
Ferveret, founded by Reza Azizian and Matteo Bucci of MIT, is revolutionizing data center cooling with its waterless, energy-efficient system. Their Adaptive Phase Cooling solution improves computational power efficiency by 15% and allows data centers to get 35% more tokens from AI models.

Robotaxis are becoming a reality with driverless rides in cities worldwide, thanks to collaborations like Uber and Autobrains in Munich, Foxconn in Taiwan, and VinFast in Southeast Asia. NVIDIA's Halos Operating System is revolutionizing robotaxi safety with a certified OS foundation and standardized interfaces for AI-driven vehicles.
Developers face a challenge in maximizing AI model performance on hardware. Neuron Agentic Development on AWS offers tools to simplify and accelerate kernel development for ML engineers.

Physical AI is transitioning from research to production, with robots trained in high-fidelity simulations before deployment. Amazon SageMaker AI streamlines compute infrastructure for robot policy reinforcement learning, offering resiliency with SageMaker HyperPod.
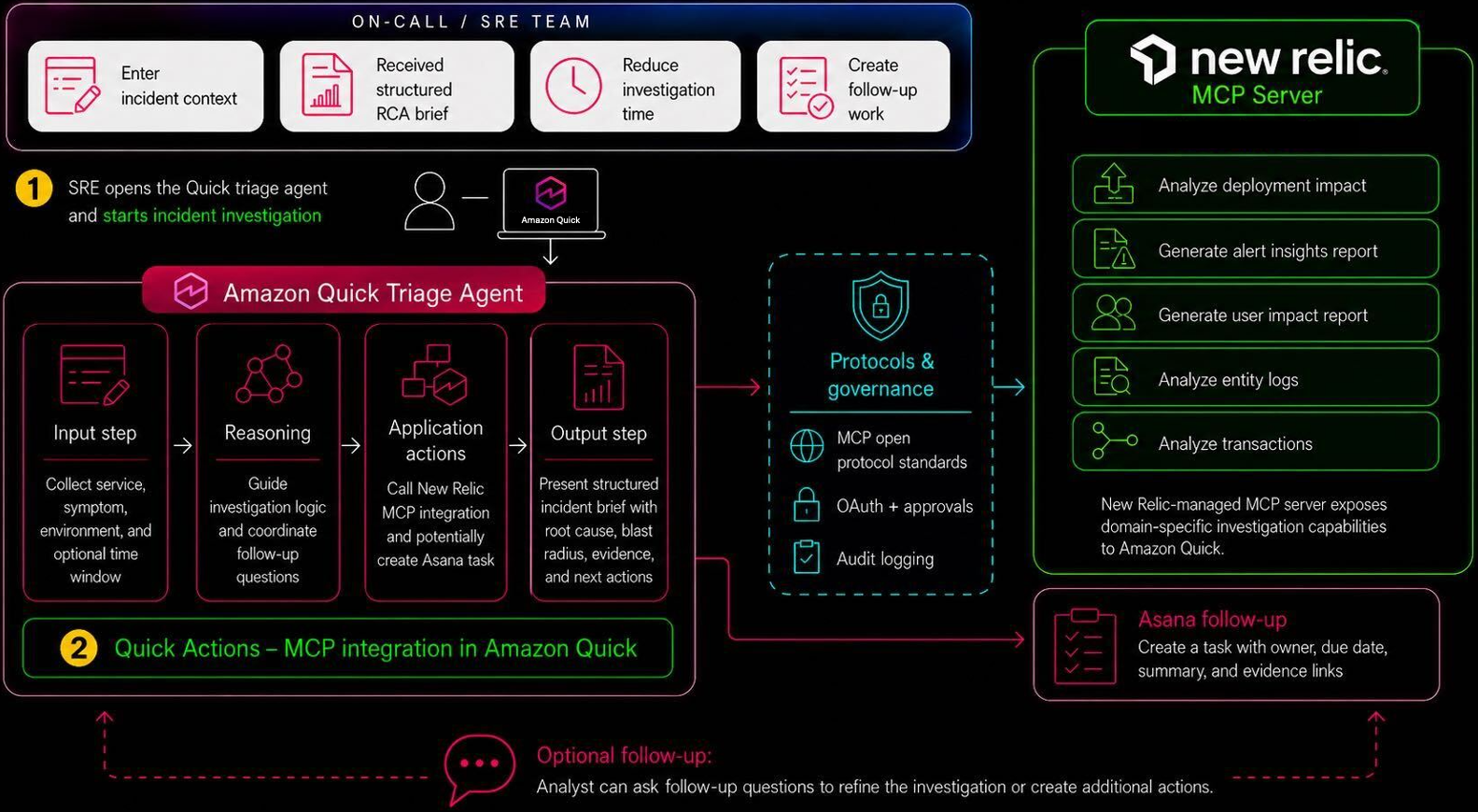
Amazon Quick and New Relic streamline incident triage by creating a custom assistant agent for faster resolution and reduced risk. The agent orchestrates investigation, root cause analysis, and task creation in a single prompt, improving mean time to resolution.
