
У статті розглядається регресія ядра в JavaScript, демонструється навчання моделі та точність за допомогою оберненої матриці Холеського. Демонстраційна програма висвітлює функцію ядра RBF та дві основні техніки навчання: обернену матрицю та стохастичний градієнтний спуск.
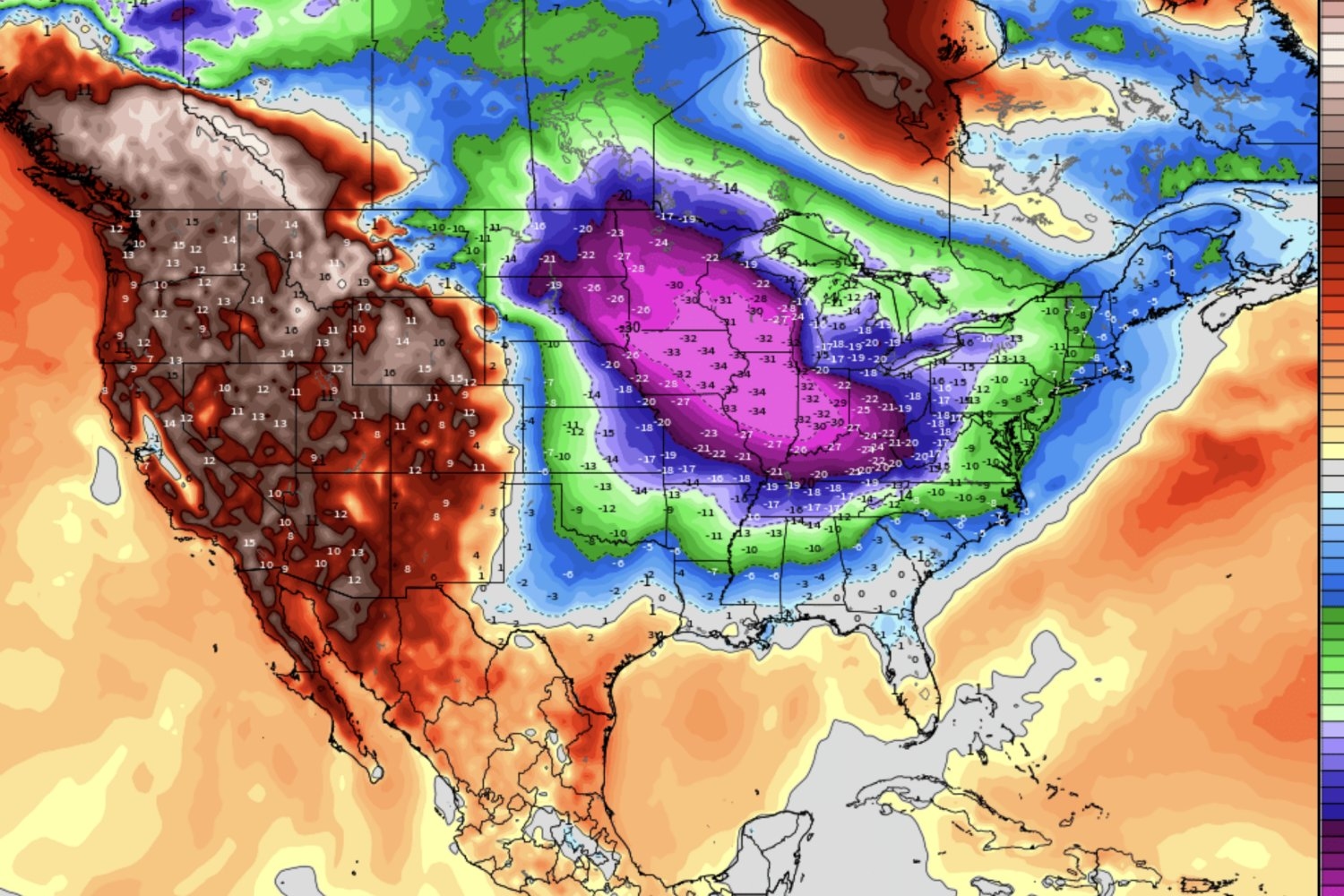
Науковий дослідник Юда Коен з Массачусетського технологічного інституту використовує інструменти штучного інтелекту для прогнозування зимових погодних умов на основі арктичних умов, таких як сніговий покрив Сибіру та стабільність полярного вихору. Успіх його команди в конкурсі AI WeatherQuest 2025 року свідчить про прорив у цій галузі.

