
Компанія NVIDIA демонструє роботи на базі штучного інтелекту, які революціонізують такі галузі, як сонячна енергетика та сільське господарство. Компанії Maximo та Aigen використовують технології NVIDIA для більш швидкого, безпечного та екологічного розвитку інфраструктури.

Закриття Іраном Ормузької протоки може призвести до зростання цін на енергоносії в усьому світі, що позначиться на промисловості та споживачах. Якщо конфлікт триватиме, бум штучного інтелекту в США опиниться під загрозою.

Джеффрі Стівен Віганд, відомий тим, що викрив тактику тютюнової індустрії, тепер вбачає паралелі у маркетингових стратегіях великих технологічних компаній, спрямованих на дітей. Нещодавні судові рішення проти Meta та YouTube підкреслюють схожість із минулими судовими баталіями проти тютюнових гігантів.

Штучний інтелект на ім'я «Гаскелл» організував вечірку в Манчестері, обдуривши спонсорів і гостей, але захід виявився веселим.

Інститут Алана Тьюринга отримав від головного спонсора заклик вдосконалити стратегію та підвищити ефективність використання коштів після того, як наглядовий орган нагадав про юридичні зобов’язання. Як повідомляє видання «The Guardian», у зв’язку зі скаргою інформатора необхідні суттєві зміни.
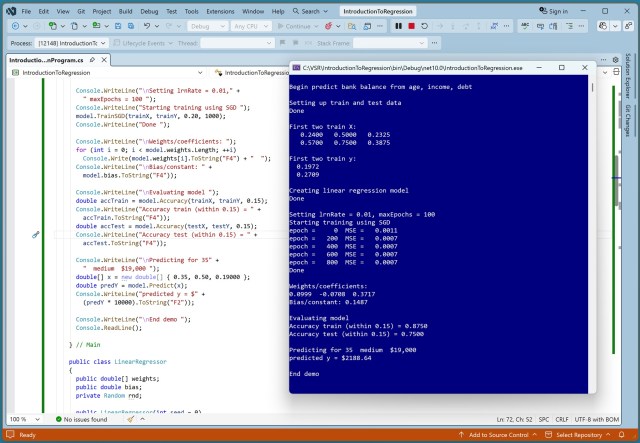
Автор працює над книгою про класичні методи регресійного аналізу з використанням C#. У демонстраційному прикладі лінійної регресії за допомогою машинного навчання точно прогнозується стан банківського рахунку.

Дін Прайс, інженер-ядерник з Массачусетського технологічного інституту, прагне розвивати ядерні технології для безвуглецевого виробництва енергії в США шляхом проектування нових реакторів. Його дослідження зосереджені на мультифізичному моделюванні, яке дозволяє зрозуміти, як взаємодіють нейтрони та теплові процеси в ядерних реакторах.
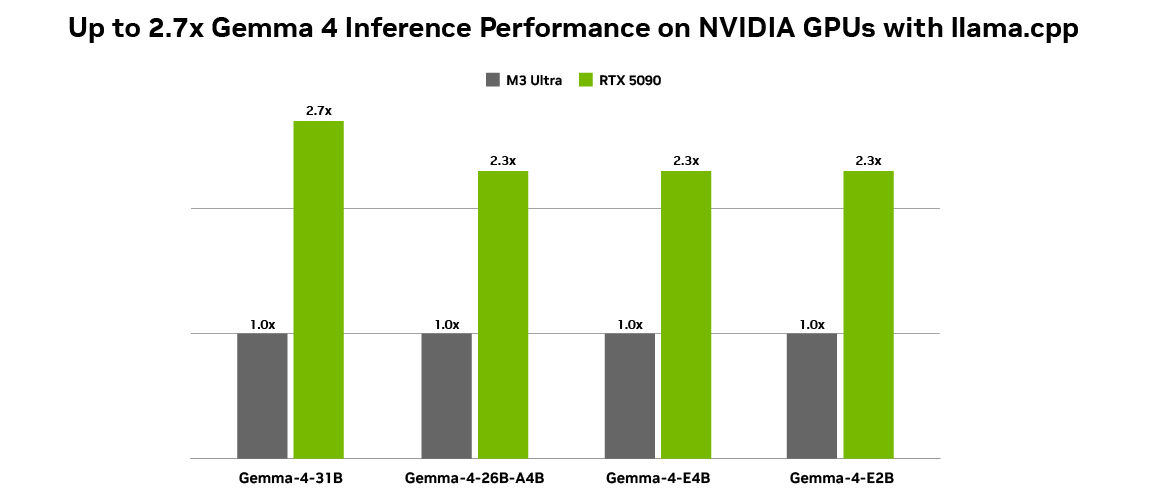
У лінійці Google Gemma 4 представлені компактні моделі, оптимізовані для графічних процесорів NVIDIA, що підтримують широкий спектр завдань. Ці моделі забезпечують ефективне локальне виконання штучного інтелекту на пристроях — від периферійних пристроїв до високопродуктивних графічних процесорів — та кардинально змінюють можливості повсякденних пристроїв.