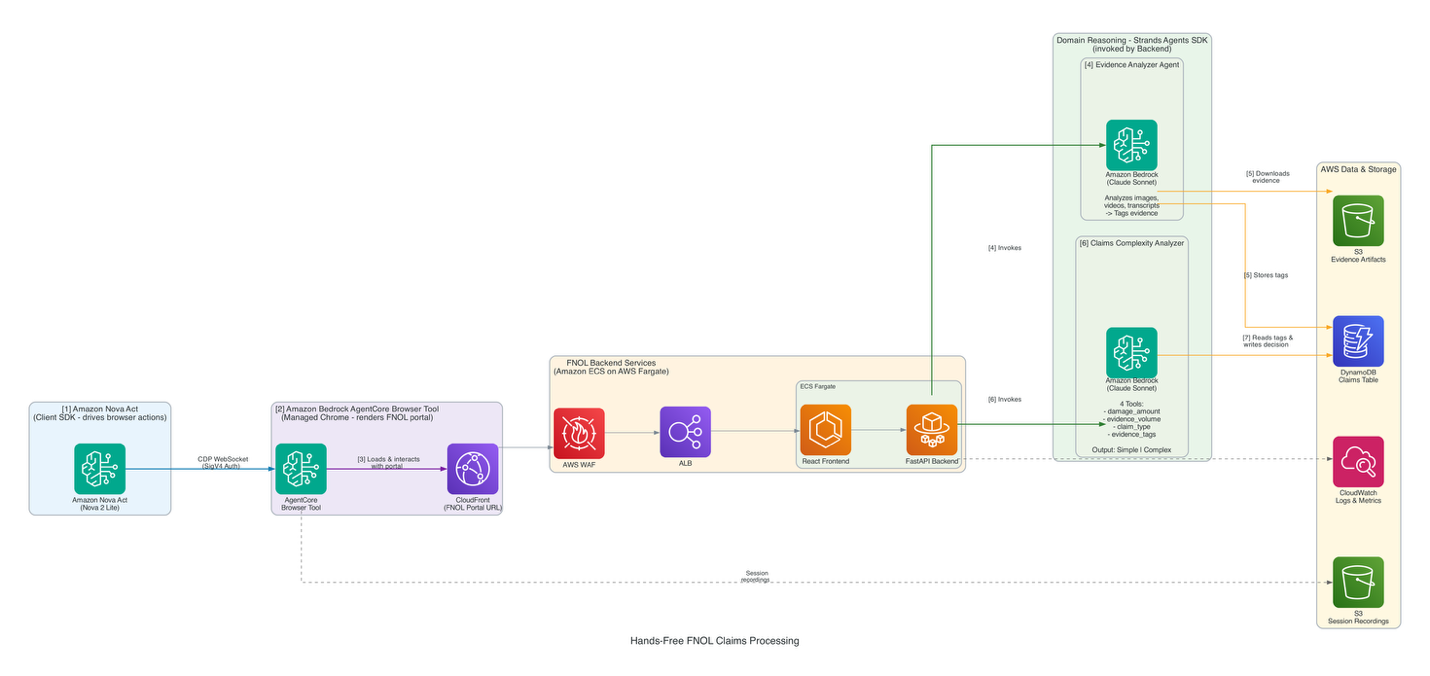
New technology streamlines FNOL intake for insurance adjusters, reducing repetitive tasks and improving efficiency. Hands-free system combines Strands Agents SDK and Amazon Bedrock for faster, more accurate claims processing.

Large language models like ChatGPT are increasingly used for news consumption. MIT study shows AI dependency paradox: users become worse at detecting misinformation without AI assistance.
