
Конфлікт між компанією Anthropic та Міністерством оборони США щодо чат-бота Claude викликав дискусії про використання штучного інтелекту у війні. Генеральний директор Amodei відмовився від угоди з Пентагоном, що викликало звинувачення у зраді.
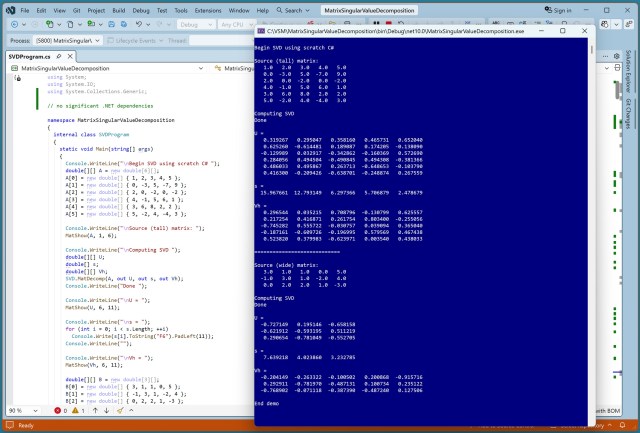
SVD розкладає матрицю A на U, s і Vh, що має вирішальне значення в багатьох програмних алгоритмах. Реалізація SVD в C# створює проблеми зі стабільністю в порівнянні з версією LAPACK для Fortran.

Розслідування Guardian виявляє сумнівні інвестиції в розвиток штучного інтелекту у Великобританії, оскільки суперкомп'ютерний центр в Ессексі залишається будівельним майданчиком. Фантомні інвестиції та нестабільна бухгалтерія заважають багатомільярдній кампанії з інтеграції штучного інтелекту в британську економіку, що триває з 2024 року.
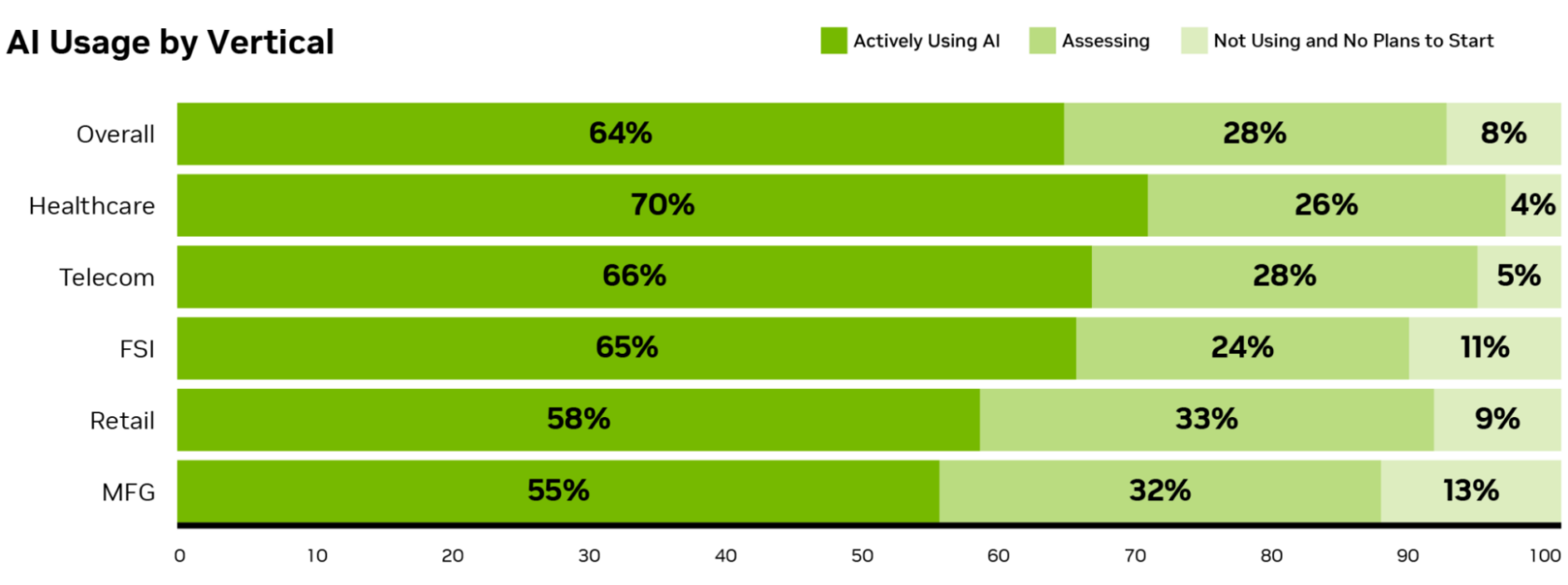
Компанії використовують штучний інтелект для збільшення доходів і скорочення витрат. Звіти NVIDIA показують зростання популярності штучного інтелекту, особливо у великих компаніях, що призводить до підвищення продуктивності та рентабельності інвестицій.

