
З листопада 2025 року Amazon SageMaker AI запроваджує двосторонню потокову передачу даних для обробки мовлення в режимі реального часу з перетворенням у текст. API vLLM Realtime від Mistral AI забезпечує безперебійну двосторонню потокову передачу даних між клієнтом і сервером для розгортання компактних моделей розпізнавання мовлення в режимі реального часу, пропонуючи повністю керований сервіс...
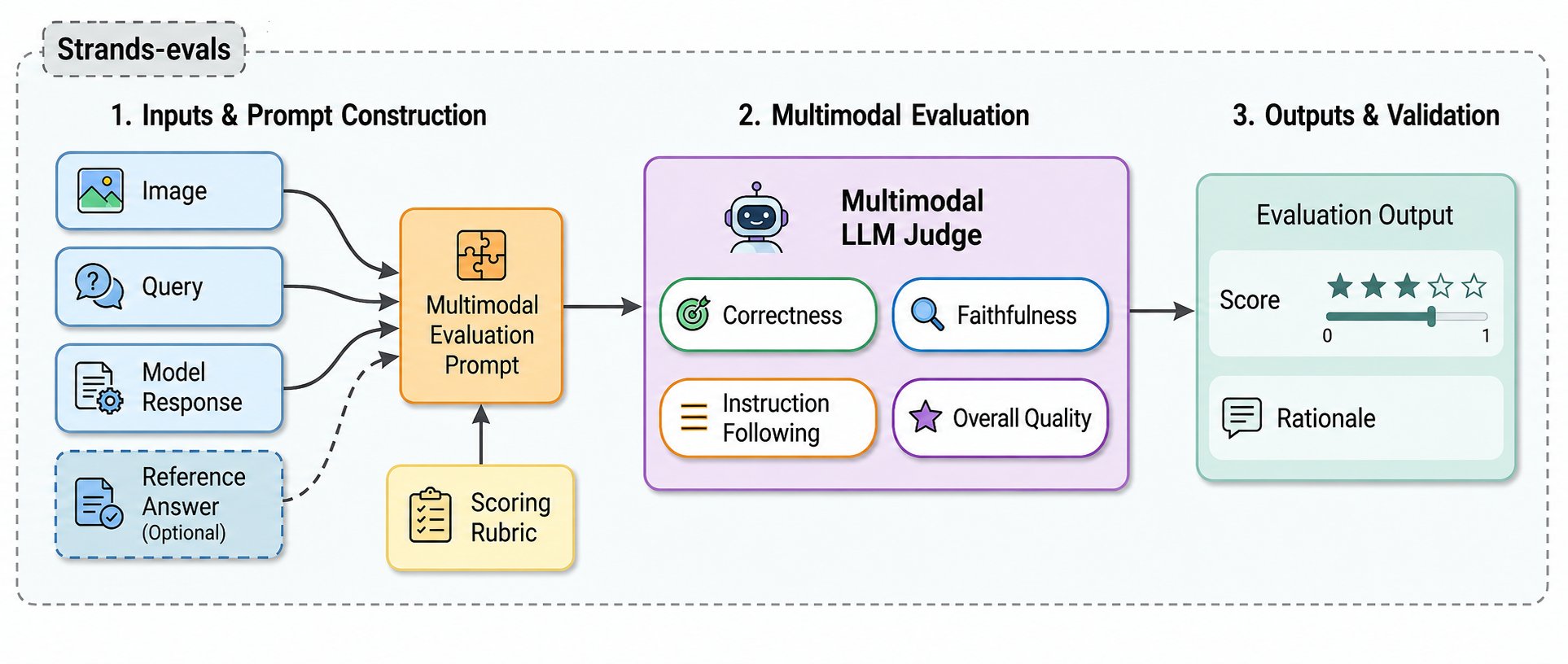
Нові оцінювачі MLLM-as-a-Judge у Strands Evals SDK покращують виконання завдань з перетворення зображень у текст, при цьому прогнозується, що до 2030 року 80 % корпоративного програмного забезпечення стане мультимодальним. Автоматизована мультимодальна оцінка підвищує точність та ефективність розробки програмного забезпечення.

