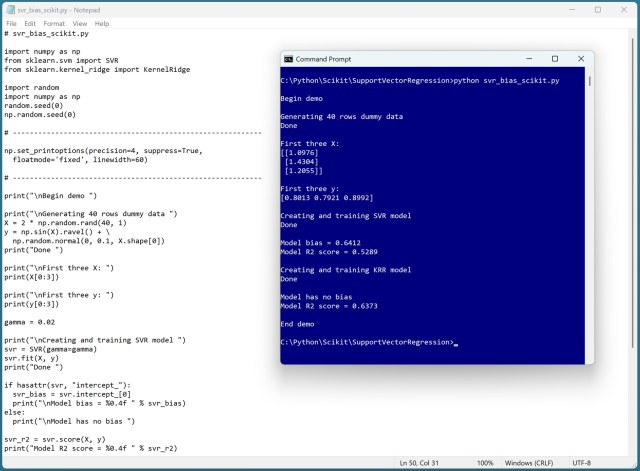
Kernel ridge regression models do not need a bias term, despite common misconceptions. AI-generated information can be misleading, so it's important to be cautious and question confidently presented data.
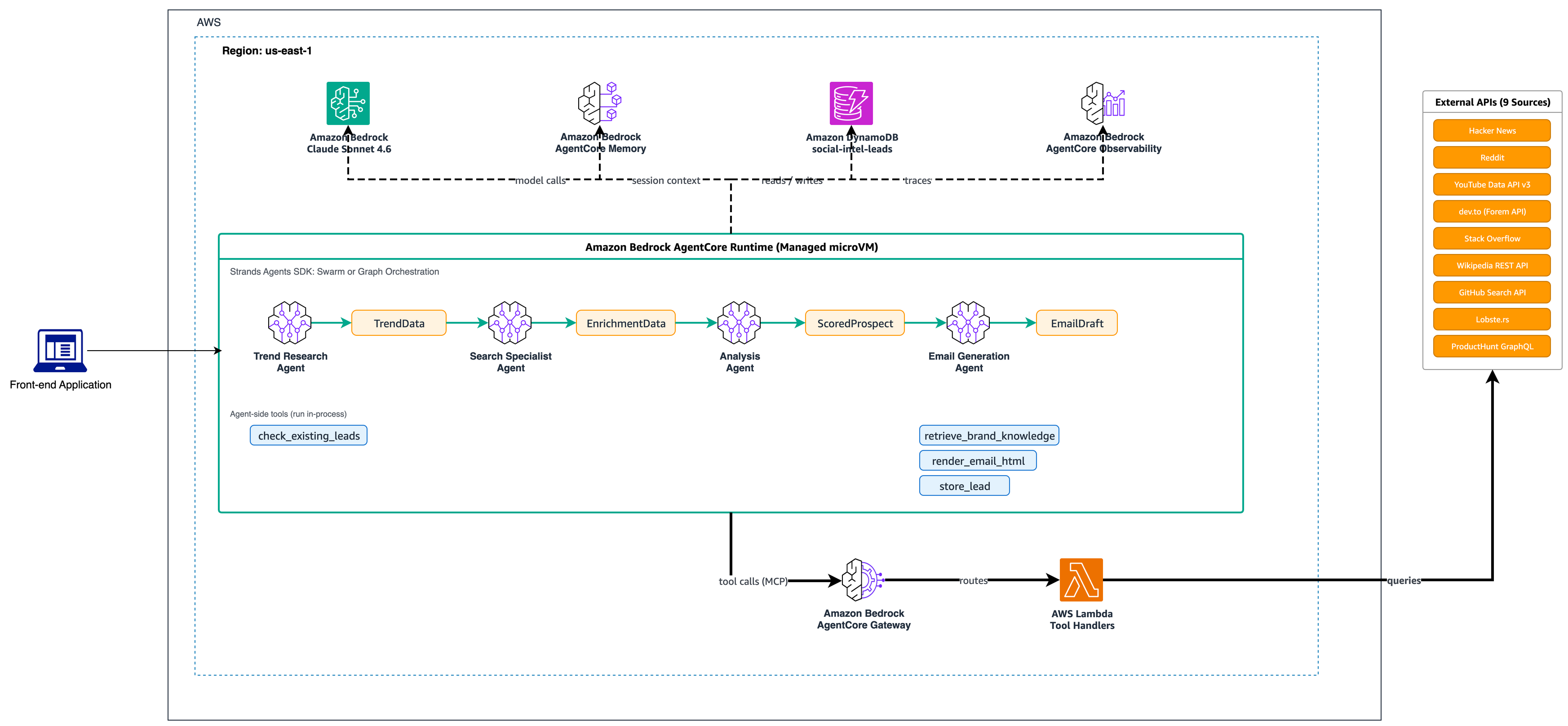
Thrad.ai leverages Strands Agents and Amazon Bedrock AgentCore to automate social intelligence for targeted advertising. Multi-agent orchestration identifies prospects across platforms, improving email quality and efficiency.
