
Мова радіологів може вводити в оману - нове дослідження Массачусетського технологічного інституту показує надмірну самовпевненість при використанні таких термінів, як «дуже ймовірно» проти «можливо». Розроблено рамки для підвищення точності повідомлень радіологів про патології, що сприятиме покращенню лікування пацієнтів.
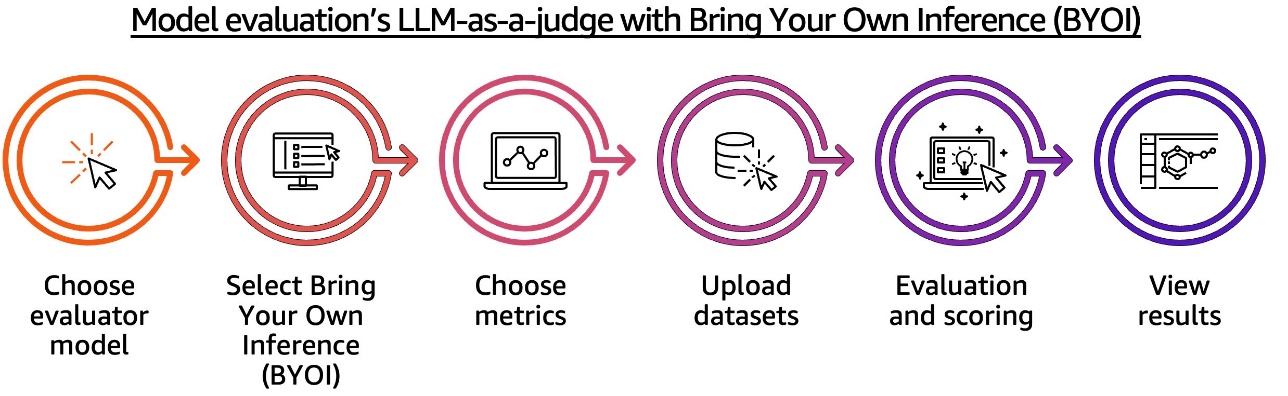
Amazon Bedrock Evaluations тепер пропонує загальний доступ до функцій оцінювання LLM-as-a-judge та RAG, а також нові можливості BYOI для зовнішніх систем RAG. Нові метрики цитування дають глибше розуміння точності та релевантності системи RAG, оптимізуючи продуктивність та якість ШІ.

Угода Reddit з Google на $60 млн щодо використання даних користувачів для навчання ШІ викликає занепокоєння з приводу конфіденційності. Vana пропонує децентралізовану мережу, де користувачі володіють і контролюють свої дані, що змінює розвиток ШІ.

Алгоритм Flash Attention революціонізує трансформатори, оптимізуючи доступ до пам'яті, роблячи обчислення швидшими та ефективнішими. Flash Attention v3 впроваджує покращення для графічних процесорів Nvidia Hopper та Blackwell, що ще більше підвищує продуктивність.
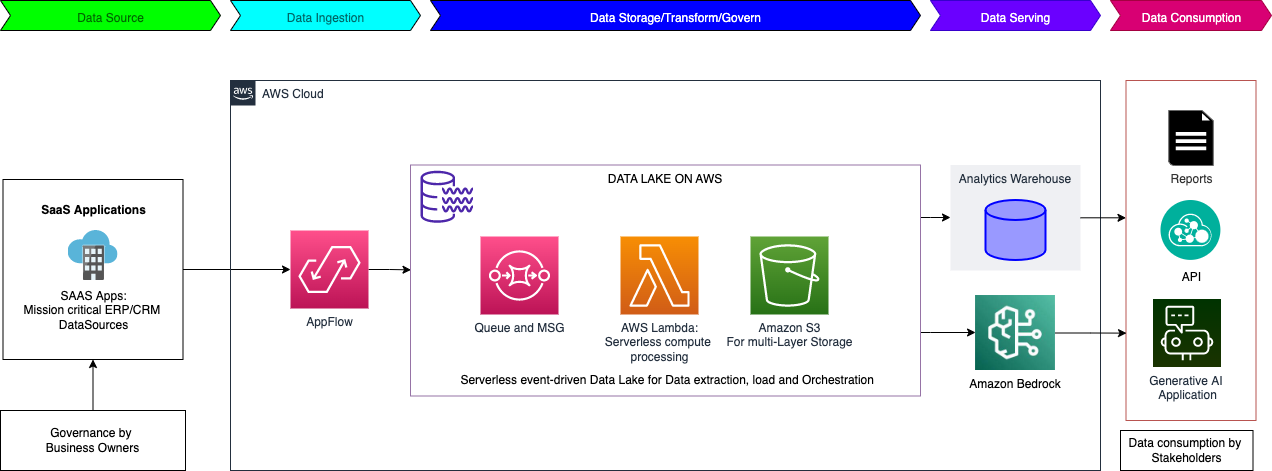
Корпорація OMRON прагне трансформувати бізнес-моделі за допомогою інноваційної платформи OMRON Data & Analytics Platform (ODAP), яка використовує Amazon Web Services для розширеної інтеграції даних і можливостей генеративного штучного інтелекту. Розбиваючи ізоляцію даних і вирішуючи проблеми управління, ODAP надає цінну інформацію для оптимізації операцій і підвищення якості обслуговування клі...