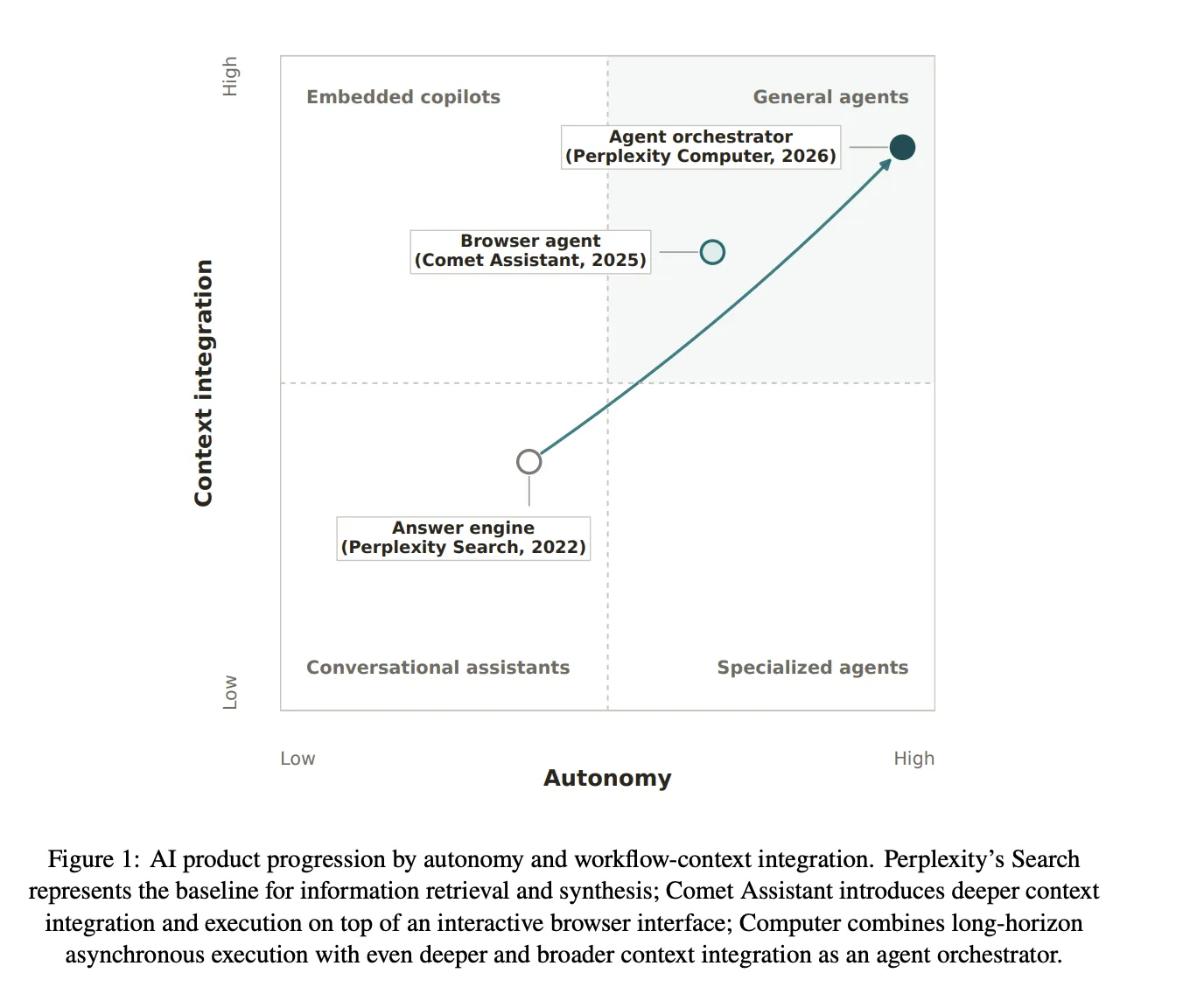
Perplexity and Harvard study shows AI agents like Search and Computer reshape knowledge work, increasing efficiency and autonomy. Computer executes tasks 48× faster than Search, with 55% less dissatisfaction and 87% time savings compared to a Search + Human approach.

NVIDIA CEO Jensen Huang visits South Korea, praising the nation's AI leadership and gaming community. Partnerships with LG, SK, Hyundai, Naver, and Doosan to advance AI infrastructure.
