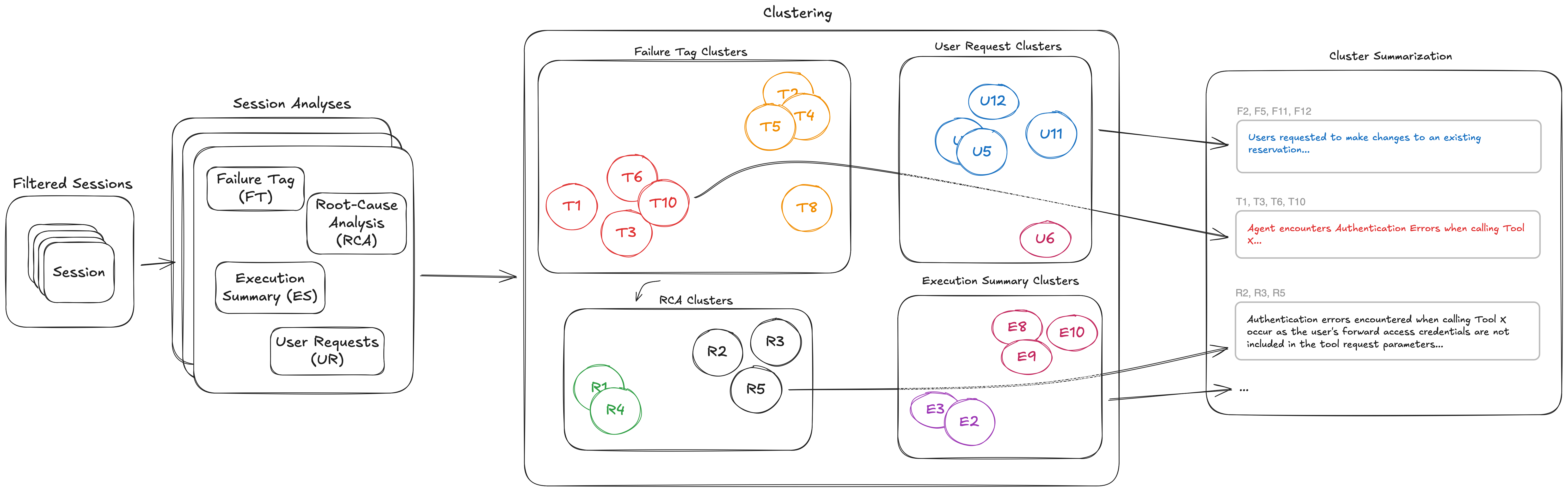
Оптимізація Amazon Bedrock AgentCore надає інформацію для виявлення та пріоритезації проблем у роботі AI-агентів, навіть тих, які проявляються непомітно. Вона переводить акцент з реактивного аналізу журналів на проактивне виявлення закономірностей, що допомагає швидко знаходити, розуміти та вирішувати проблеми. Інформація включає ранжування проблемних сценаріїв із визначенням першопричин та ана...

Дімітрі Берцекас, відомий професор кафедри електротехніки та комп'ютерних наук у Массачусетському технологічному інституті, помер у віці 83 років. Він був відомий своїми новаторськими дослідженнями в галузі оптимізації та тим, що готував майбутніх лідерів цієї сфери.
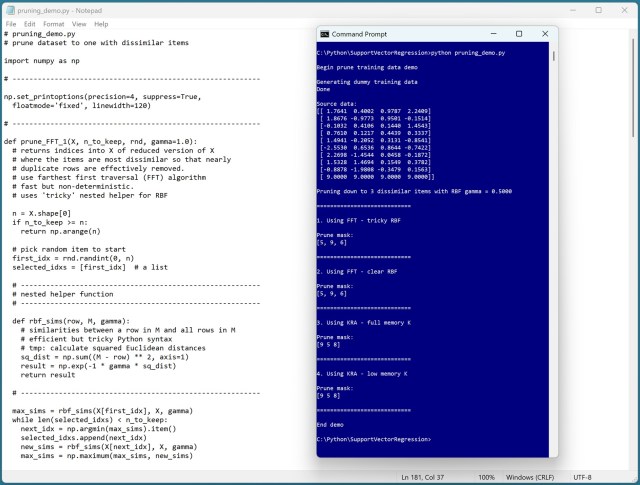
Унікальний виклик, пов'язаний зі стисненням навчальних даних за допомогою методу RBF-подібності, призвів до створення функцій обрізання FFT та KRA в Python. Функція FFT оптимізує процес, зосереджуючись на відмінностях, тоді як функція KRA ранжує елементи на основі середньої подібності для забезпечення чіткості.