Дослідник з Массачусетського технологічного інституту (MIT) Коннор Колі використовує штучний інтелект для виявлення потенційних низькомолекулярних лікарських препаратів серед величезної кількості можливих сполук, поєднуючи хімічну інженерію та інформатику. У своїй роботі Колі поєднує машинне навчання та хемоінформатику з метою оптимізації автоматизованих хімічних реакцій для розробки нових лік...
Використання моделі StackingRegressor із декількома базовими моделями для прогнозування може виявитися надто складним через величезну кількість параметрів. Демонстрація роботи моделі StackingRegressor на наборі даних про діабет показала, що точно передбачити рівень діабету у пацієнтів досить складно.
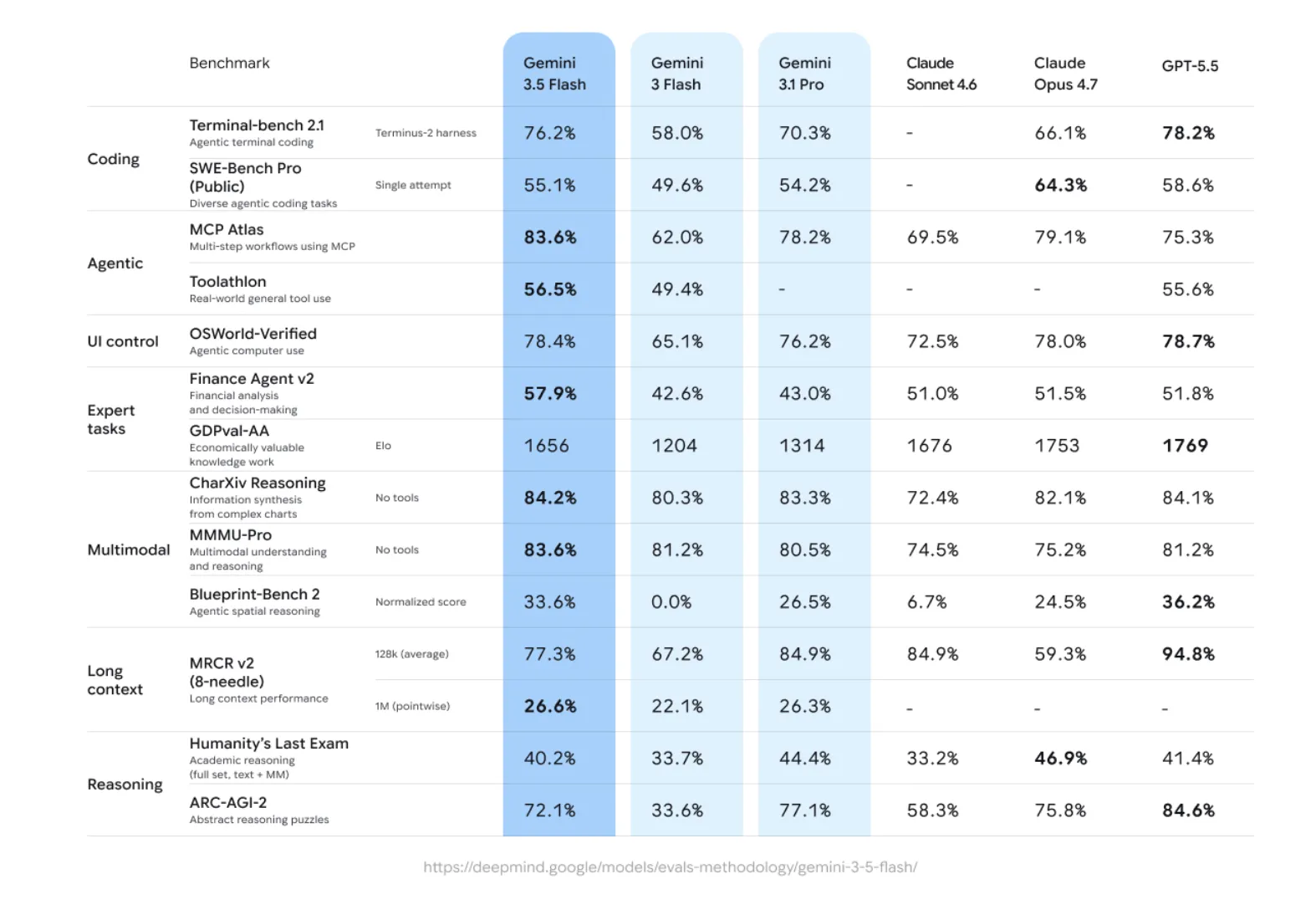
Компанія Google представила модель Gemini 3.5 Flash на конференції Google I/O у травні 2026 року, яка перевершує попередній преміальний рівень завдяки швидшій та економічнішій продуктивності. Gemini 3.5 Flash відрізняється високою ефективністю в програмуванні, виконанні завдань, надійності використання інструментів та здатності до мультимодального розуміння, пропонуючи швидше виконання задач за...