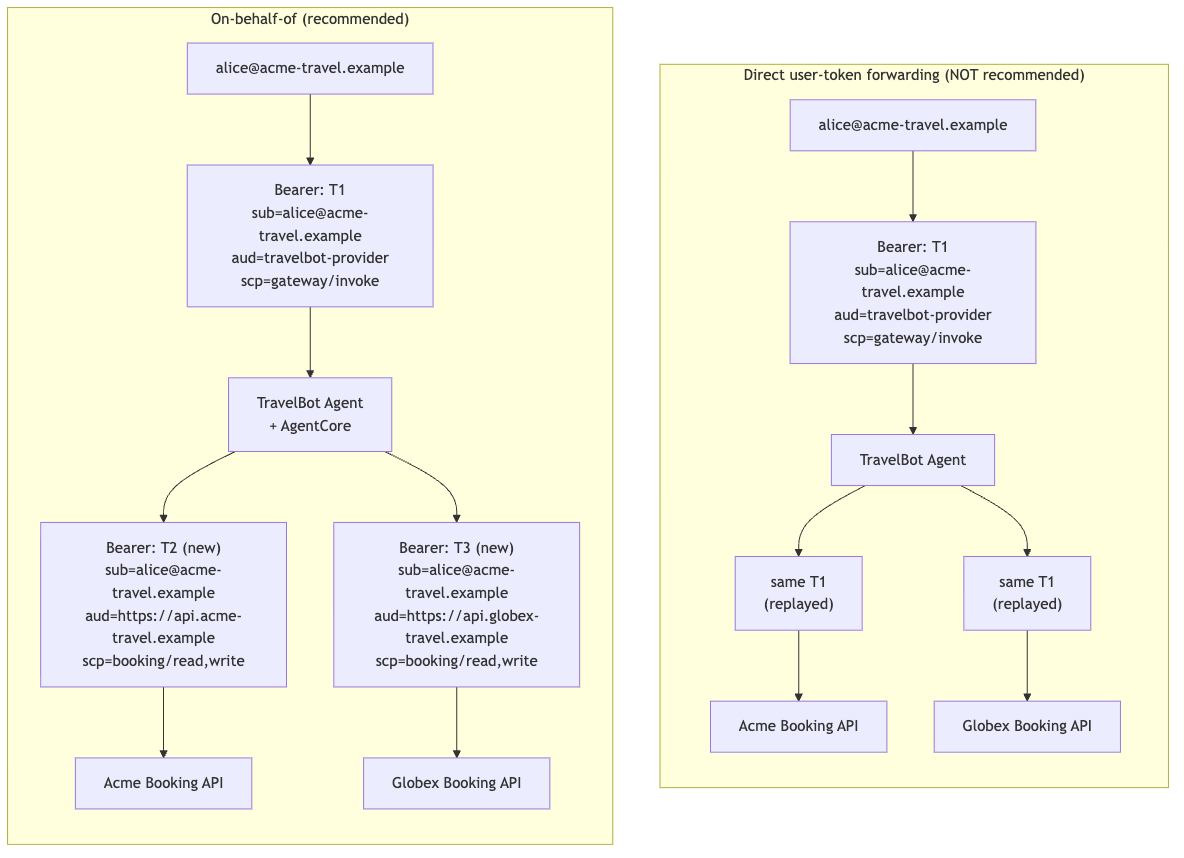
Amazon Bedrock AgentCore Identity supports OAuth 2.0 Token Exchange, solving identity challenges in multi-tenant AI systems. The OBO pattern ensures secure token exchange for agents serving multiple tenants, with a reference implementation available for testing.
