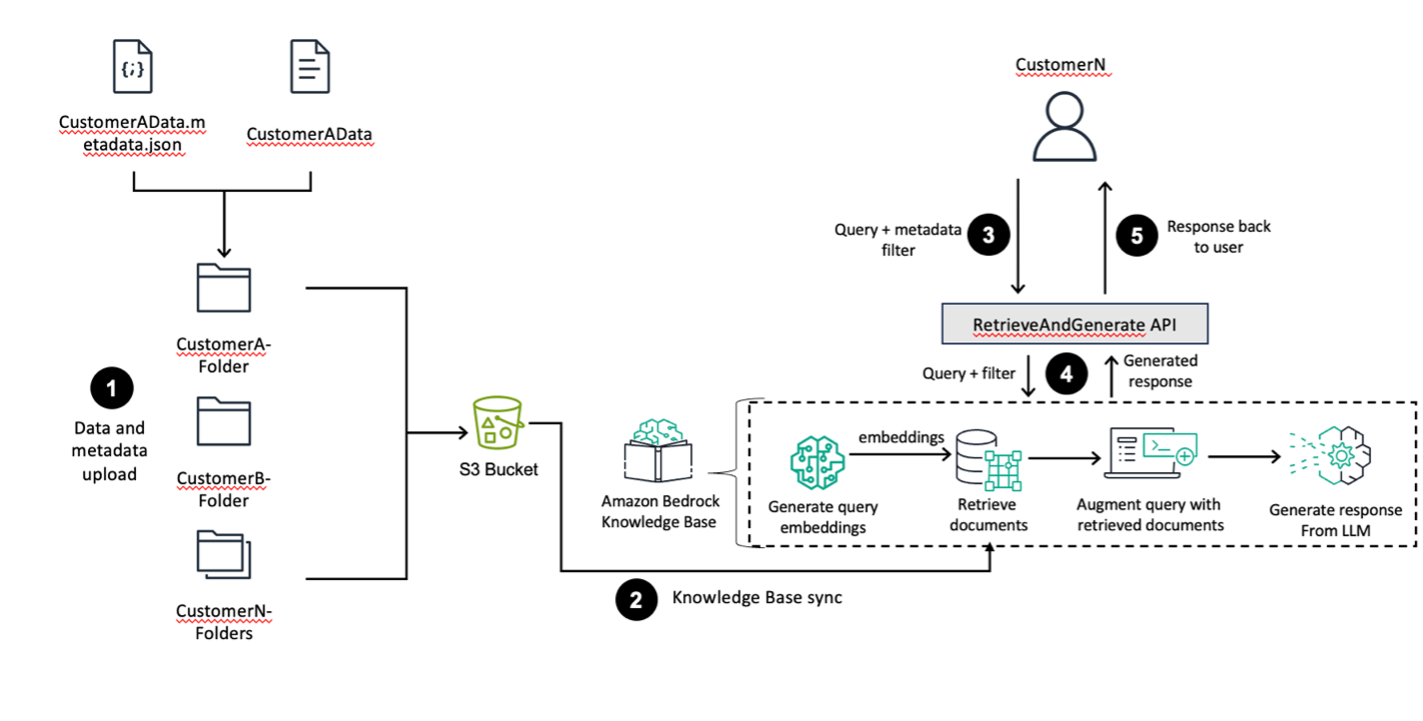
Amazon Bedrock пропонує високопродуктивні базові моделі та наскрізні робочі процеси RAG для створення точних генеративних додатків ШІ. Використовуйте структури папок S3 і фільтрацію метаданих для ефективної сегментації даних у єдиній базі знань, забезпечуючи належний контроль доступу між різними бізнес-підрозділами.

Автоматизовані моделі оцінки (AVM) використовують штучний інтелект для прогнозування вартості житла, але невизначеність може призвести до дорогих помилок. AVMU кількісно оцінює надійність прогнозів, допомагаючи приймати більш розумні рішення при купівлі нерухомості.