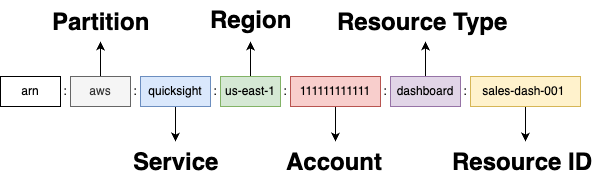
Amazon Quick administrators tackle permission issues with ARNs. Understanding ARN structure is crucial for scaling deployments across AWS accounts.
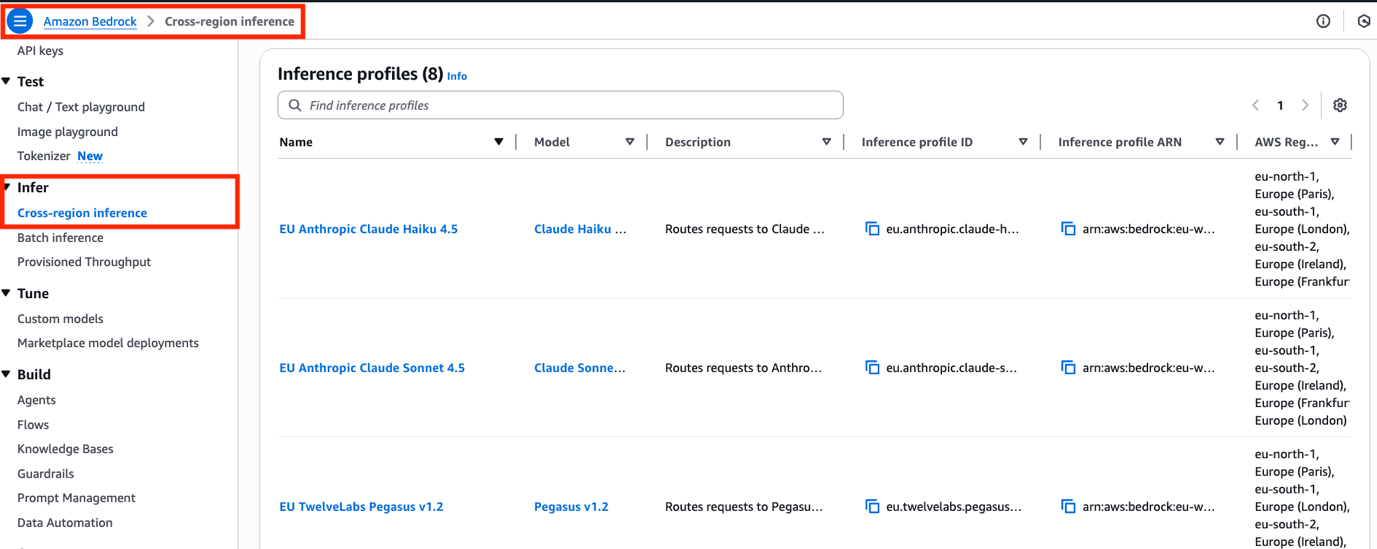
AWS introduces Cross-Region Inference (CRIS) on Amazon Bedrock, allowing customers to route generative AI requests across multiple AWS Regions, ensuring capacity and security. CRIS profiles optimize model throughput, offering global and EU geographic scopes to meet regulatory requirements and enhance application resilience.

NVIDIA and partners showcase U. K.'s AI progress at London Tech Week, with increased AI cloud deployments and Isambard-AI powering ambitious research and startups. U. K. government's Sovereign AI Fund supports homegrown companies like Ineffable Intelligence and NVIDIA Inception startups pushing AI boundaries.
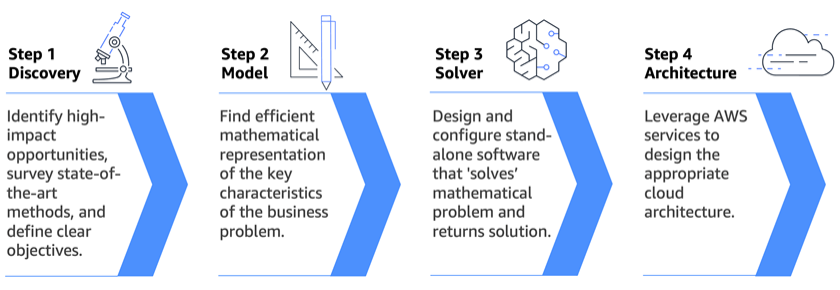
Leading organizations are turning to mathematical optimization to make optimal decisions in complex scenarios. AWS Generative AI Innovation Center offers scientific expertise to solve high-impact problems using AI and optimization, delivering measurable business outcomes.