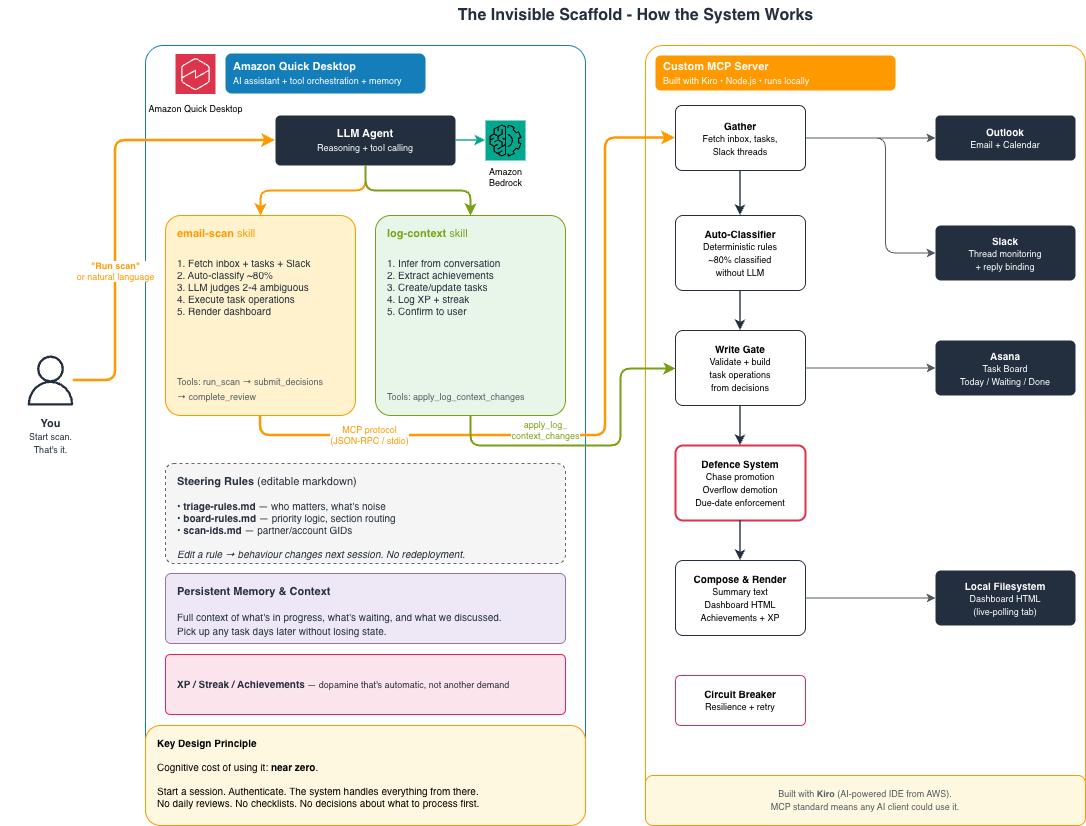
Neurodivergent solutions architect uses AI to build an accessibility tool compensating for executive function gaps. AI-powered workflow system helps maintain organizational systems for neurodivergent professionals.
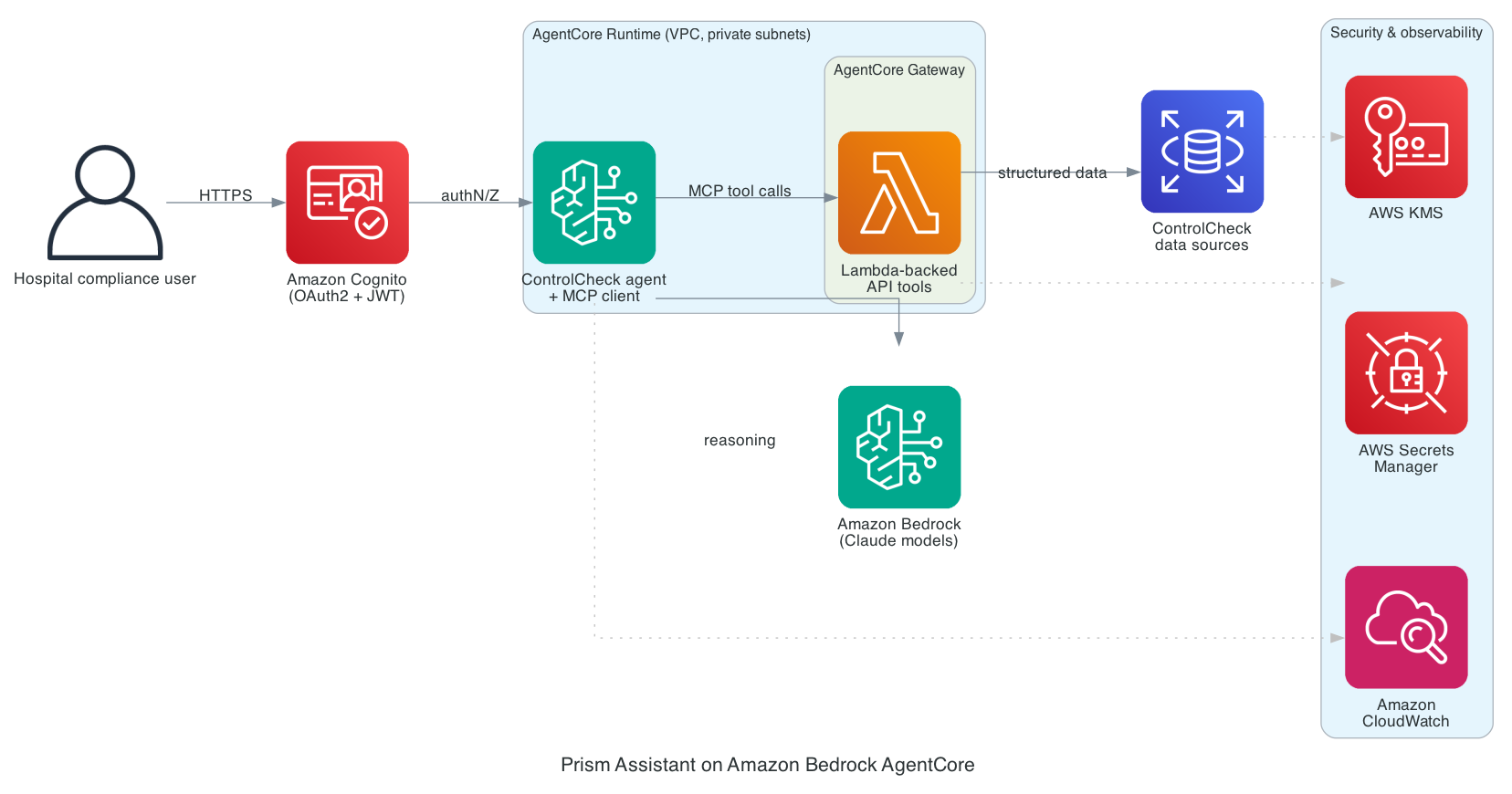
Bluesight tackles hospital compliance challenges with AI solution Prism, integrating multiple products into a unified system. Prism Assistant for ControlCheck launched in May 2026, streamlining drug diversion detection for 20 health systems.