Amazon SageMaker AI тепер підтримує API, сумісний з OpenAI, для кінцевих точок інференції в режимі реального часу, що спрощує виклик моделей за допомогою стандартних SDK. Такі користувачі, як Caffeine.AI, можуть безперешкодно інтегрувати SageMaker як готову кінцеву точку, сумісну з OpenAI, без необхідності внесення змін у власний код.
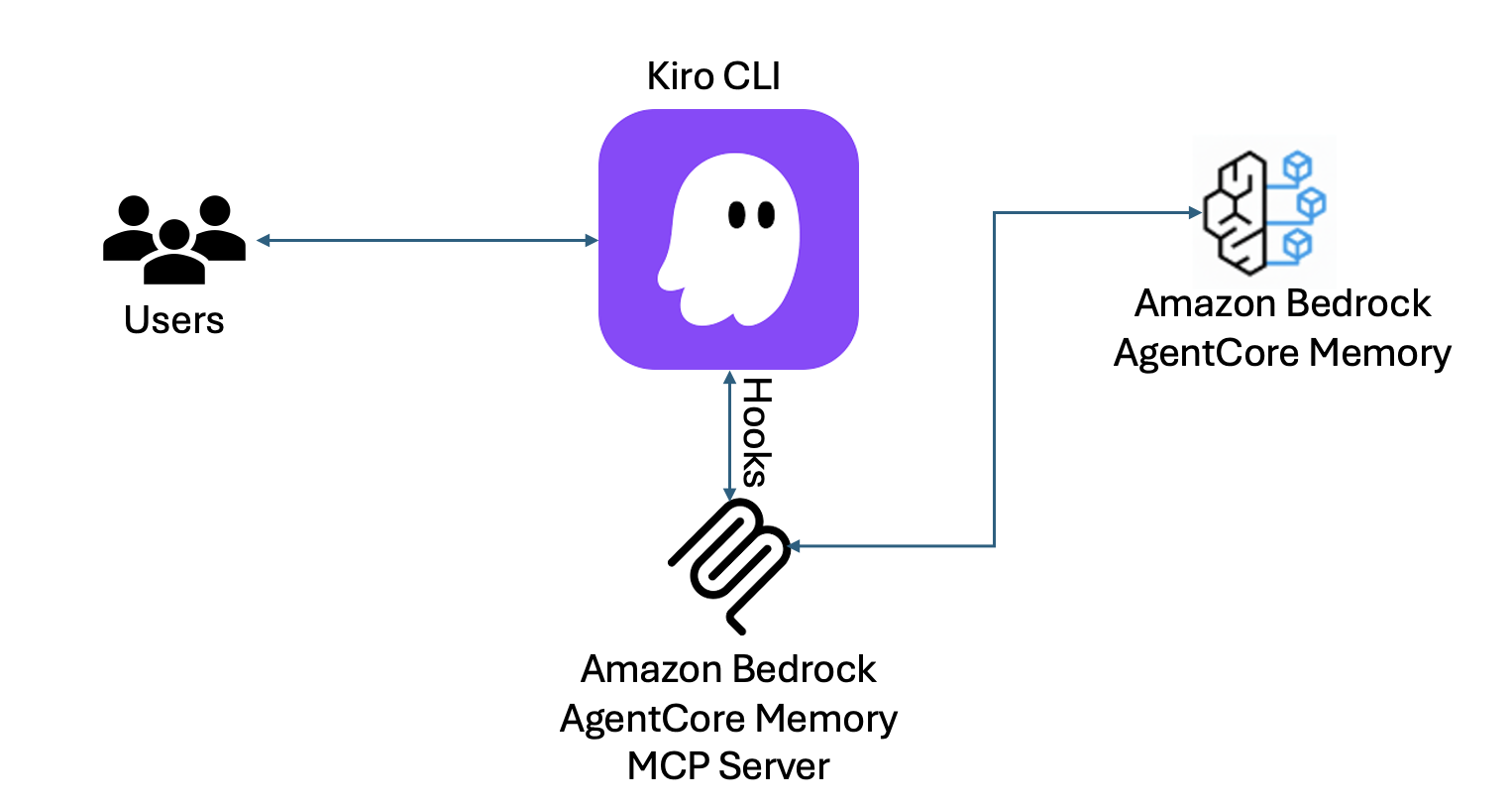
Kiro CLI тепер пропонує розширену функцію запам'ятовування діалогів завдяки інтеграції з Amazon Bedrock AgentCore Memory. Спеціально розроблений сервер MCP забезпечує збереження контексту та персоналізований досвід під час різних сеансів.