Штучний інтелект у креативних індустріях порівнюють з фортепіано, потенціал штучного інтелекту в мистецтві ставлять під сумнів. Листівка Reform UK критикує збір сміття, пропонує наймати більше ботаніків для місцевих служб.
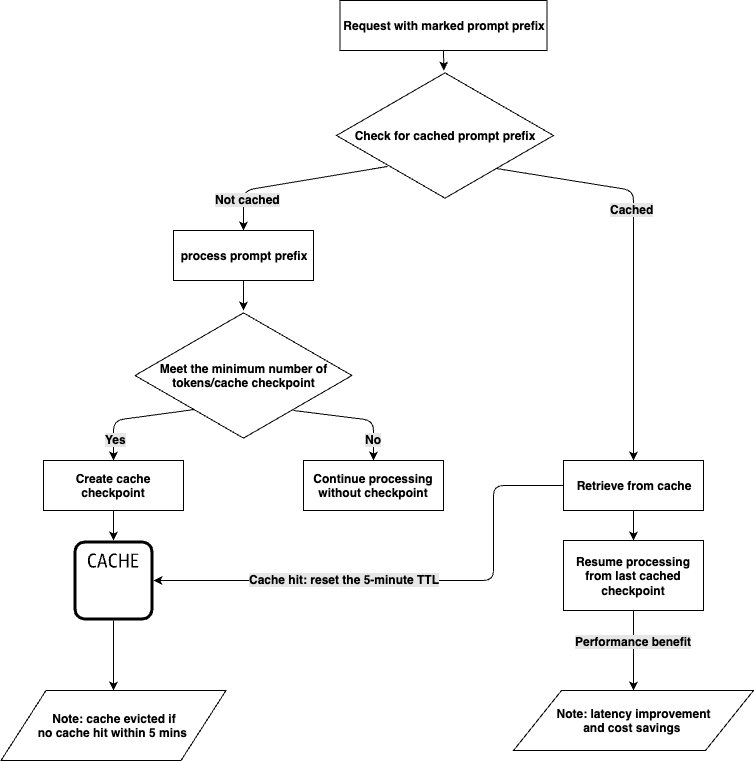
Amazon Bedrock тепер пропонує кешування підказок з моделями Claude 3.5 Haiku та Claude 3.7 Sonnet від Anthropic, що зменшує затримку до 85% та витрати на 90%. Позначайте певні частини підказок, які потрібно кешувати, оптимізуючи обробку вхідних токенів і максимізуючи економію коштів.

Автори критикують Meta за використання їхніх творів для навчання ШІ, але хіба творчість не будується на ідеях минулого? Приклади Мак'юена та Орвелла показують, що митці завжди черпали натхнення в інших. Видавничу індустрію звинувачують у тому, що вона випускає книжки-копії, які імітують успішні тренди.

Нове коло зі штучним інтелектом від Meta у WhatsApp викликає страх і лють серед користувачів, викликаючи занепокоєння щодо приватності та стеження в метапросторі. Користувачі запитують, чи не торгують вони мимоволі своїми даними заради зручності, наголошуючи на важливості читання умов та положень.

Справи про порушення авторських прав у США проти OpenAI і Microsoft, в яких фігурують такі автори, як Та-Нехісі Коутс і Джон Грішем, були об'єднані в Нью-Йорку для підвищення ефективності. Централізація має на меті впорядкувати розгляд справ і уникнути непослідовних рішень, незважаючи на спротив авторів і ЗМІ.
Інструмент діагностики ШІ затримується; Ніцца повільно оцінюється. Виділено риторику уряду проти реальності. Розширено скринінг раку кишечника.

