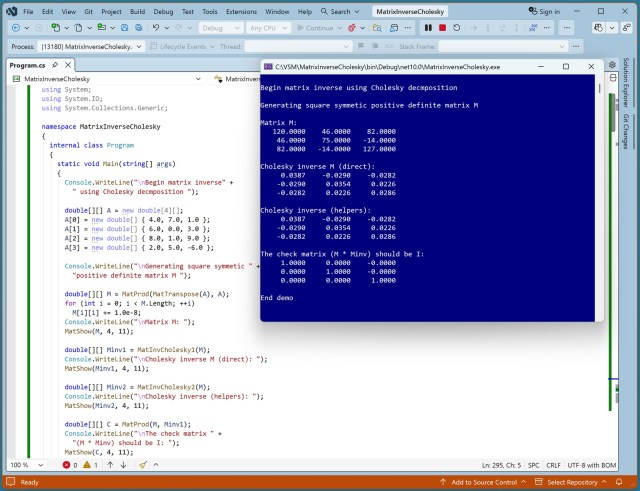
Designing a matrix inverse function using Cholesky decomposition: shorter code vs. more efficiency. Software engineering insights with AI-generated code and character design in animated films.
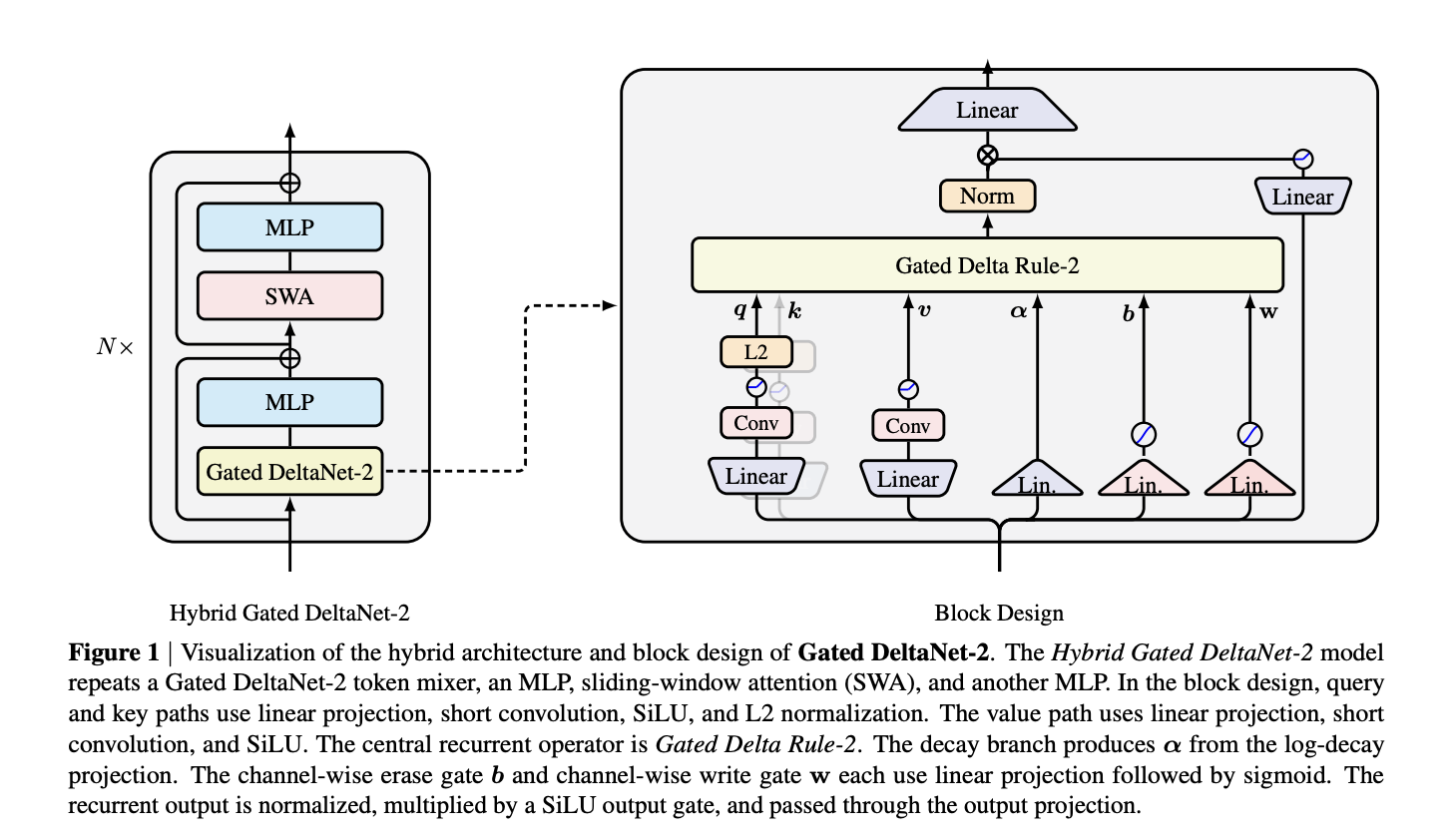
NVIDIA's Gated DeltaNet-2 introduces linear attention with two channel-wise gates, outperforming previous models in memory editing. Gated Delta Rule-2 separates key and value decisions, enhancing the delta-rule model's efficiency.