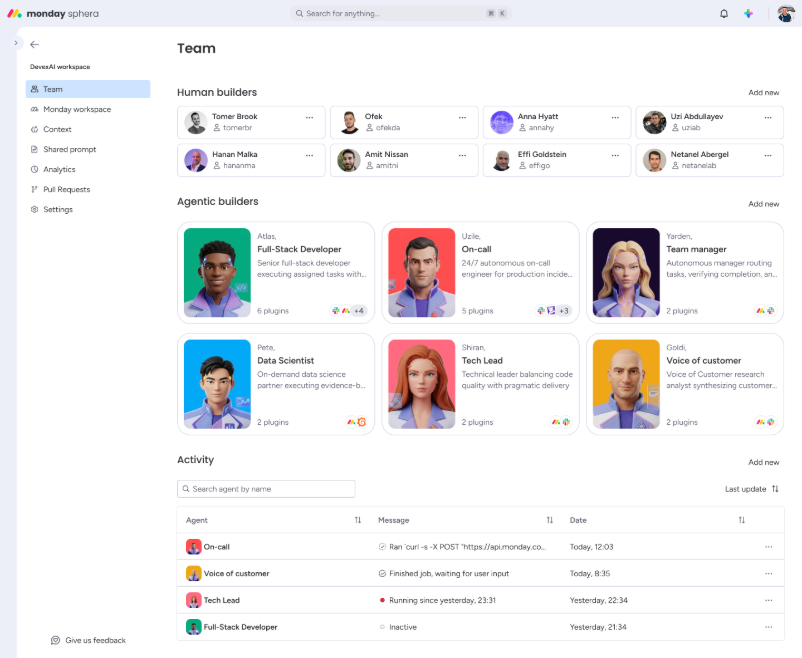
Штучні інтелекти, що працюють у команді на платформі Amazon Bedrock в компанії monday.com, збільшили продуктивність роботи відділу зв'язків з громадськістю більш ніж на 50%, використовуючи інструменти штучного інтелекту для кодування у великій базі коду, яка існує вже десять років. Агенти в monday.com є повністю автономними та працюють разом із людьми як члени команди, а не просто як інструмент...

Генеральний директор NVIDIA, Дженсен Хуанг, запустив потужну платформу штучного інтелекту в Навігаційній післядипломній школі, що дозволяє студентам і викладачам отримувати доступ до обчислювальних ресурсів великого масштабу для реальних застосувань, таких як прогнозування погоди та кібербезпека. Співпраця з NPS спрямована на підготовку лідерів у галузі технологій штучного інтелекту, приділяючи...

Платформа NVIDIA Vera Rubin, що має гігантські масштаби, нарощує виробництво за підтримки партнерів, таких як CoreWeave та Microsoft Azure. Завдяки тісній співпраці в процесі розробки чіпів і систем, створюються ефективні фабрики з штучним інтелектом, оснащені спеціалізованими мережевими рішеннями, що дозволяє заощаджувати час на налаштування та споживання води.