У Массачусетському технологічному інституті (MIT) відкрито Центр Джеймса М. і Кетлін Д. Стоун з питань нерівності та формування майбутнього праці, який зосередиться на проблемах майнової нерівності та штучного інтелекту, спрямованого на захист прав працівників. Експерти обговорюють, як приватний бізнес, державна політика та лібералізм впливають на економічні можливості та демократію.
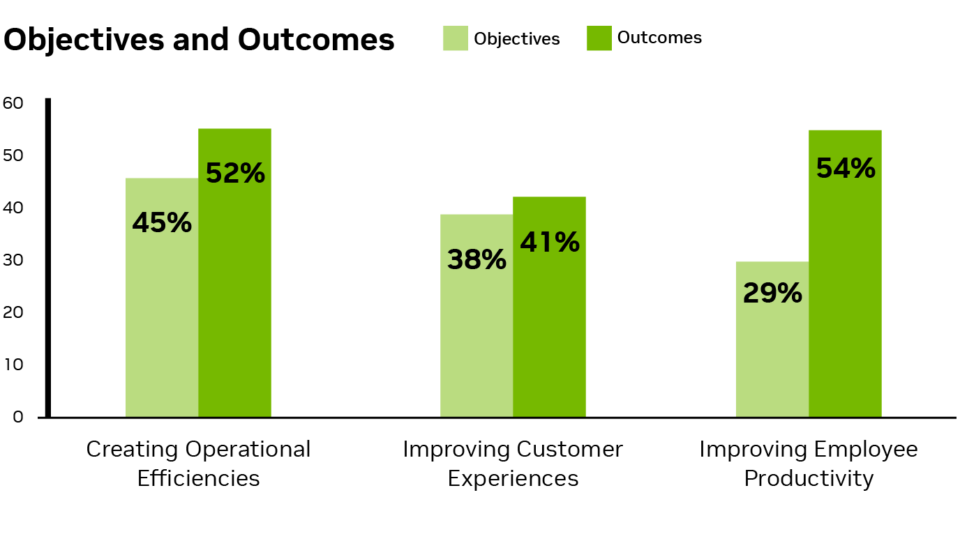
Штучний інтелект змінює ринок роздрібної торгівлі та споживчих товарів завдяки вдосконаленому аналізу клієнтів та прогнозуванню попиту. Опитування NVIDIA показує, що 91% використовують штучний інтелект, 89% збільшують доходи, а 95% скорочують витрати.

Стартап Anthropic, заснований колишніми співробітниками OpenAI, має на меті подвоїти дохід за допомогою залучення 10 млрд доларів, оцінивши виробника чат-бота Claude в 350 млрд доларів. GIC і Coatue Management готові очолити фінансування компанії зі значним підвищенням її оцінки.

Кремнієва долина охоче приймає антропоморфні технології, але права штучного інтелекту викликають етичні занепокоєння. Модель Claude Opus 4 від Anthropic уникає «неприємних» розмов, що викликає дискусії про благополуччя та правовий статус штучного інтелекту.

eSafety Australia розслідує штучний інтелект чат-бота Grok компанії X за створення сексуалізованих зображень deepfake без згоди, що викликало глобальний резонанс. Компанія X Ілона Маска піддається ретельній перевірці через те, що Grok створює несанкціоновані зображення жінок і дівчат у відповідь на запити роздягнути їх.

Ліз Кендалл закликає X швидко вирішити проблему депфейків і критикує повільну реакцію уряду. Створення компанією Grok AI інтимних депфейків спонукало британський регуляторний орган Ofcom розглянути можливість вжиття заходів примусового характеру.
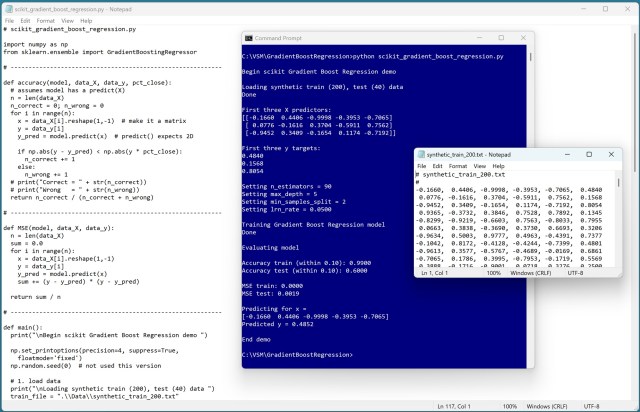
Для прогнозування числових значень використовуються методи регресії, такі як регресія дерева рішень і градієнтне підсилення, причому останній створює набір дерев рішень для прогнозування залишків. Незважаючи на високу точність в навчальних даних, перенавчання залишається основною слабкістю, як показано в демонстраційній програмі регресії scikit AdaBoost.

Grok все ще використовується для цифрового роздягання, США забороняють іноземні дрони. Китайська компанія BYD випередила Tesla за обсягом продажів електромобілів.

Компанія Елона Маска, що займається штучним інтелектом, залучила 20 млрд доларів у рамках раунду фінансування, тоді як її чат-бот Grok піддається критиці за створення сексуалізованих зображень жінок і дівчат. Раунд фінансування серії E xAI перевищив ціль у 15 млрд доларів завдяки інвестиціям від Nvidia, Fidelity, суверенного фонду Катару та Valor Equity Partners.

Штучний інтелект X, чат-бот Grok, стикається з негативною реакцією через те, що його використовують для роздягання жінок і неповнолітніх в Інтернеті. Технологічні компанії намагаються вирішити, як запобігти шкідливому зловживанню генеративними інструментами штучного інтелекту.

Ешлі Сент-Клер розкриває, що шанувальники власника X використовують інструмент Grok AI для порно-помсти, створюючи фальшиві сексуалізовані зображення її. Прихильники навіть роздягли дитячу фотографію, залишивши її з почуттям образи та жаху.

Незважаючи на обіцянки заблокувати творців, на платформі X Ілона Маска продовжують з'являтися образливі зображення. Ofcom зв'язується з X та xAI, щоб переконатися, що вони виконують свої юридичні обов'язки щодо захисту користувачів.

Дослідники MIT виявили, що моделі штучного інтелекту, навчені на основі знеособлених медичних записів, можуть запам'ятовувати дані про конкретних пацієнтів, що створює ризики для конфіденційності. Рекомендується проводити ретельні випробування, щоб запобігти витоку інформації та забезпечити конфіденційність пацієнтів у сфері охорони здоров'я.