Компанії переходять з OpenAI на Amazon Nova, щоб отримати економічно ефективні моделі штучного інтелекту з ширшими можливостями. Amazon Nova пропонує різні моделі, такі як Pro, Lite і Micro, кожна з яких оптимізована для різних застосувань з меншими витратами та вищою ефективністю.
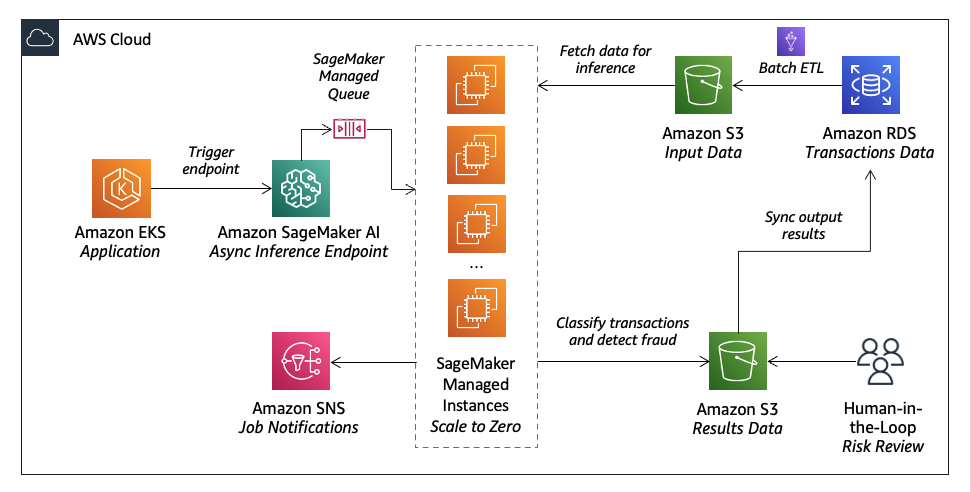
Lumi, австралійський фінтех-кредитор, використовує Amazon SageMaker AI для надання швидких кредитних рішень з точною кредитною оцінкою. Вони поєднують машинне навчання з людськими судженнями для ефективного і точного управління ризиками.
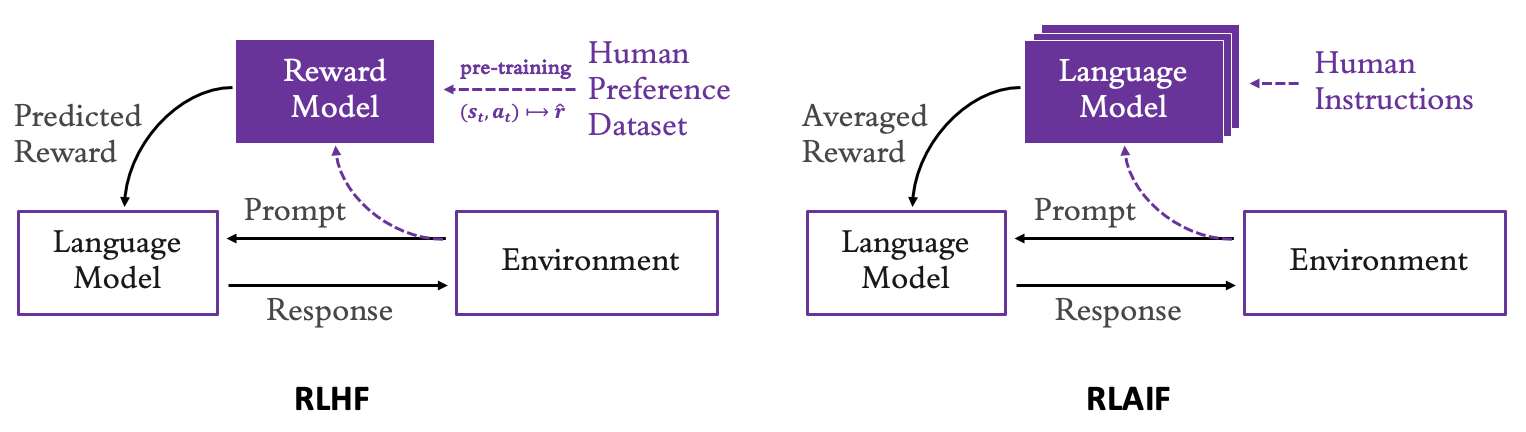
Великі мовні моделі (ВММ) можуть бути точно налаштовані за допомогою навчання з підкріпленням на основі зворотного зв'язку від людини для узгодження з уподобаннями користувача. Цей метод, відомий як супервирівнювання, дозволяє LLM налаштовувати параметри безпосередньо до наборів даних, оминаючи потребу в послугах людського анотування.