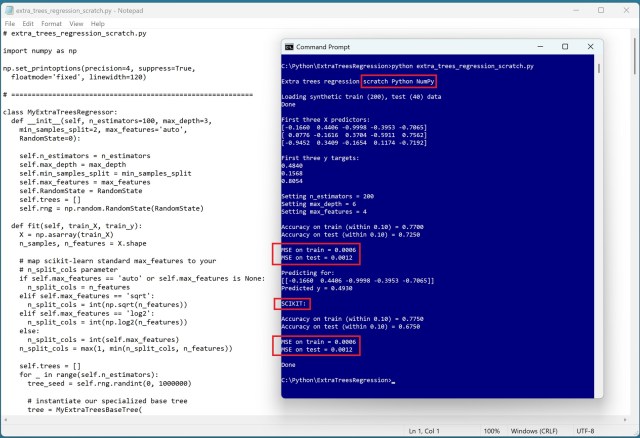
Метод регресії "Extra Trees" використовує випадкові дерева рішень для точного прогнозування значень. Реалізація цього методу з нуля може дати результати, близькі до модуля scikit-learn.

Моделі Amazon Nova 2 чудово справляються із завданнями, що вимагають логічного мислення. Технологія Self-Distilled Reasoning покращує продуктивність без втрати попередніх знань.

Розробники тепер можуть продовжити термін служби своїх пристроїв AWS DeepRacer, встановивши власні операційні системи за допомогою нещодавно випущеного завантажувача. Це дозволяє експериментувати з сучасними дистрибутивами Linux та власними програмними середовищами. Завантажувач забезпечує розробникам можливість самостійно налаштовувати пристрій, дозволяючи встановлювати сторонні дистрибутиви т...

На конференції SIGGRAPH компанія NVIDIA демонструє останні досягнення у сфері штучного інтелекту, зокрема в нейронному рендерингу, моделюванні світу та методах симуляції. Керівники NVIDIA розповідають про те, як ці технології революціонізують створення та використання цифрових світів у різних галузях промисловості.
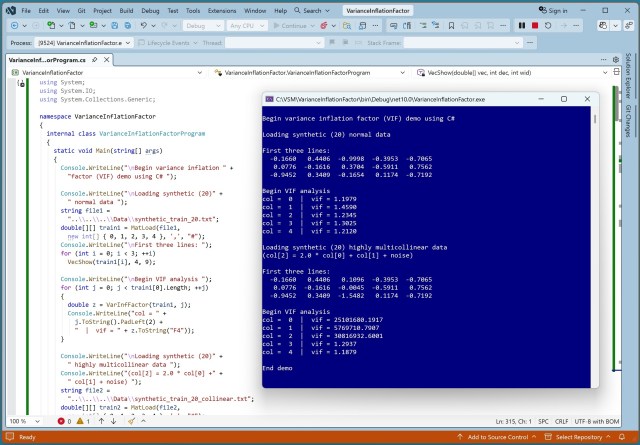
Наявність мультиколінеарних даних для навчання впливає на інтерпретованість моделі. VIF допомагає виявити рівні кореляції. Перенесення демонстраційного коду з Python на C# потребувало реалізації класу лінійної регресії та допоміжних функцій.