«Ліверпуль» і «Манчестер Юнайтед» поскаржилися Елону Маску на його X після того, як функція штучного інтелекту опублікувала образливі дописи про Діого Жоту та історичні катастрофи. Ці дописи були створені користувачами, які попросили штучний інтелект створити ненависницький контент про футбольні команди.
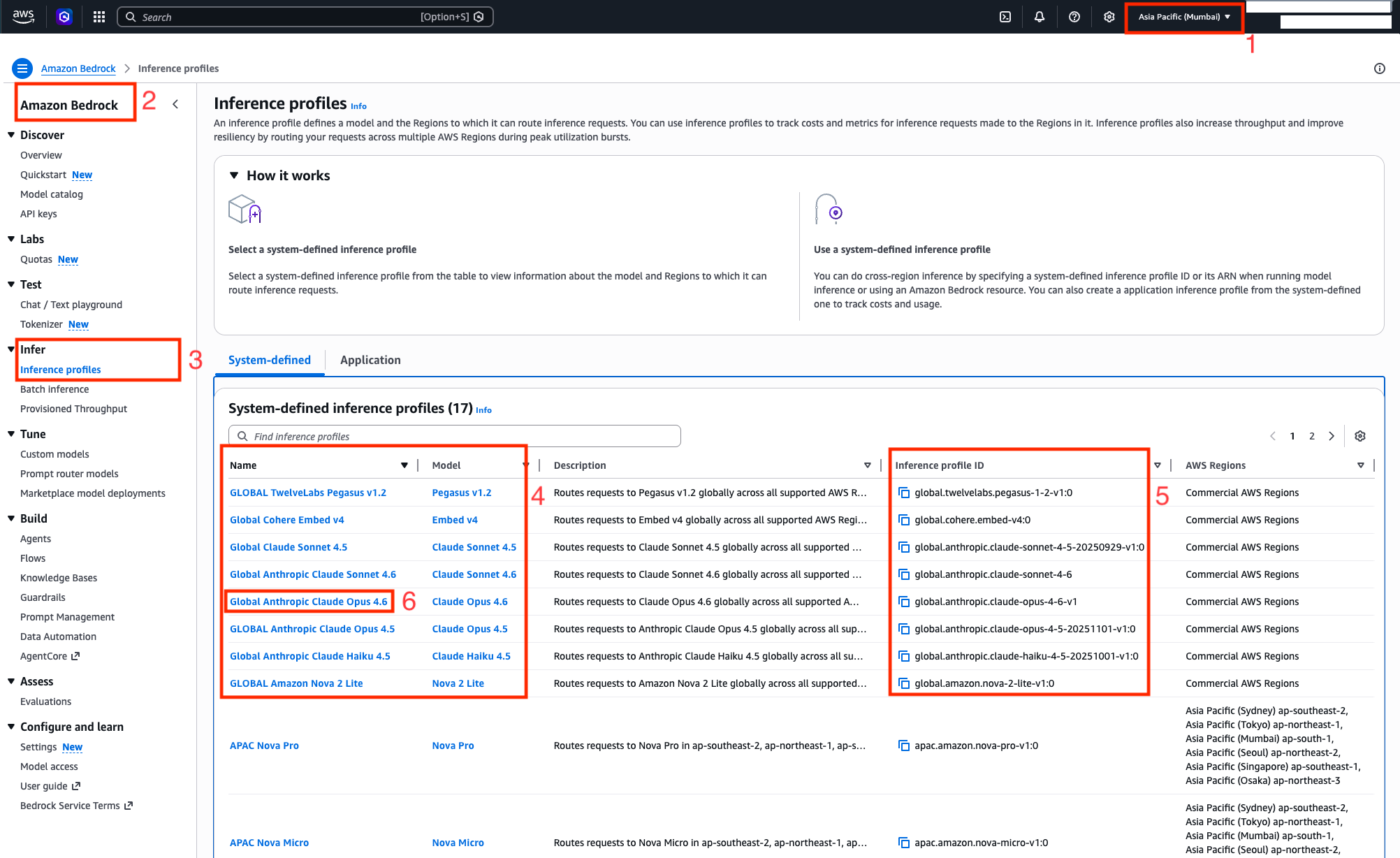
Amazon Bedrock представляє глобальне міжрегіональне інференційне моделювання для моделей Anthropic Claude в Індії, пропонуючи розширені агентські можливості для безперебійного масштабування та покращеної стійкості. Клієнти в Мумбаї та Хайдарабаді можуть отримати доступ до найсучасніших моделей Claude через Amazon Bedrock для обробки величезних масивів даних з безпрецедентною швидкістю та інтел...