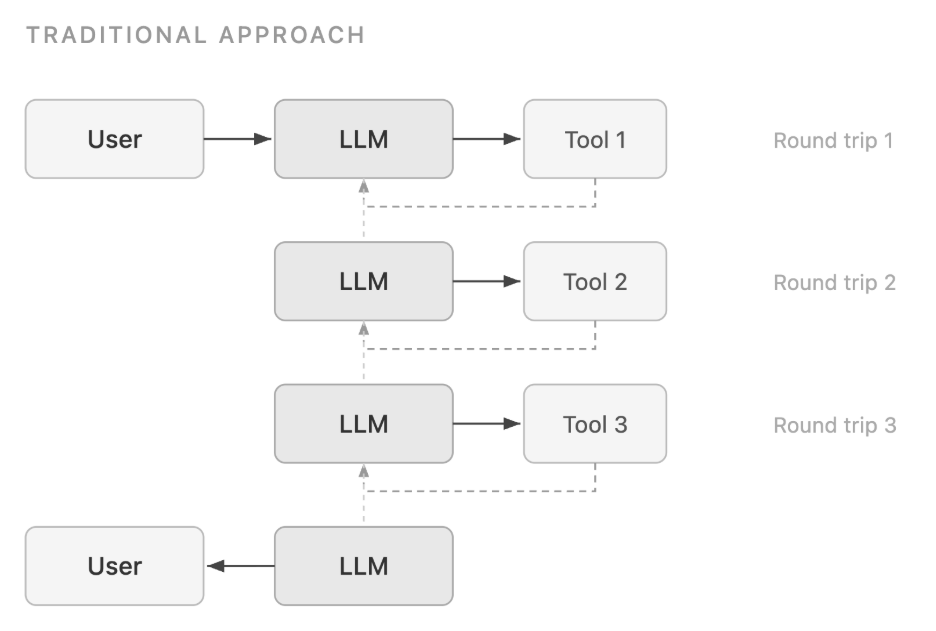
Програмне виклик інструментів (PTC) зменшує затримку та споживання токенів, дозволяючи великим мовним моделям писати код, який програмно викликає декілька інструментів у ізольованому середовищі виконання. PTC ефективно застосовується для обробки даних, чисельних обчислень, оркестрування процесів та у сценаріях, що вимагають дотримання конфіденційності, пропонуючи незалежне від моделі рішення д...

Amazon SageMaker Feature Store пропонує нові можливості, зокрема інтеграцію з Lake Formation та властивості таблиць Iceberg. Це допомагає організаціям оптимізувати контроль доступу та зменшити витрати на зберігання моделей машинного навчання.