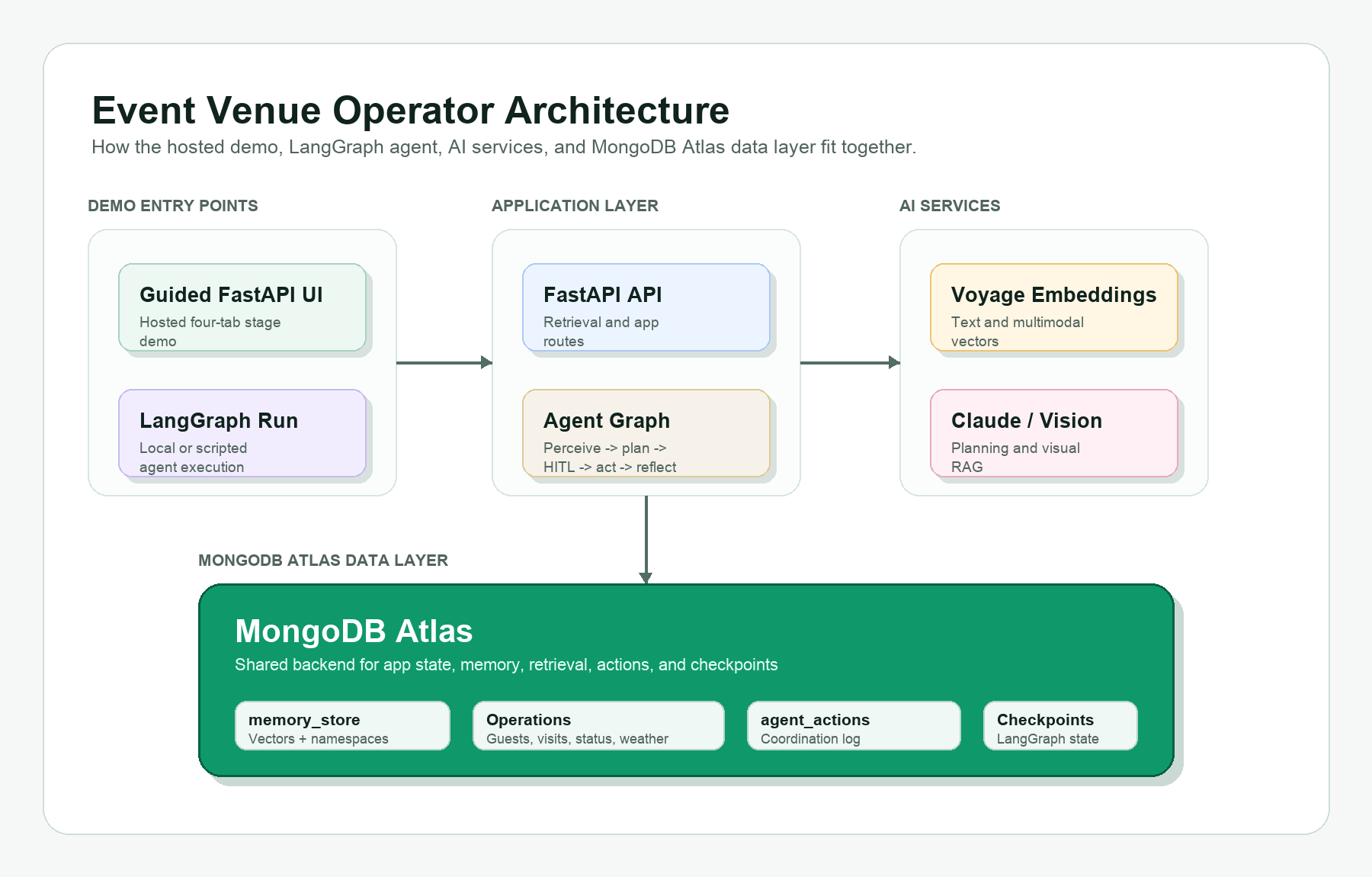
Створіть демонстраційну версію системи управління заходами, використовуючи MongoDB Atlas, вбудовані моделі Voyage AI та LangGraph. Дослідіть складність організації преміального тенісного турніру з високими очікуваннями від фанатів і потенційними ризиками, пов'язаними з погодою.