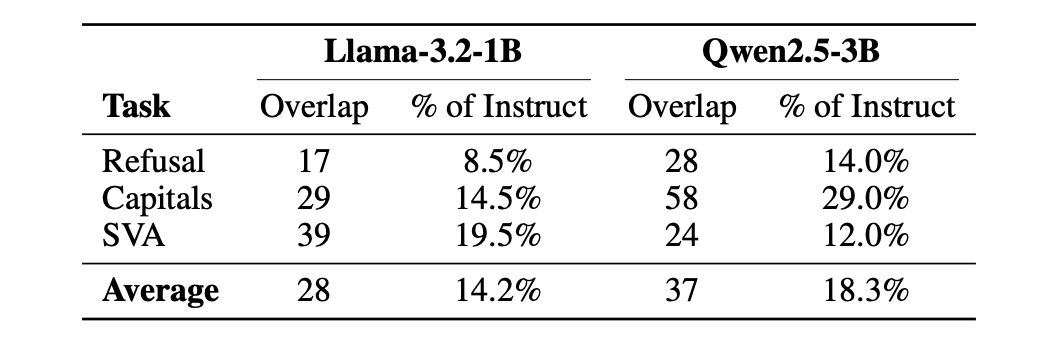
New research by the Nous team introduces CNA, pinpointing MLP neurons responsible for refusal gates in instruct models. Ablating just 0.1% of MLP activations reduces refusal rates by over 50% without compromising output quality.
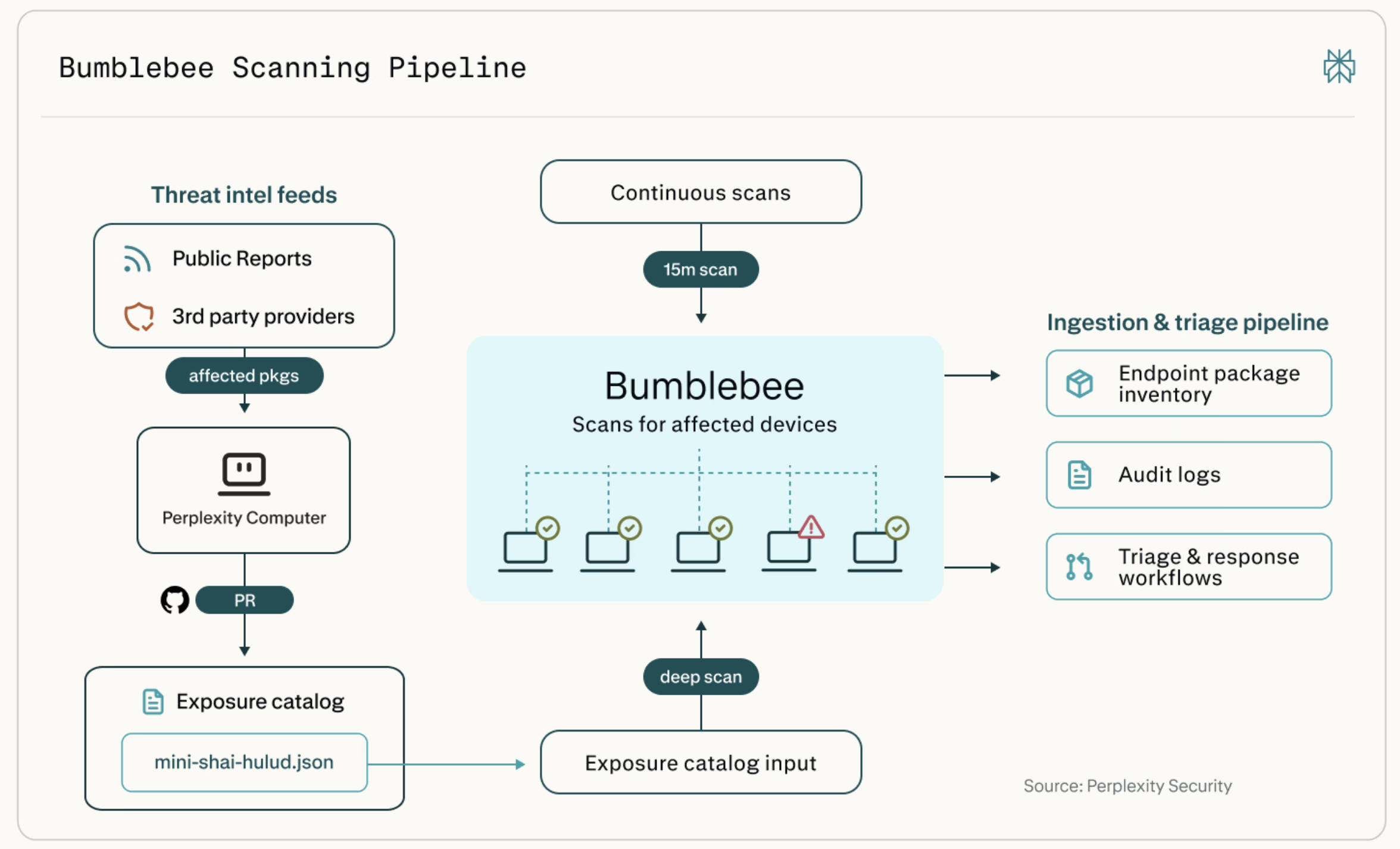
Perplexity's Bumblebee tool scans developer machines for vulnerable packages, extensions, and AI tool configs. It fills a gap in existing tools by checking local developer state for potential security risks.
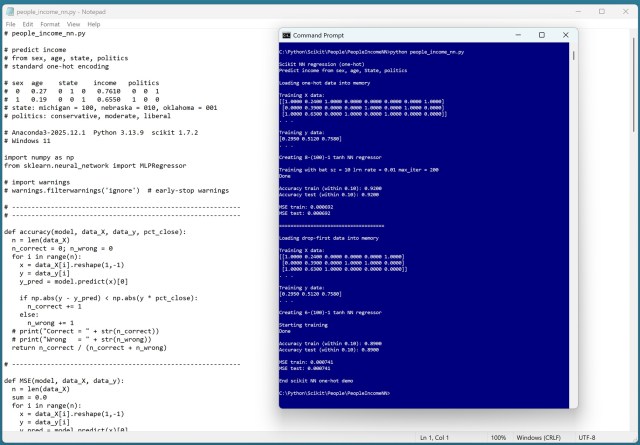
Use one-hot encoding for neural network regressors with categorical data; drop-first encoding is unnecessary and slightly less effective. Demo results show no reason to consider drop-first encoding for neural networks, confirming the advantage of one-hot encoding.