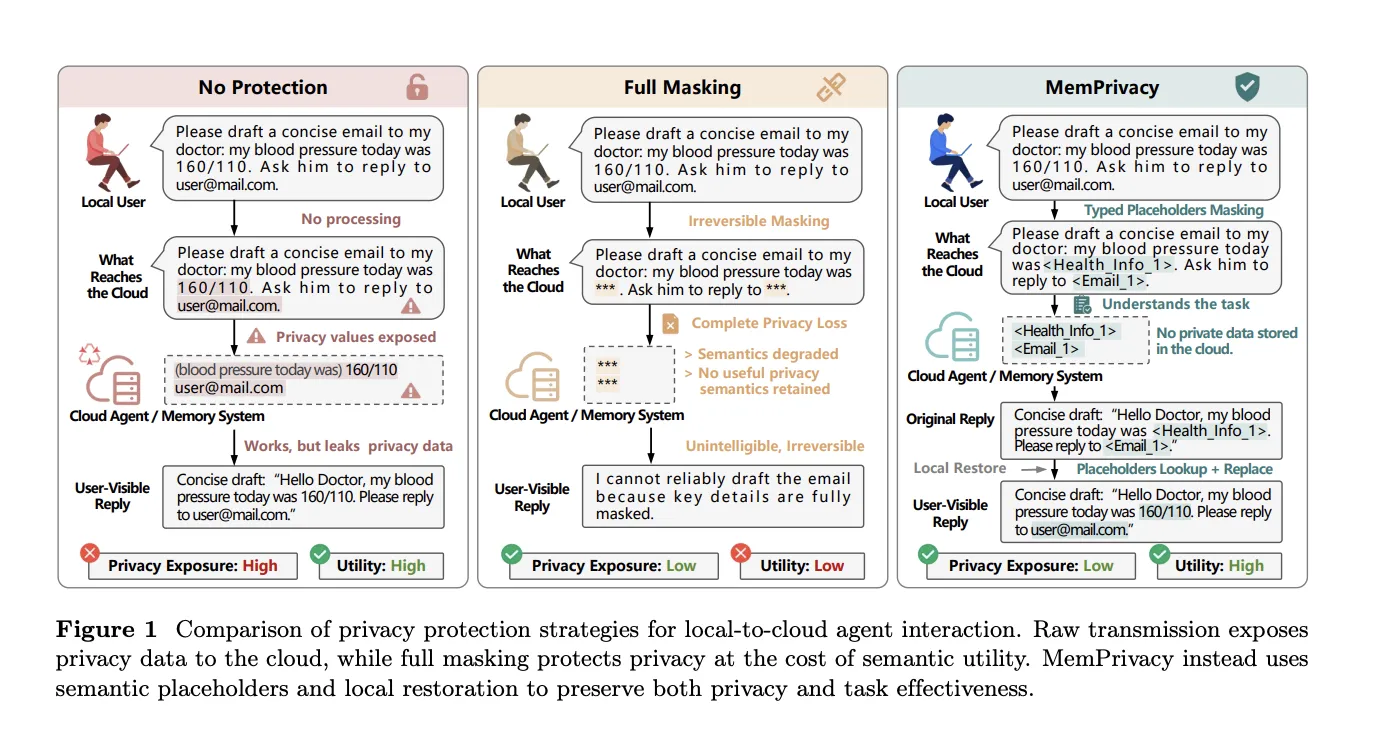
Технологія MemPrivacy від MemTensor, компанії HONOR Device та Університету Тунцзі замінює приватні дані користувачів структурованими токенами, щоб забезпечити захист конфіденційності під час управління пам'яттю в хмарі без втрати функціональності чи якості відгуку. Ця локальна система оборотної псевдонімізації гарантує збереження семантичної цілісності взаємодій, одночасно захищаючи конфіденці...
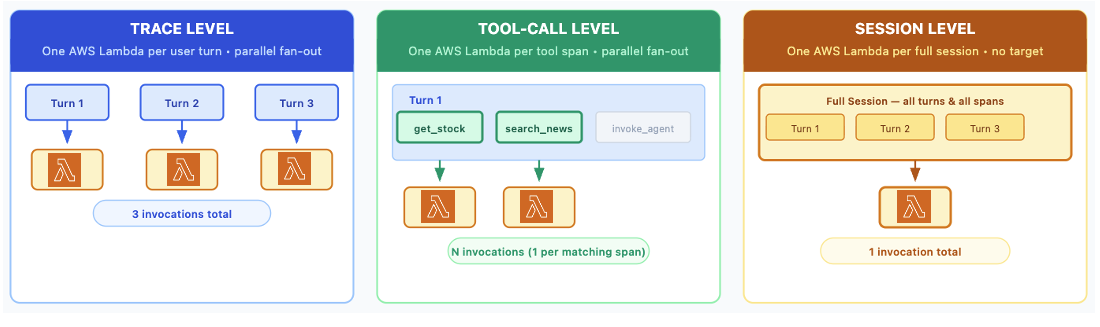
Amazon Bedrock AgentCore Evaluations пропонує індивідуальні оцінювачі на основі коду для аналізу агентських додатків у спеціалізованих галузях, таких як фінансові послуги. Ці оцінювачі забезпечують контроль над логікою підрахунку балів, що дозволяє проводити індивідуальну оцінку якості агентів та забезпечує безперебійну інтеграцію в робочі процеси розробки.