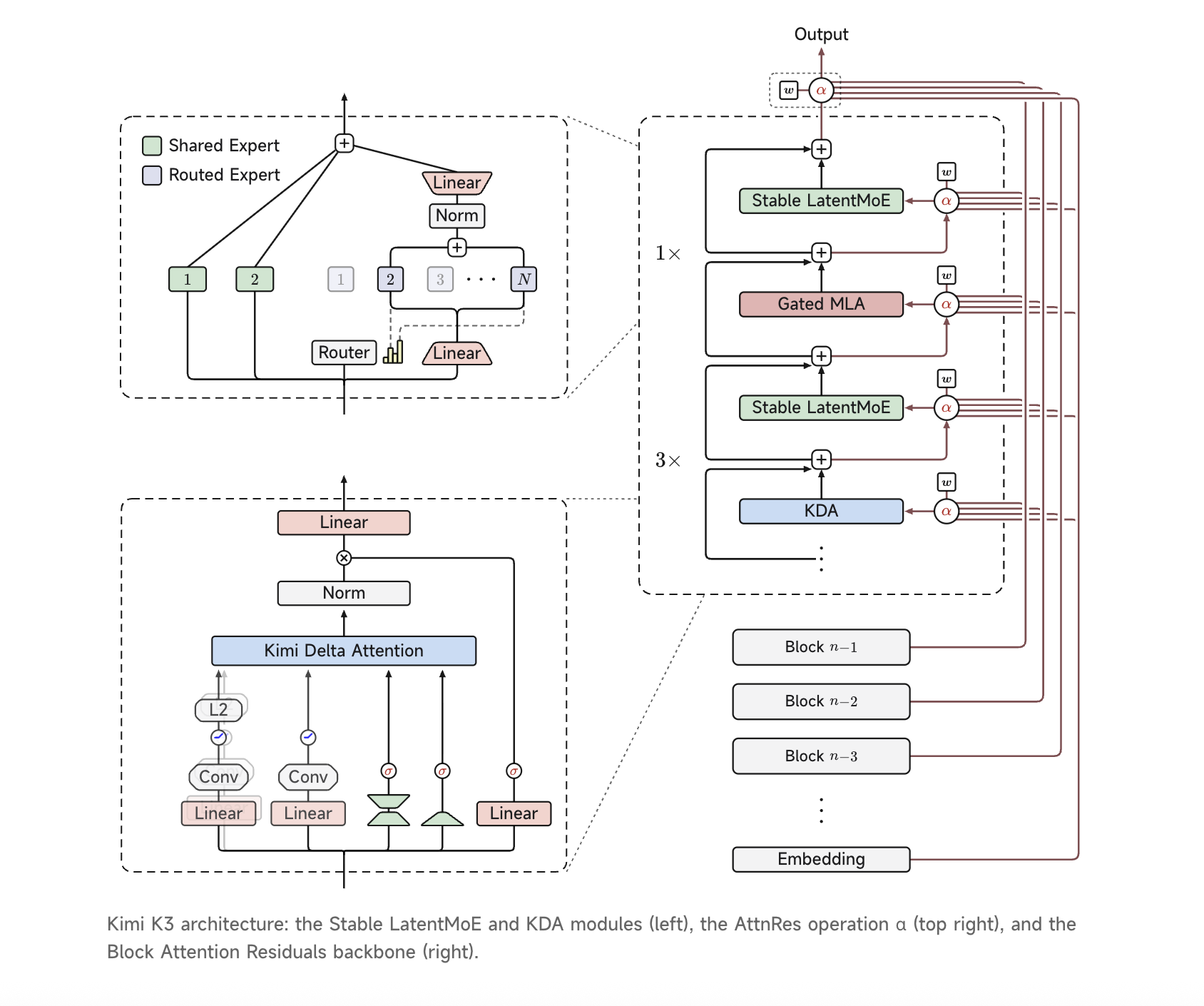
Компанія Moonshot AI представила модель Kimi K3, яка має 2,8 трильйона параметрів і володіє унікальними характеристиками. Модель K3 перевершує попередні моделі за розміром та ефективністю, але поступається пропріетарним моделям за продуктивністю.