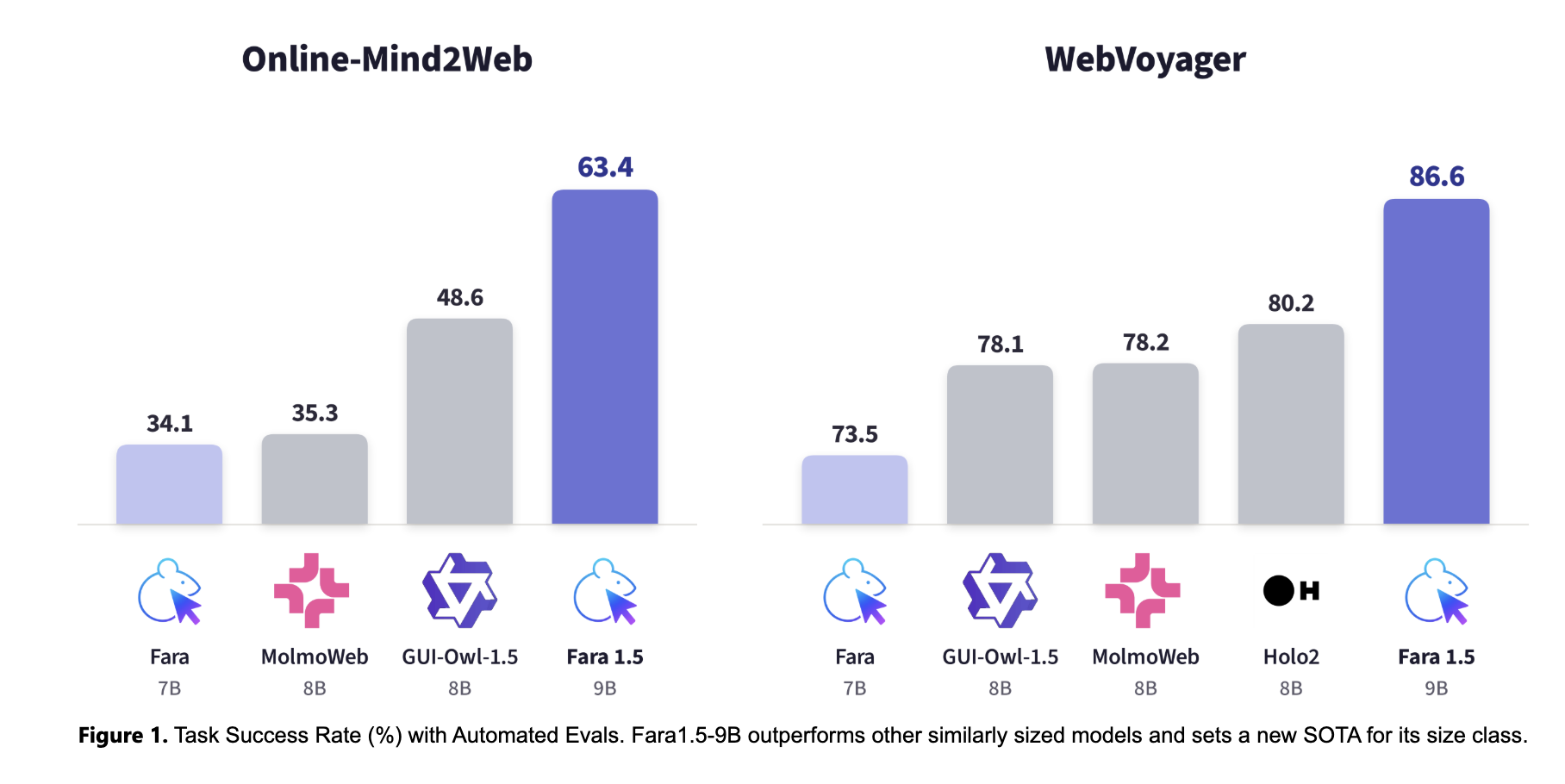
Microsoft Research's AI Frontiers lab released Fara1.5, a family of computer-use agent (CUA) models for the browser, integrated with MagenticLite. Fara1.5-27B achieves 72% task success on Online-Mind2Web, outperforming competitors like OpenAI's Operator and Google's Gemini 2.5 Computer Use.