Компанія NVIDIA представляє NVFP4 для навчання з використанням 4-бітної плаваючої коми, що забезпечує точність 62,58 % на моделі Mamba-Transformer, перевершивши базовий показник FP8. NVFP4 оптимізує динамічний діапазон і точність, виконуючи операції GEMM із прискоренням у 2–3 рази порівняно з
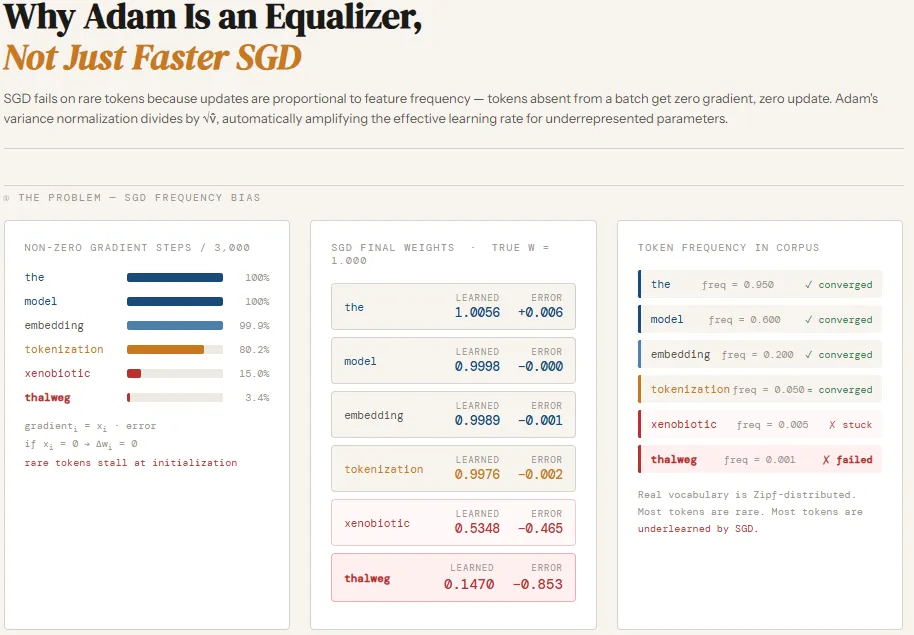
Моделі мов стикаються з проблемами оптимізації через нерівномірний розподіл лемматів. Адаптивна оптимізація Adam допомагає рідкісним лемматам навчатися швидше, ніж при використанні стандартного алгоритму SGD.