Інвестиції у відновлювану енергетику досягли рекордного рівня, але майбутнє непевне. Енергетична конференція Массачусетського технологічного інституту обговорює необхідність рівних правил гри та державної підтримки для прориву в галузі чистої енергетики.

Автори протестують проти використання LibGen для навчання штучного інтелекту. Кейт Моссе, Трейсі Шевальє та Далджит Награ вийшли на демонстрацію до офісу Meta у Кінгс-Кроссі.

AWS розробляє AI Workforce - систему дронів і штучного інтелекту для безпечніших, швидших і точніших перевірок інфраструктури. Система використовує автономні дрони, оснащені сучасними датчиками та штучним інтелектом, щоб зменшити ризики для людей, підвищити ефективність та надати кращі дані для проактивного технічного обслуговування.

Юридичні контракти мають вирішальне значення для бізнесу, але їх розуміння та вилучення інформації може бути складним. Впровадження GraphRAG в Neo4j може спростити цей процес, структуруючи контракти у вигляді графа знань, що дозволяє здійснювати більш точний і контекстно-орієнтований пошук.

Агенти штучного інтелекту в роздрібній торгівлі надають персоналізований досвід, збагачують знання про товари та пропонують багатоканальну підтримку, переосмислюючи досвід покупок завдяки безшовній інтеграції та можливостям віртуальної примірки. Згідно з останнім звітом NVIDIA, рітейлери, які використовують ШІ, надають перевагу гіперперсоналізованим рекомендаціям для збільшення онлайн-продажів...

Афрофутуризм ставить питання про те, хто формує майбутнє на тлі обіцянок і страхів щодо штучного інтелекту. Лонні Аві Брукс та Рейнальдо Андерсон очолюють боротьбу за різноманітні перспективи в технологіях.
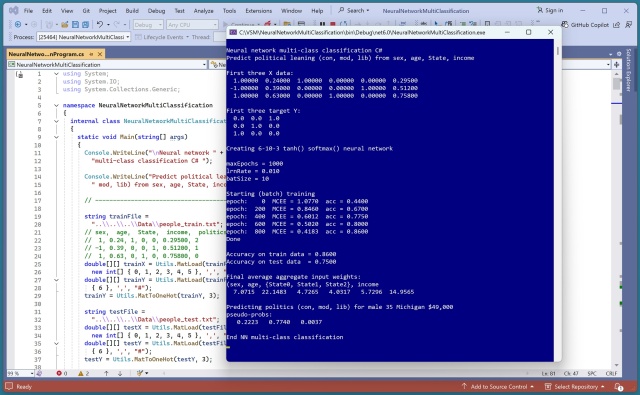
Інтерпретація моделі машинного навчання може бути складним завданням. Експеримент показав, що вік і дохід мають найбільший вплив на прогнозування політичних уподобань.
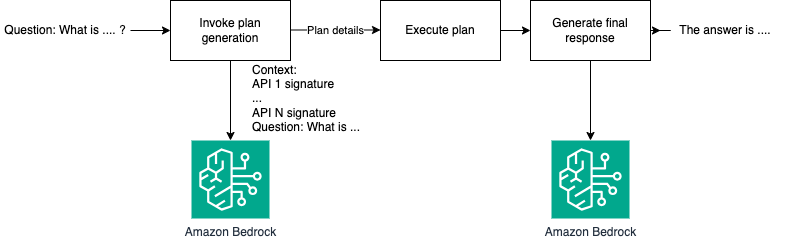
Тепер магістри можуть виконувати складні завдання з багатокроковим обґрунтуванням і виконанням, використовуючи зовнішні інструменти для отримання точних і дієвих результатів. Приклад демонструє пошук записів про пацієнтів з використанням API замість перетворення тексту в SQL, демонструючи здатність моделі ефективно відповідати на аналітичні питання.

Дослідники з Массачусетського технологічного інституту розробили фреймворк, який дозволяє ChatGPT ефективно вирішувати складні завдання планування з 85% успішністю, що перевищує базові показники. Цей універсальний підхід може оптимізувати такі завдання, як планування екіпажів авіакомпаній або управління машинним часом на заводах, революціонізуючи допомогу в плануванні.

Уряд Великої Британії зобов'язався провести оцінку економічного впливу, щоб врахувати занепокоєння депутатів парламенту, членів палати лордів та творчих особистостей, таких як Пол Маккартні. Пропозиція, що дозволяє компаніям, що займаються штучним інтелектом, використовувати твори, захищені авторським правом, без дозволу, була розкритикована Полом Маккартні, Томом Стоппардом та Кейт Буш.