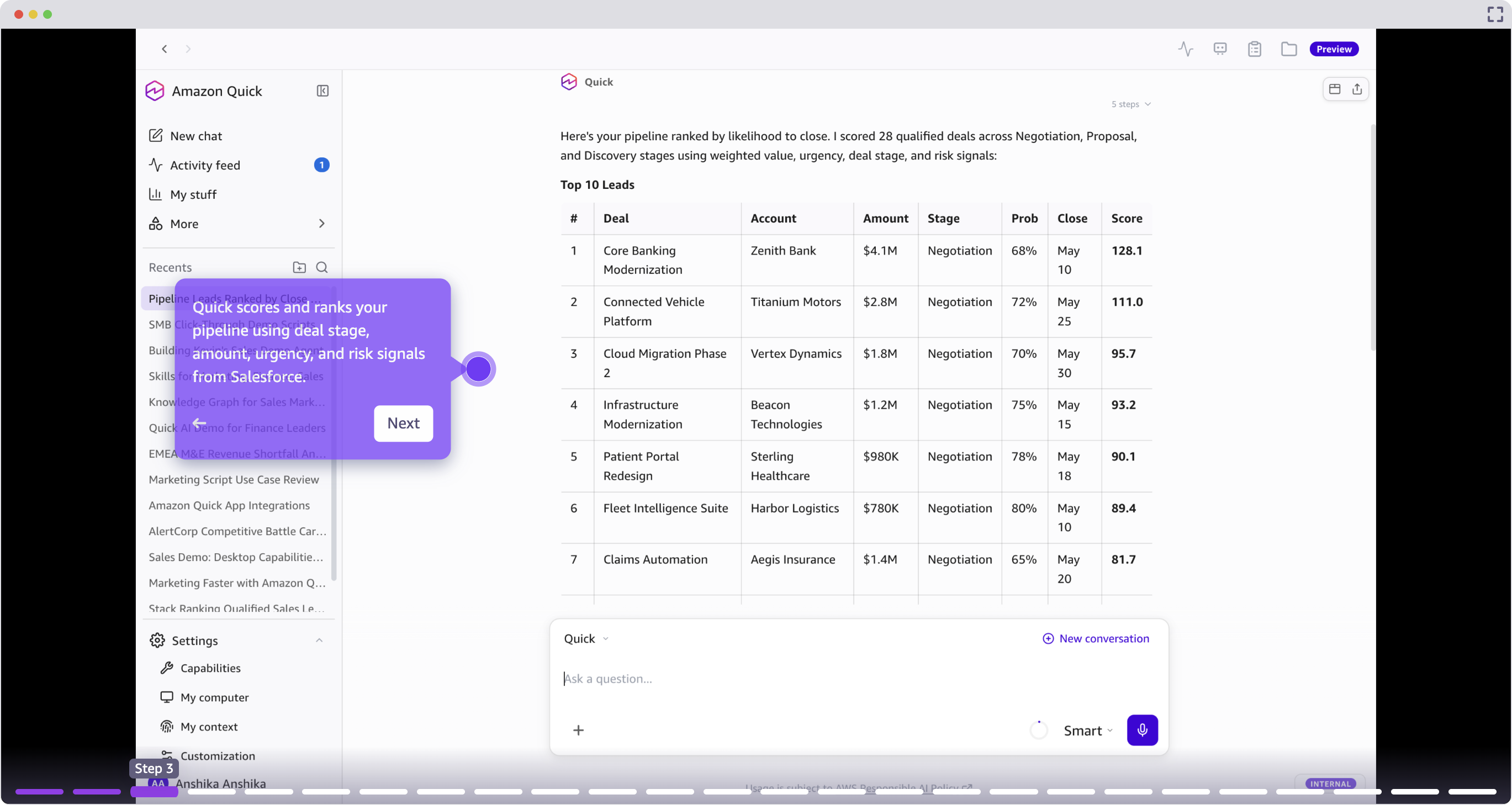
Amazon Quick – це AI-асистент, який допомагає менеджерам з продажу приділяти більше часу продажам і менше – адміністративним завданням. Такі компанії, як 3M та AWS, вже використовують Quick для визначення найбільш перспективних клієнтів і швидшого укладання угод.

Різноманітні інтереси Бейлі Фланіган привели її від медицини до музики, а потім до досліджень у галузі обчислювальної демократії. Її шлях через різні дисципліни в провідних навчальних закладах формує її новаторський підхід до змістовної участі в демократичних процесах.