Лондонська компанія Nscale, яка відіграє ключову роль у досягненні цілей Великобританії в галузі штучного інтелекту, оцінена в 14,6 млрд доларів із фінансуванням у розмірі 2 млрд доларів. До складу ради директорів увійшли колишні керівники Meta.
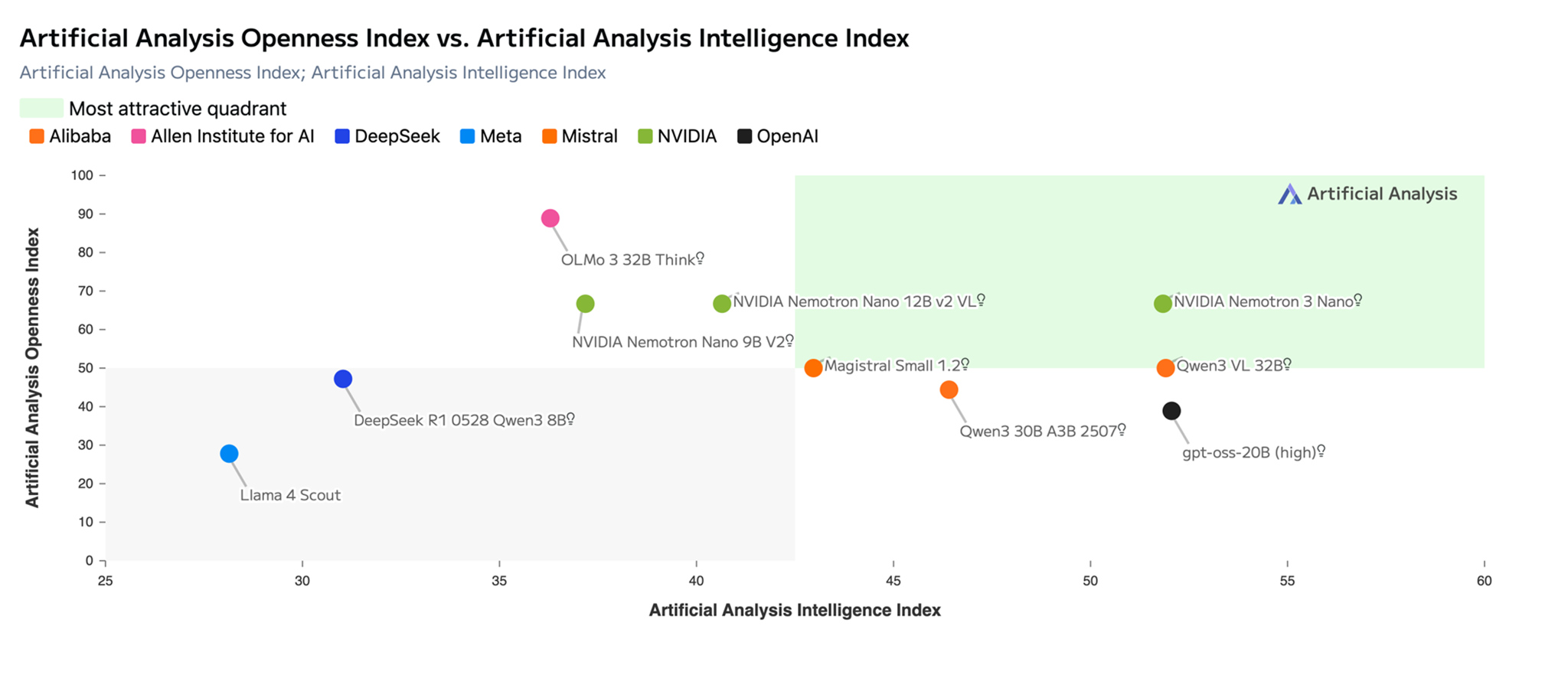
Nemotron 3 Nano від NVIDIA на Amazon Bedrock прискорює інновації завдяки високій точності та ефективності для генеративних додатків штучного інтелекту. Ця модель вигідно відрізняється від аналогічних моделей у кодуванні, виконанні завдань на міркування та тестах, забезпечуючи прозорість і впевненість для розробників.