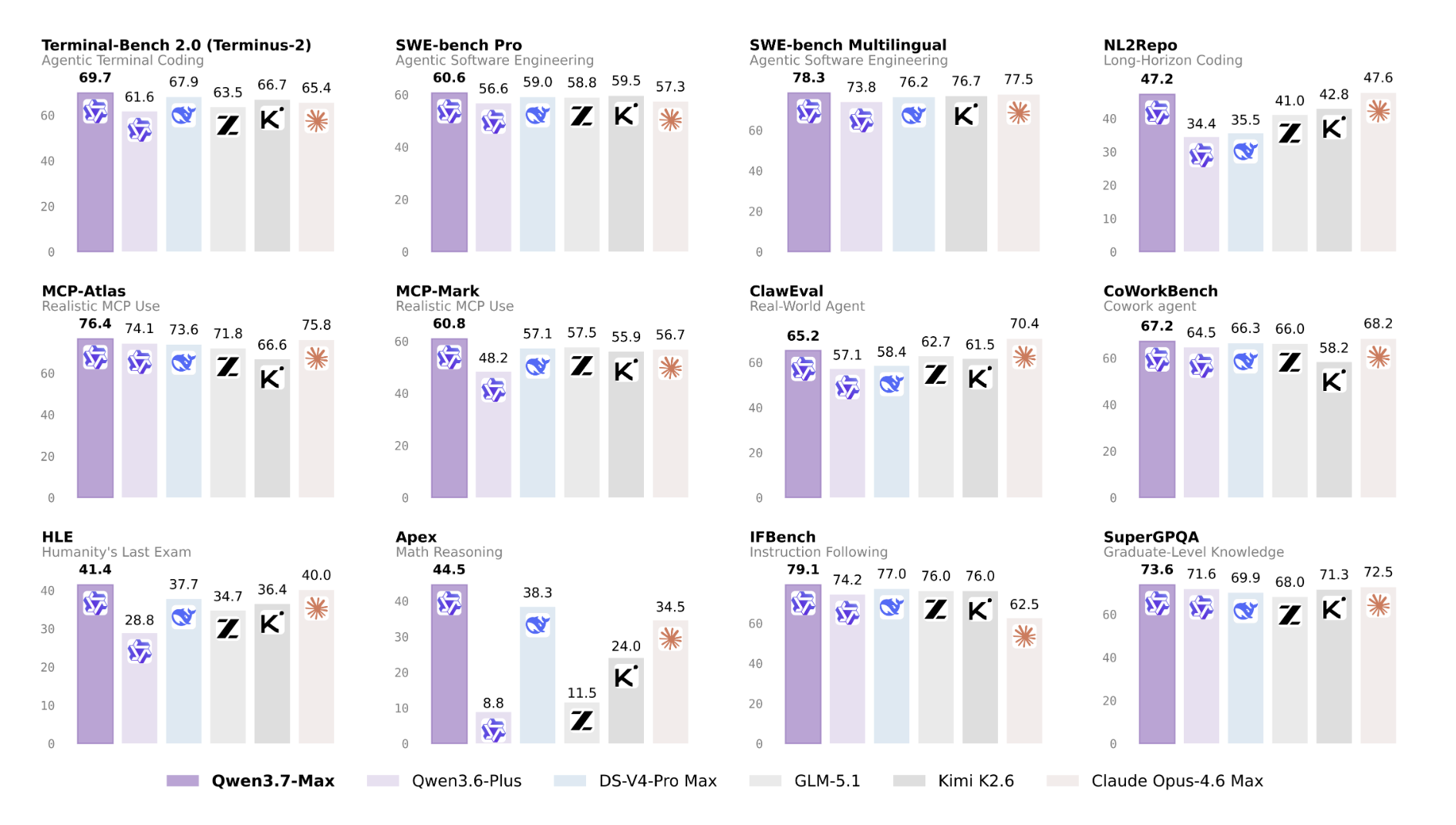
Alibaba unveils Qwen3.7-Max, a groundbreaking AI model designed for autonomous execution of complex tasks. Qwen3.7-Max features extended-thinking mode, a 1M token context window, and impressive reasoning capabilities, setting a new standard in AI technology.

Amazon Nova Act, now HIPAA eligible, automates healthcare workflows with AI agents, reducing manual tasks for HCLS organizations. It integrates with external tools, navigates websites, and completes multi-step workflows, improving efficiency and compliance.

CopilotKit transforms AI inside software from passive to active, with AG-UI bridging the gap between agents and users in applications. Major companies like Google and AWS embrace the protocol, signaling its maturity and production-readiness.