MIT scientists, in collaboration with Thorn, developed an auditing approach to detect AI models specialized in producing harmful content like CSAM, with 100% accuracy. This breakthrough technique could help platforms flag and remove unsafe models, addressing a significant AI safety problem.

MIT Cybersecurity Clinic, founded in 2019, offers hands-on training to students while providing free cyberattack assessments to at-risk communities. Ransomware attacks on municipalities pose a growing threat, with over 40 assessments conducted so far.
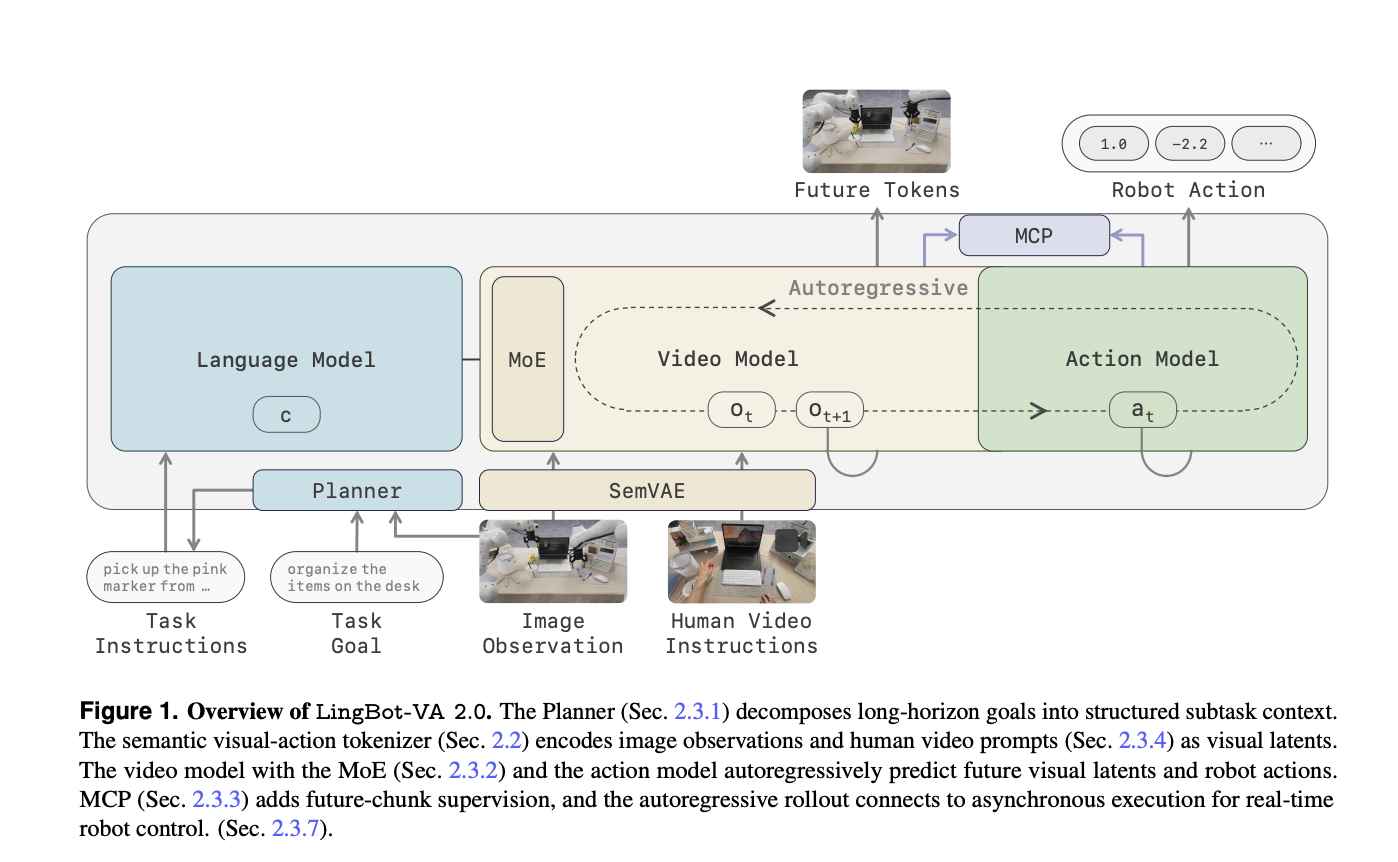
Robbyant's LingBot-VA 2.0 is the first embodied-native foundation model for generalist robot manipulation, pretraining the entire stack for embodiment. Version 2 introduces a causal DiT with a sparse MoE video stream, scaling asymmetrically with a dense FFN for action expertise.
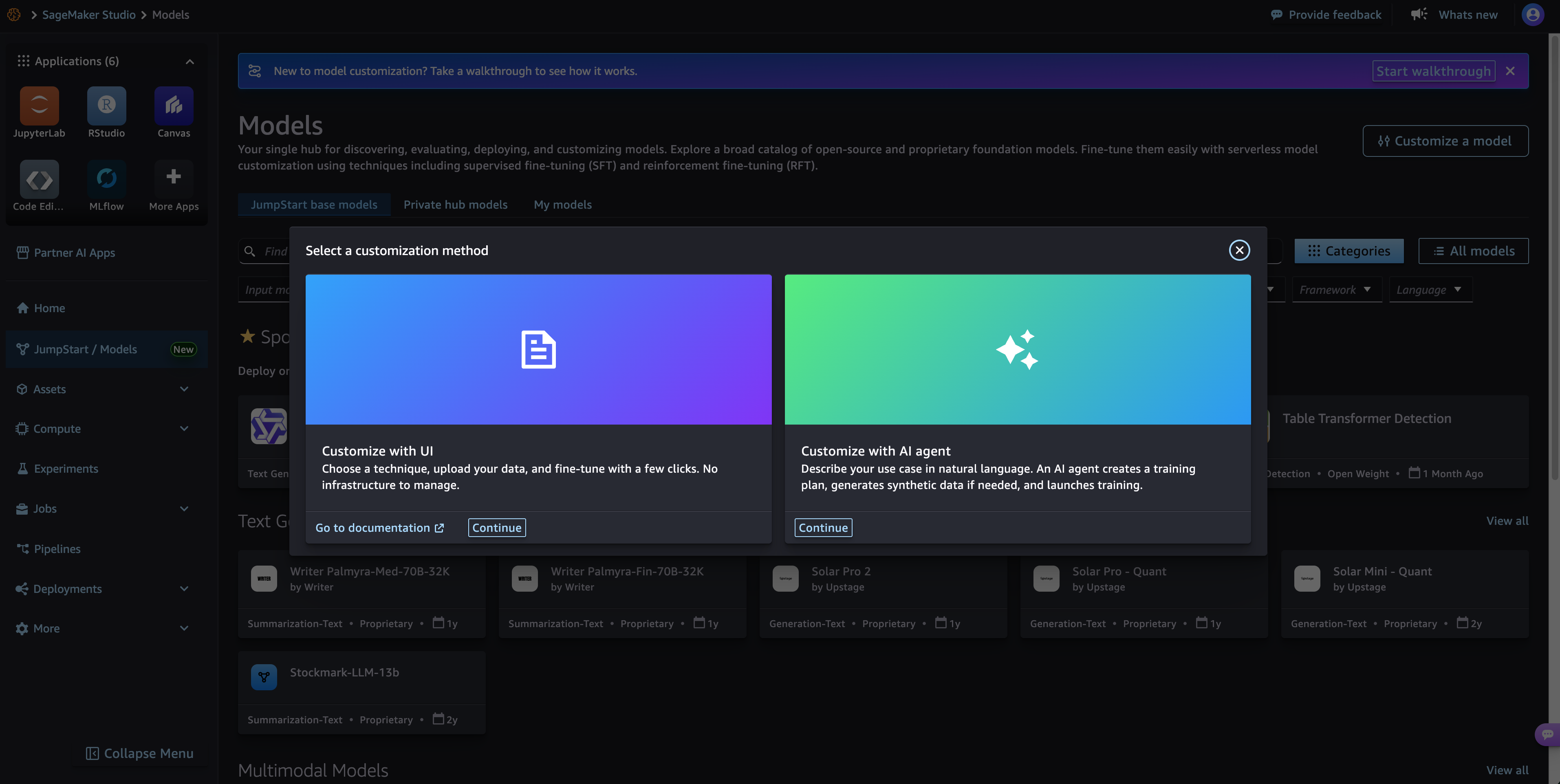
Model customization transforms general-purpose AI models into specialized enterprise assets by fine-tuning on domain-specific data. Amazon SageMaker AI offers serverless customization for NVIDIA