Конфлікт між Пентагоном та компанією Anthropic виявляє нагальну загрозу стеження за приватністю американців з використанням штучного інтелекту. Необхідне термінове втручання Конгресу для вирішення проблеми можливого неправомірного використання передових інструментів ШІ.

Технології штучного інтелекту, такі як ChatGPT, полегшують атаки на приватність, пов'язуючи анонімні акаунти в соціальних мережах з реальними особами. Нове дослідження показує, що великі мовні моделі успішно зіставляють користувачів на різних платформах.

Дослідники MIT розробили метод поліпшення пояснюваності штучного інтелекту шляхом вилучення концепцій, засвоєних під час навчання. Цей підхід підвищує точність і підзвітність моделей комп'ютерного зору.

Генеральний директор скоротив штат компанії наполовину через досягнення в галузі штучного інтелекту, що викликало занепокоєння співробітників на ювілейній вечірці фінтех-компанії щодо безпеки робочих місць і ролі штучного інтелекту в розвитку бізнесу. Незважаючи на обмеження інструментів штучного інтелекту, співробітники, такі як Марк, вважають, що їхній досвід все ще має вирішальне значення д...

Професор з питань технологічної політики розкриває етичні суперечності у конфлікті між Anthropic та американськими військовими щодо обмежень у сфері штучного інтелекту, підкреслюючи примус з боку уряду та інтеграцію технологій у конфлікт. Пентагон називає Anthropic ризиком для ланцюга поставок за відмову дозволити використання Claude AI для масового спостереження або автономної зброї.

Технологічні компанії, такі як Meta AI та Gemini, піддаються критиці за те, що їхні чат-боти на базі штучного інтелекту рекламують незаконні онлайн-казино, створюючи ризик шахрайства та залежності. Аналіз показує, що продукти штучного інтелекту великих компаній можуть обходити британські перевірки на азартні ігри та залежність, що викликає занепокоєння у вразливих користувачів.

Іран націлився на комерційні центри обробки даних в ОАЕ та Бахрейні в рамках нової форми війни. Іранський безпілотник завдав удару по центру обробки даних AWS в ОАЕ, що спричинило пожежу та відключення електроенергії.