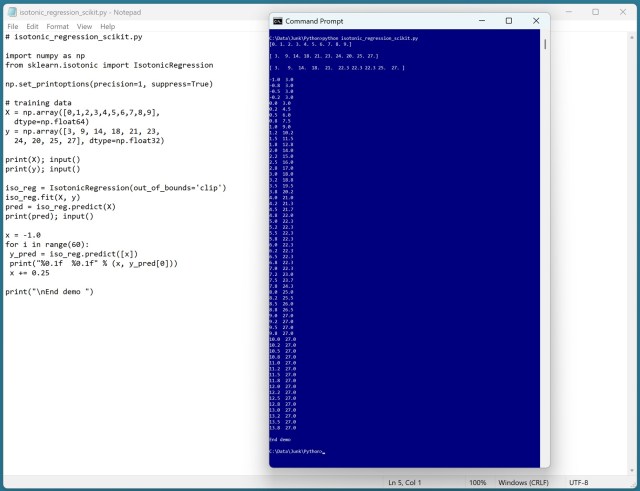
Isotonic regression is a complex ML technique. The author highlights misconceptions and showcases a demo using scikit-learn.
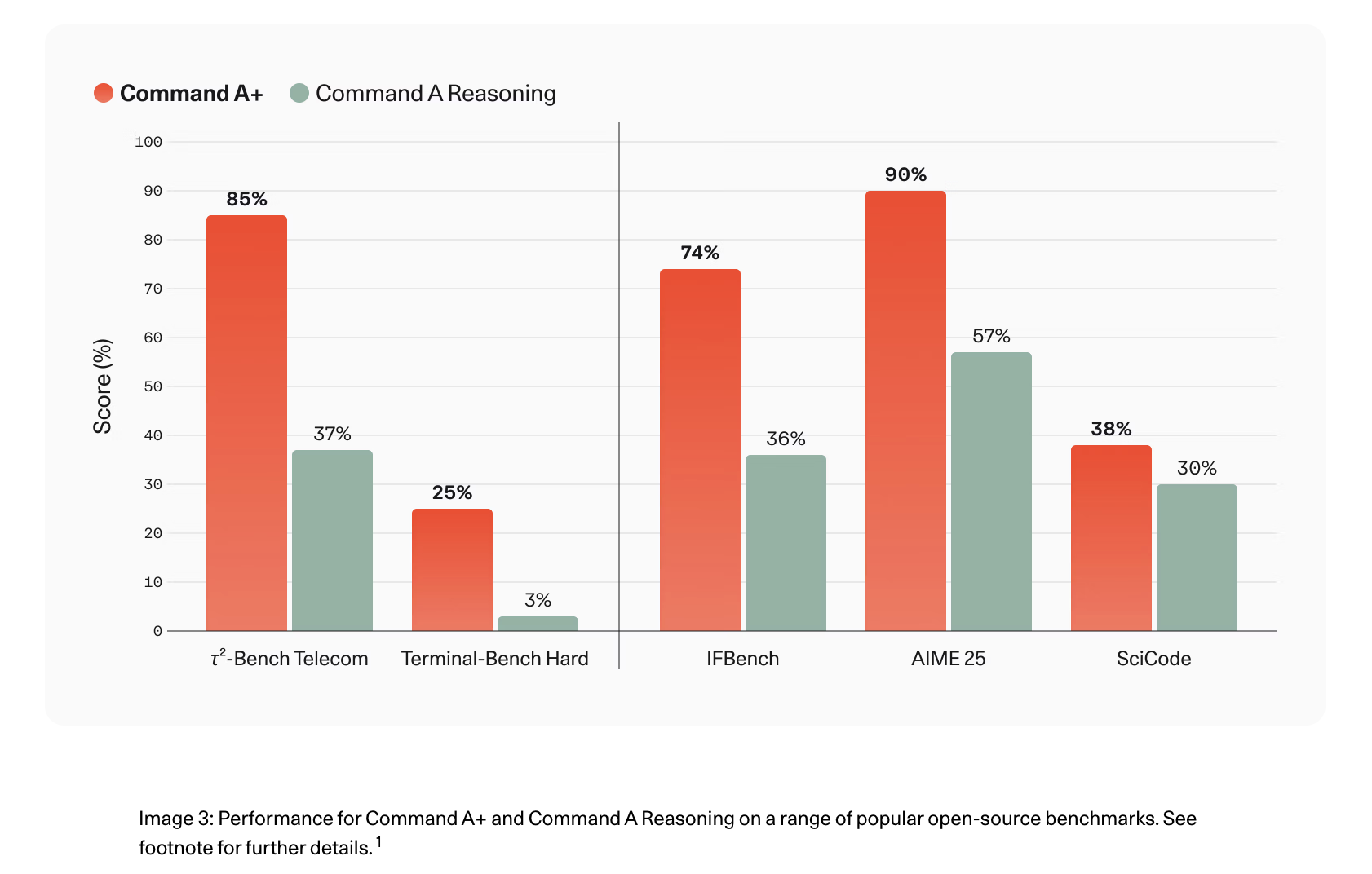
Cohere's Command A+ is an open-source MoE model optimized for high-performance agentic workflows, unifying capabilities from four prior models. It offers hardware-efficient quantization variants and significantly improves performance in agentic tasks, such as QA and coding.