Nemotron 3 models, delivering high performance and cost savings for organizations.
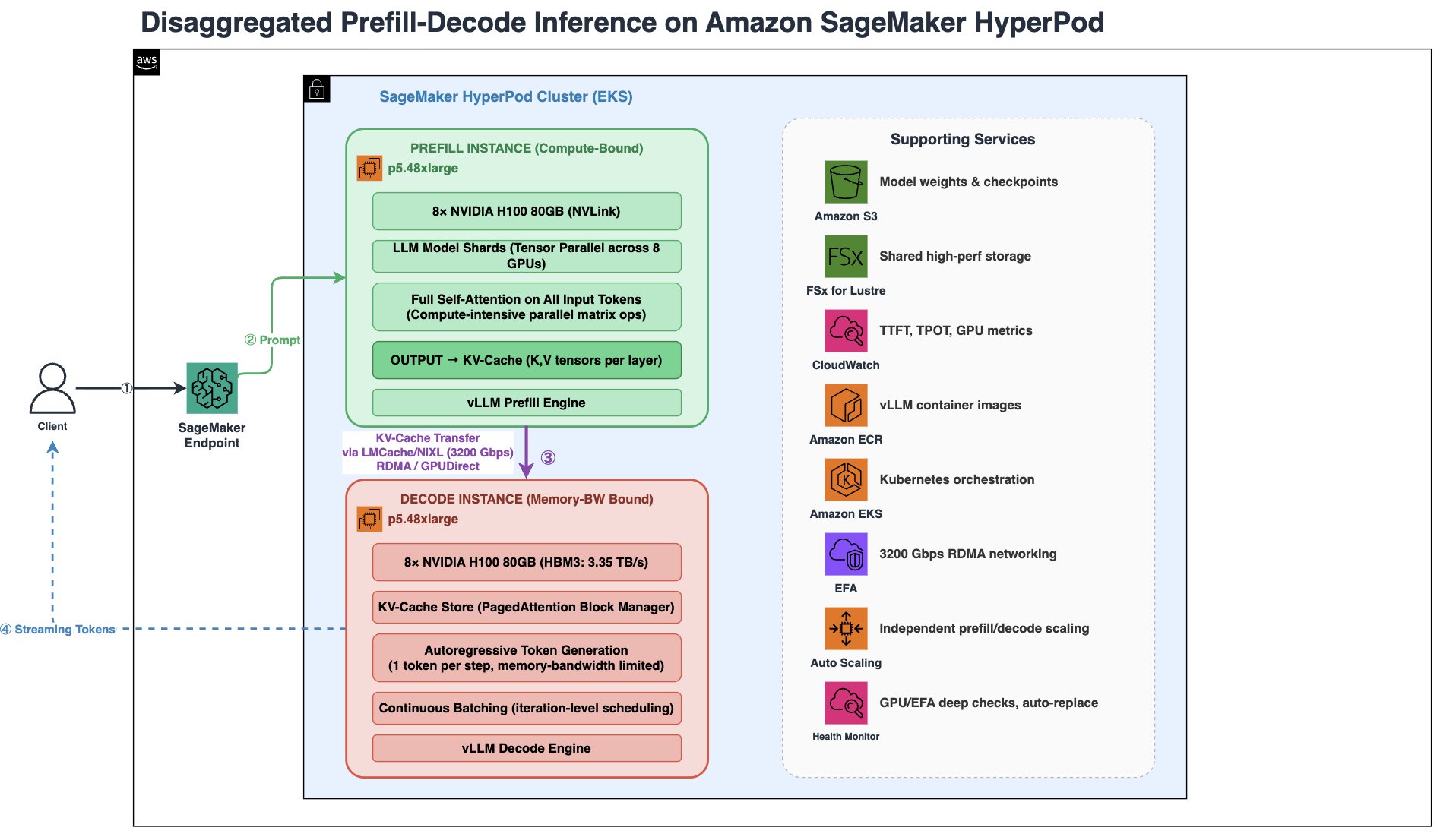
Disaggregated Prefill and Decode (DPD) on Amazon SageMaker HyperPod optimizes large language model (LLM) inference for high-concurrency workloads, improving efficiency and reducing latency spikes. DPD separates prefill and decode phases, utilizing specialized engines and EFA with RDMA to handle long prompts and multiple concurrent users effectively.
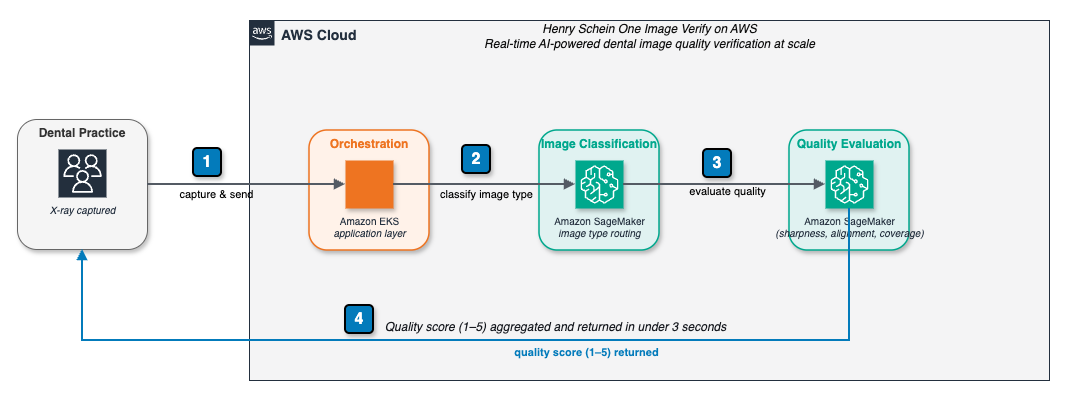
Henry Schein One's Image Verify uses AI to assess dental X-ray quality in real time, reducing insurance claim denials and improving workflow efficiency. The system, built on Amazon SageMaker AI, has processed over 11 million X-rays and is scaling to 40,000 locations globally.

Dynamic quantization by Unsloth reduces model size by 86% while maintaining accuracy, offering cost savings and deployment patterns on AWS infrastructure. Unsloth goes beyond uniform compression, analyzing layers for precision loss sensitivity and dynamically allocating bits for optimal performance.