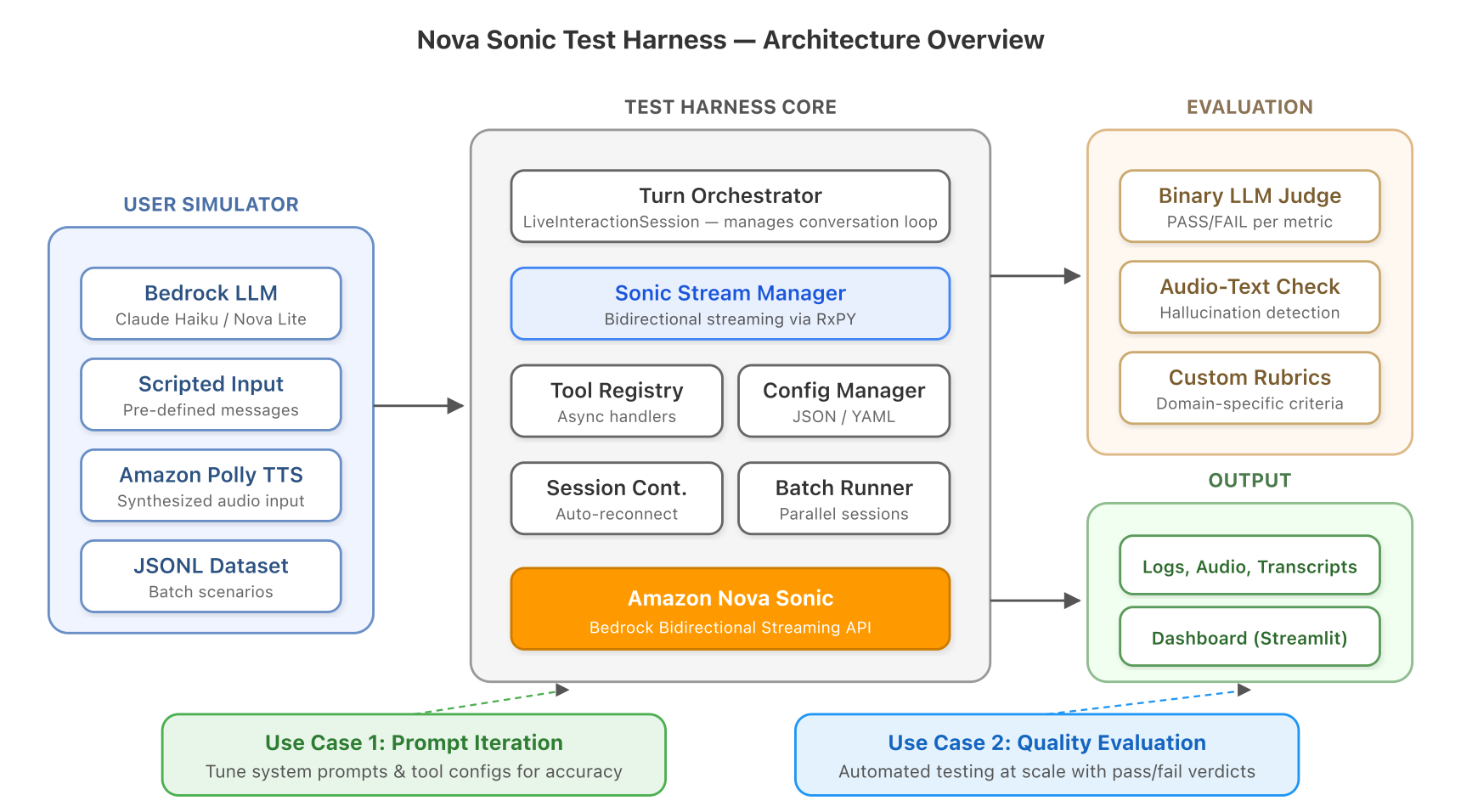
Voice agents are transforming customer interactions, but testing them poses challenges. Nova Sonic Test Harness offers a solution for rapid iteration and comprehensive evaluation of voice agent quality, without the need for manual testing. It addresses issues like bidirectional streaming, non-deterministic responses, and multi-turn context that make speech-to-speech testing fundamentally differ...
Machine learning regression techniques like Kernel Ridge Regression (KRR) and Support Vector Regression (SVR) are compared for predicting numeric values. A novel approach combining KRR and SVR results in a trimmed model with advantages of both techniques, demonstrated in a C# implementation.