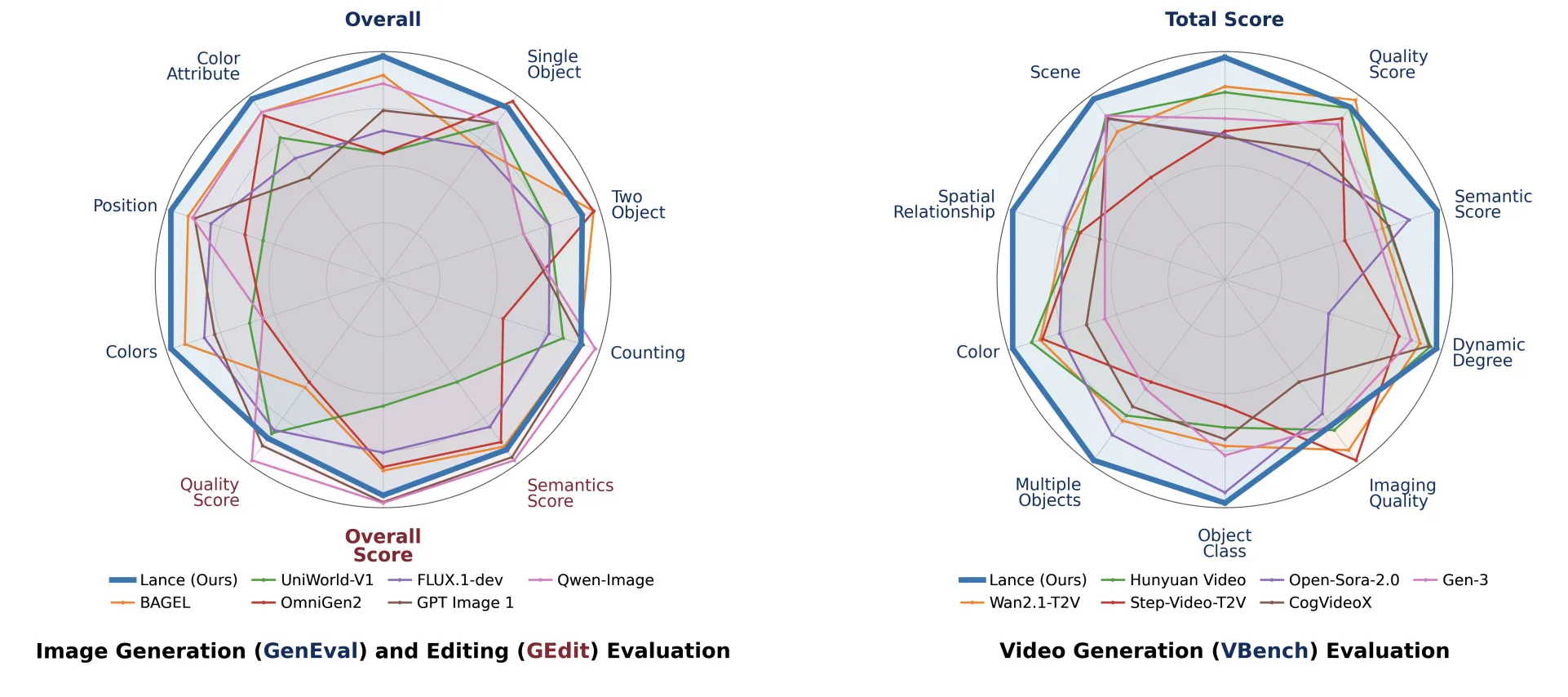
ByteDance's Lance model integrates image understanding and generation in one, bridging the gap between high-level semantics and low-level features. Lance's unified architecture handles tasks like image captioning, text-to-image generation, and video editing, setting a new standard in the image-video ecosystem.