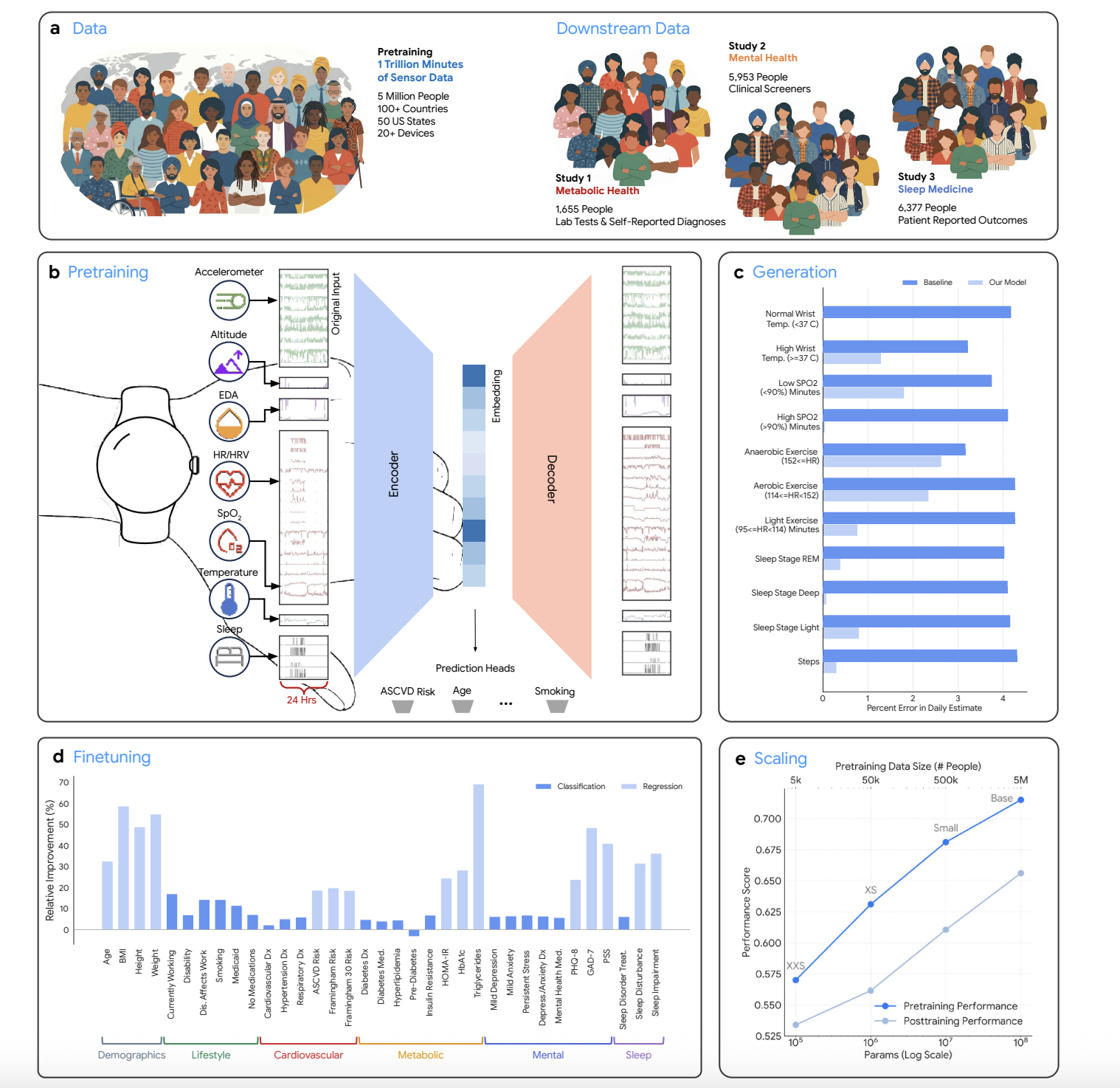
Google Research introduced SensorFM, a foundation model for wearable health trained on 1 trillion minutes of sensor data from 5 million people. SensorFM outperforms smaller variants on 35 health tasks, showcasing the importance of data volume in model performance.
Article: 'Support Vector Regression with SGD Training Using C#' in Microsoft Visual Studio Magazine explores kernel SVR demo with SSGD training. SVR predicts using RBF kernel function, removing irrelevant data during training to improve accuracy and scalability.

MIT researchers have developed "FloatForm," a system of robotic boats that self-assemble into structures on water, offering adaptive infrastructure possibilities. The project envisions a future where autonomous boats create bridges, platforms, and more on demand, expanding public space onto underutilized water surfaces.