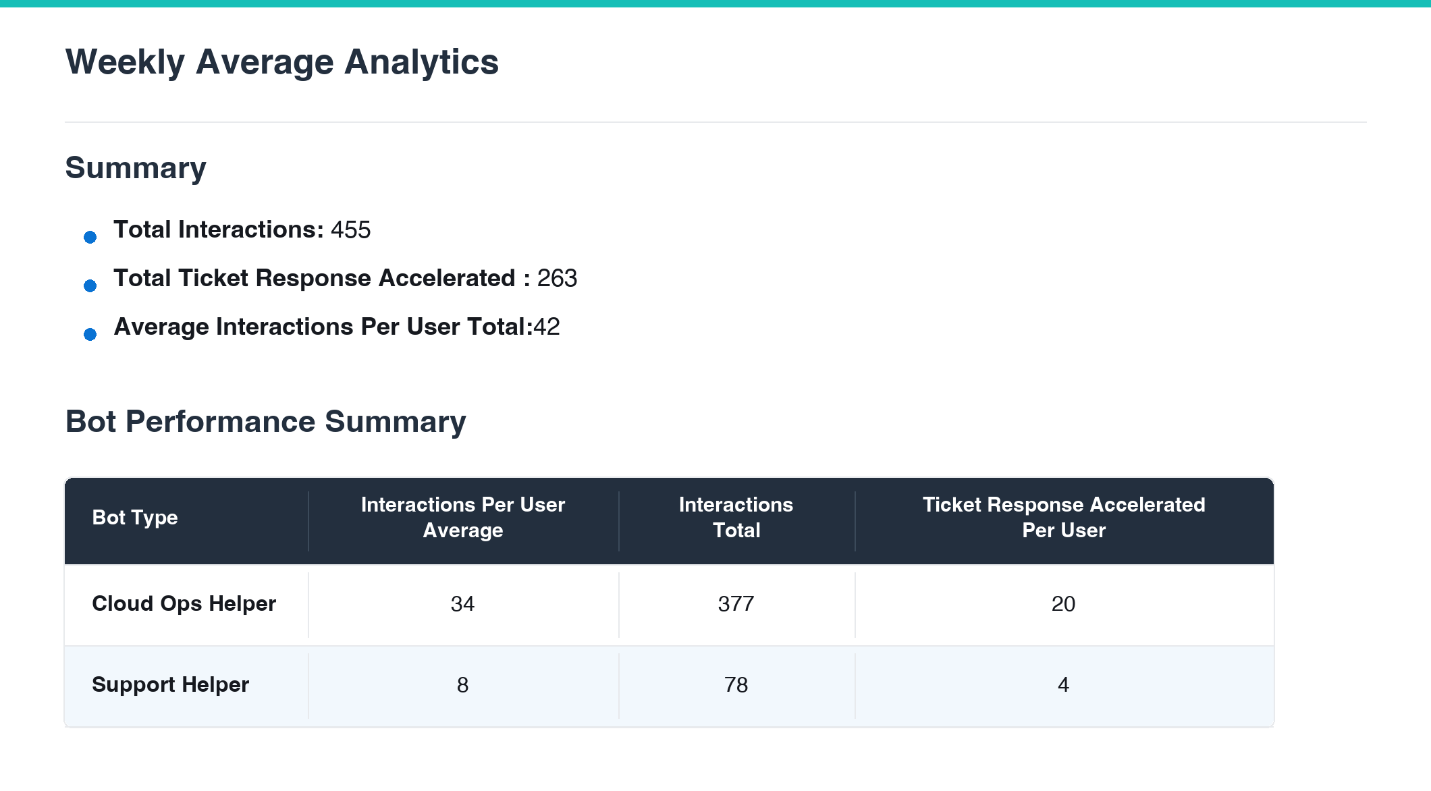
Aderant оптимізує роботу служби підтримки за допомогою Amazon Quick, скорочуючи час пошуку на 90% та прискорюючи обробку документації на 75%. Функції на базі штучного інтелекту об'єднують пошук у шести системах, що дозволяє інженерам надавати підтримку швидше та оперативніше.
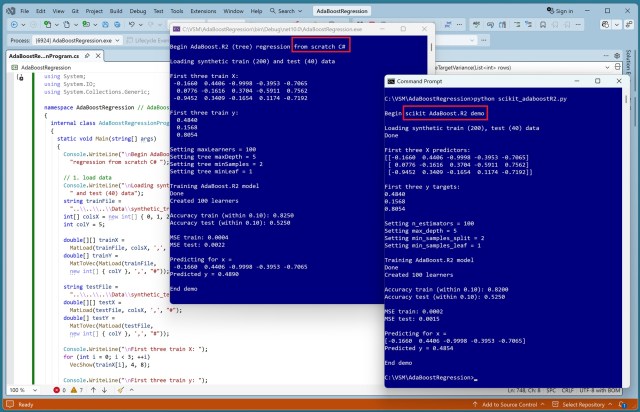
Регресія AdaBoost використовує дерева рішень, навчені на зважених даних, для підвищення точності прогнозів. Результати свідчать про перенавчання: висока точність на навчальних даних, але нижча точність на нових тестових даних.