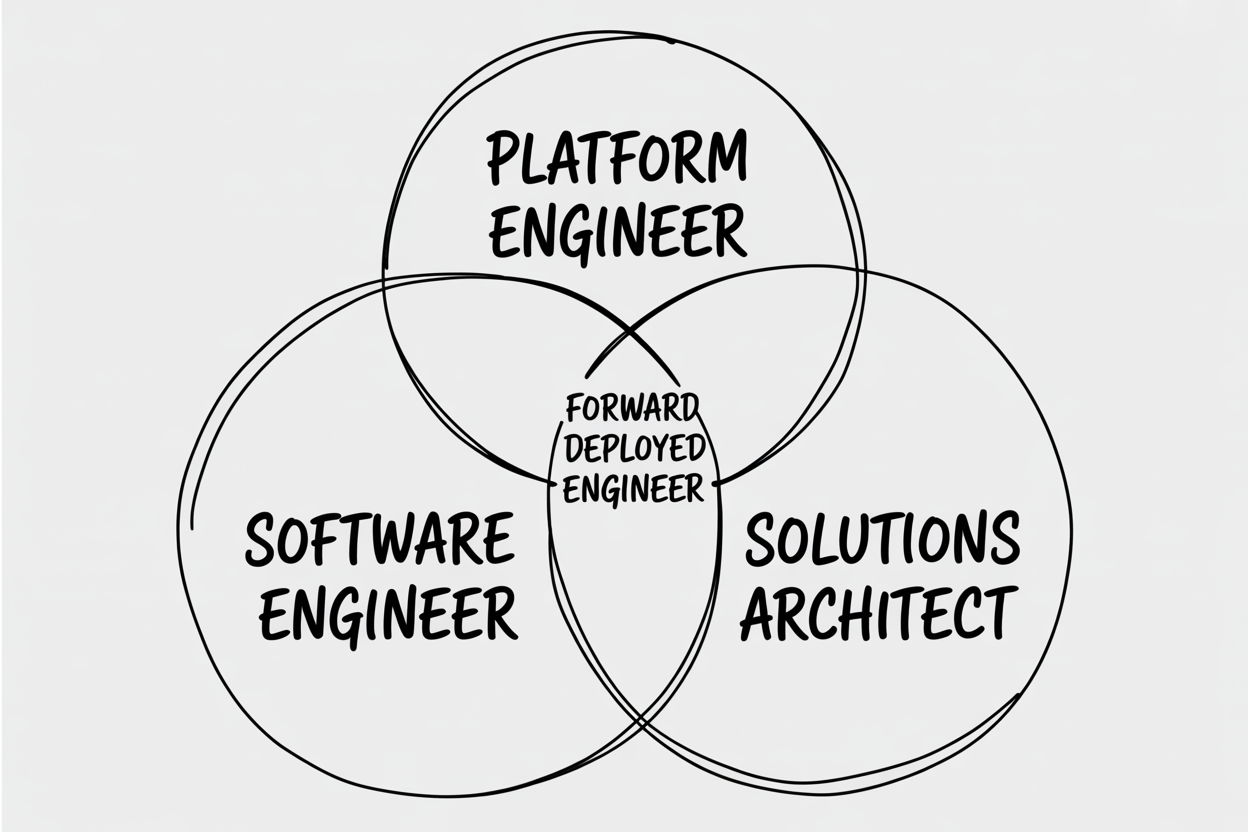
A Forward Deployed Engineer (FDE) works on-site with clients, writing code for production systems. Palantir's FDE model is crucial for complex AI deployments, where standard SaaS falls short.

Traditional radiology worklist systems create delays and increased costs by ignoring critical context, leading to suboptimal case assignments. By utilizing AI agents on Amazon Bedrock AgentCore, Radiology Partners aims to reduce diagnostic delays and improve workflow orchestration through intelligent, context-aware case assignment.

MIT study led by David Autor shows new forms of work benefit young, educated people in urban areas. Government investments drive innovation-based new work, creating opportunities for specialized knowledge.