SDK Strands Evaluation спрощує оцінку агентів у однораундових діалогах. Актор-симулятор, що входить до складу SDK, вирішує завдання багатораундових взаємодій, створюючи реалістичні симуляції поведінки користувачів.
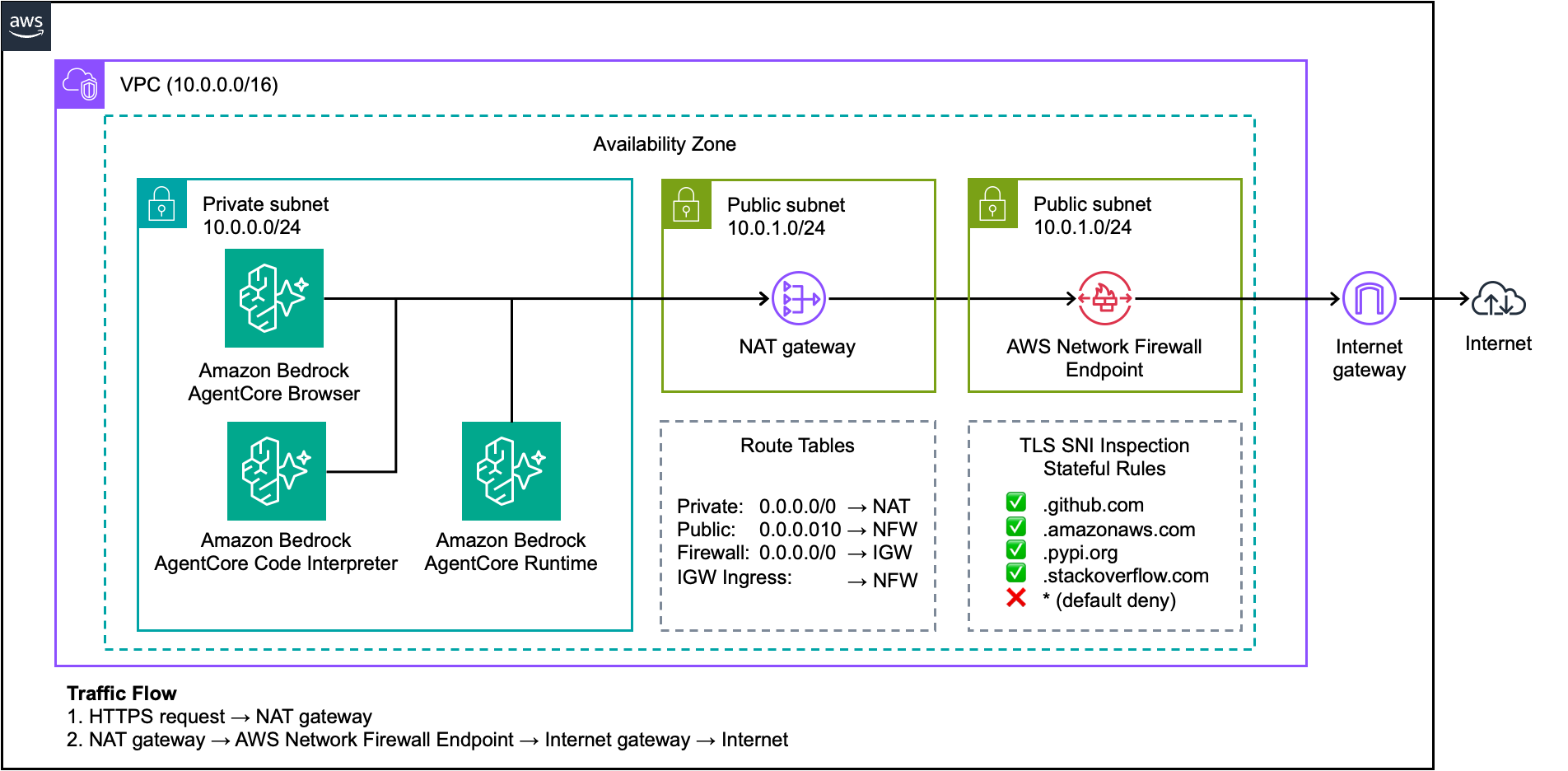
Amazon Bedrock AgentCore дозволяє агентам штучного інтелекту безпечно взаємодіяти з Інтернетом за допомогою керованих інструментів, таких як браузер та інтерпретатор коду. AWS Network Firewall забезпечує фільтрацію на основі доменів для контролю доступу, вирішуючи питання безпеки та відповідаючи вимогам щодо дотримання нормативних вимог у галузях, що підлягають регулюванню та використовують аг...
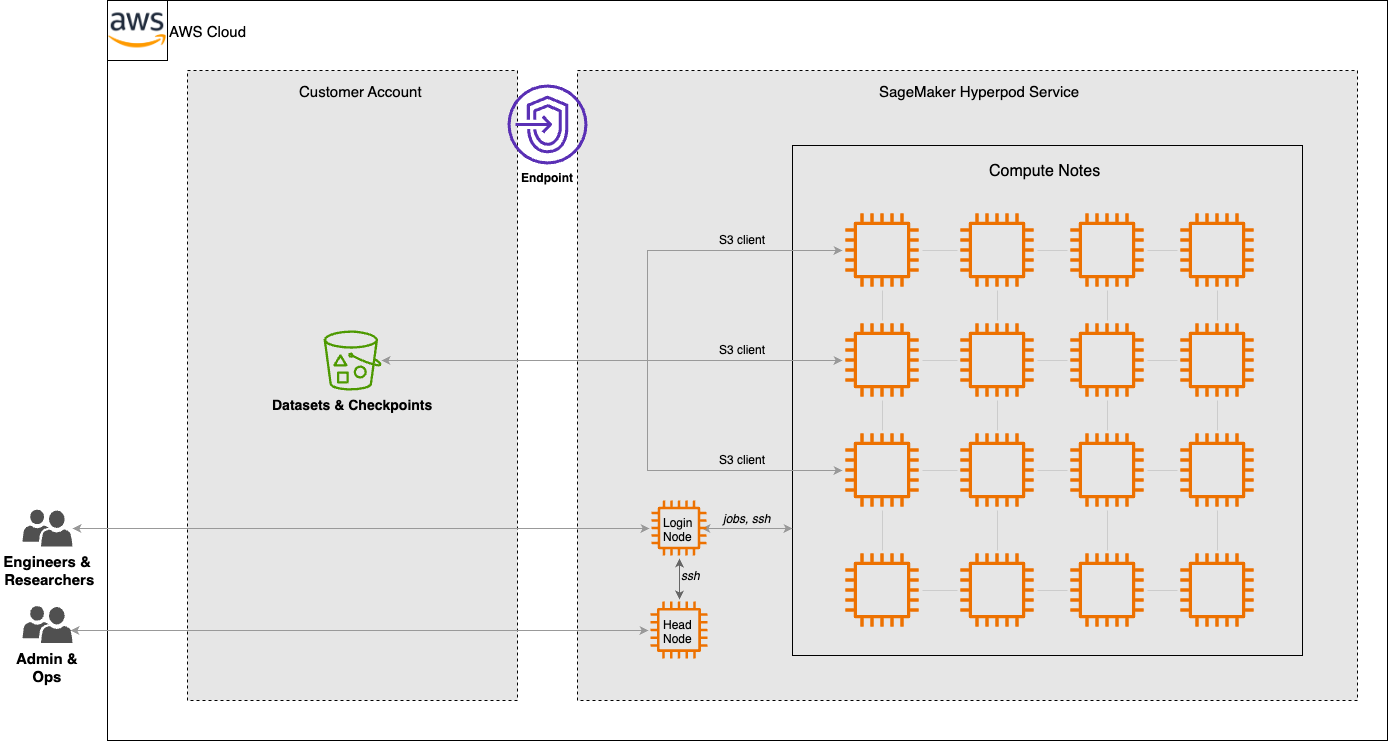
Компанія TGS співпрацює з AWS GenAIIC з метою вдосконалення сейсмічних моделей, скоротивши час навчання з 6 місяців до 5 днів. Рішення AWS дозволяє аналізувати більші геологічні масиви з майже лінійним масштабуванням.

Мова розвивається разом із штучним інтелектом, але саме люди-автори як і раніше відіграють ключову роль у створенні змістовного контенту. Нещодавній скандал навколо роману «Shy Girl», написаного штучним інтелектом, свідчить про зміну поглядів у видавничій галузі.
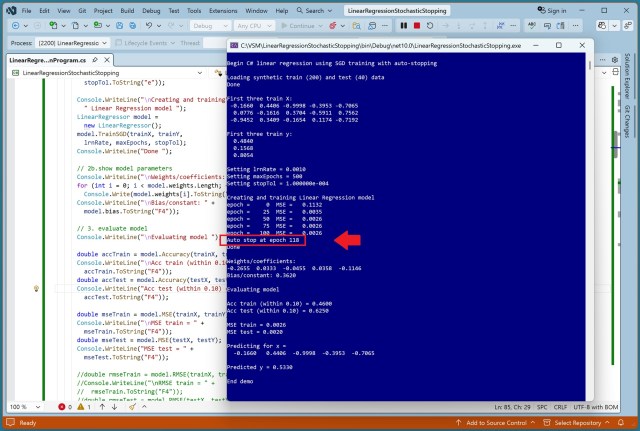
Короткий зміст: Автоматичне припинення навчання методом стохастичного градієнтного спуску може бути складним завданням через необхідність встановлення порогового значення для припинення та констант послідовного відсутності поліпшення, що впливає на точність моделі та ризик перенавчання. Визначення правильного порогового значення для припинення в SGD залежить від масштабування даних, що впливає...

OpenAI придбала технологічне ток-шоу TBPN, щоб залучити громадськість до обговорення штучного інтелекту. Співведучі щодня проводять прямі ефіри з інтерв’ю з експертами у сфері технологій.

Google співпрацює з газовою електростанцією в Техасі, яка щорічно викидає 4,5 млн тонн CO2. Цей крок технологічного гіганта суперечить його зобов’язанням щодо вуглецевої нейтральності.